一般的なソフトウエアであれば最初の1歩は Hello world が定番です。業界?によって違いがあり。マイコン業界では「Lチカ」、ディープラーニング業界では「MNIST」と。さしづめML(機械学習)業界?では「Iris」でしょうかね。今回はscikit-learn「内蔵」のIrisデータセットをのぞいてみます。
※「MLのお砂場」投稿順 index はこちら
scikit-learn「内蔵」のデータセット
ただお道具だけが提供されても習得ができないと、普及するようにならないので、scikit-learnの中の人も練習用のデータセットを準備してくれています。以下のユーザーガイドの目次を見ていくと
以下の項目に「トイ」データセットというものがあります。「トイ」というくらいだから「お遊び用」の「軽い」データセットに違いありませんでしょう。
上記「トイ」のカテゴリには、7個のデータセットが登録されており、そのうちの一つが Iris です。Iris plants dataset の説明から1箇所引用させていただくと、
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken from Fisher’s paper. Note that it’s the same as in R, but not as in the UCI Machine Learning Repository, which has two wrong data points.
famousだ、とありますね。知らないとモグリ的なやつです。書かれているとおり、R言語に含まれているのと同じだそうです。私は、遥か昔に、scikit-learnでも R でもない処理系の例題で Iris やった記憶があります。全部忘れてしまったけれど。
Irisデータセット
ここで、Iris は植物の御名前です。「アヤメ」です。3種類のアヤメの以下のデータからなるデータセットです。
-
- sepal 萼片(がく片) 長さと幅
- petal 花弁 長さと幅
花弁とかがく片とか、イマイチ分からないので調べてみました。
日本植物生理学会 > みんなのひろば > 花弁とがくの違いについて
上記を拝読させていただくと、専門家であればあるほど、難しい問題みたいです。まあありがちな。分かったような分からぬような。
なお、3種のアヤメのうち最初の一つだけに和名が見つけることができました。他は米国での別名?でしょうかが検索に引っかかります。
-
- Iris-Setosa ヒオウギアヤメ
- Iris-Versicolour ”Blue iris”ともいうみたい
- Iris-Virginica ”Virginia iris”ともいうみたい
sklearnの Iris データセットの説明は以下にあります。
まずはデータをJupyter-notebookにロード
データをロードした後、まずはロードしたデータの「型」から調べてみます。
見たことの内型が現れてきました。sklearn内部で定義されている Bunch 型とな。それは何?sklearnのWebサイトを検索すれば以下のドキュメントを見つけることができます。
上記を読むとPythonの普通の辞書型の拡張(継承)みたいです。普通の辞書型の機能に加え、
bunch.value_key
という形でアトリビュートを使ったアクセスも可能になっているようです。であれば、まずは普通の辞書型のつもりで、キーとその中のデータの型をダンプしてみます。
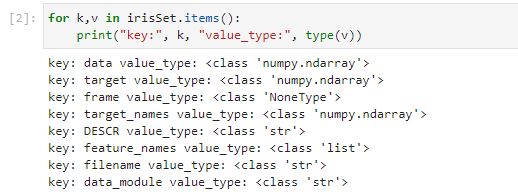
8つもデータ構造が入ってました。データのキー名からすると DESCRというキーの項目は「デスクリプション」ではないかしらん。
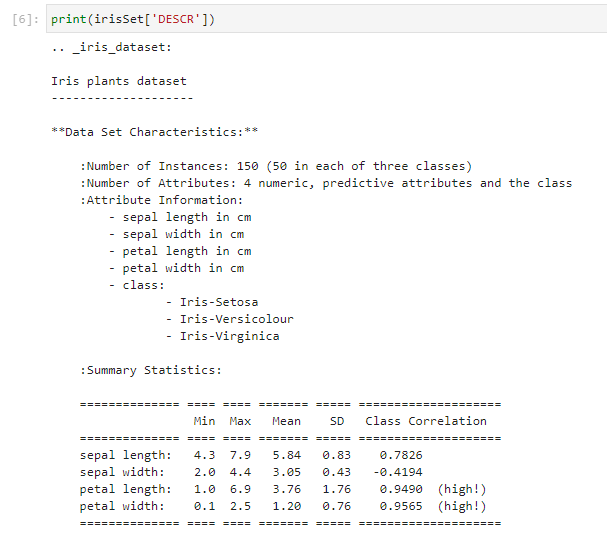 上記の後にもかなり長い説明が続きます。確かに「デスクリプション」ではあったのですが、内容的には、Web上の説明ページと同様な内容でした。
上記の後にもかなり長い説明が続きます。確かに「デスクリプション」ではあったのですが、内容的には、Web上の説明ページと同様な内容でした。
データ本体(表示しているのは先頭部分)をみてみると以下のようです。がくの長さと幅、花弁の長さと幅の4点のデータを組にしたものがならんでいるようです。
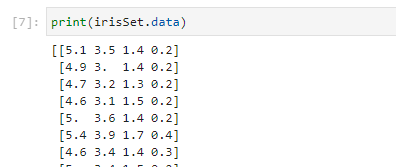
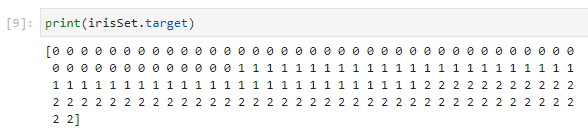
Targetとあるデータをみると、それぞれのデータが0,1,2と分類できるようです。この分類は種でしょうね。
他のデータキーをチェックするとこんな感じ。
データセットの内部については、大体分かった感じ。ホントか?
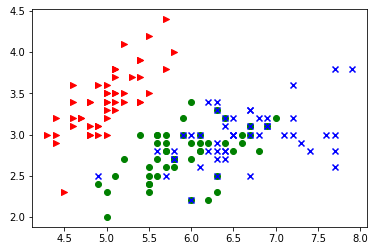
グラフにしてみる
Irisデータセットを扱っている例はあちこちに見つかるのですが、手元にあった以下文献のサンプルコードで「可視化」してみました。
「実践 機械学習システム」Willi Richert & Luis Pedro Coelho著 斎藤訳 オライリー・ジャパン
ちょっと古いようで、サンプルコードそのままでは、手元のPython3では走らなかったです。1箇所修正してあります。データセットの中身を調べたので、何を可視化しているのかは分かる、と。
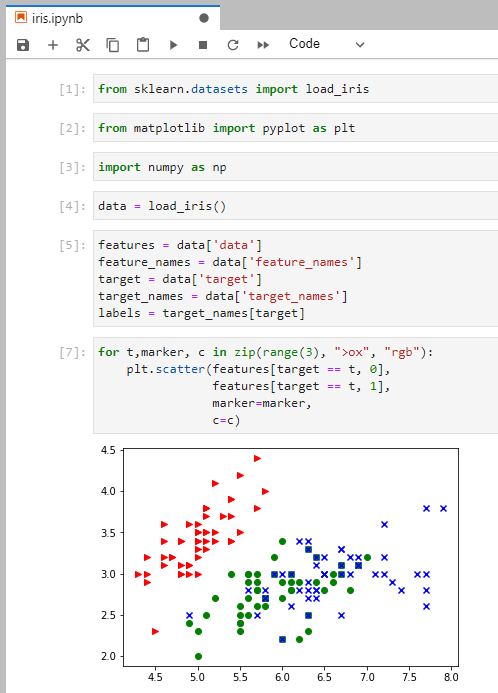
データセットの素性が分かったところで、次は「分類」をやってみますか。Hello worldの第1歩。