今回はQueueを使ってみたいと思います。第34回で似たお名前のEventQueueというものを使ってみましたが、全く異なるものです。QueueはスレッドやISR間の通信のための仕組みで、EventQueueはノンプリエンプティブな制御権の移動の仕組みです。「よくある」Queueだと思ってやってみたのだけれど疑問あり。何故?
※「モダンOSのお砂場」投稿順Indexはこちら
※実験コードのビルドは、Arm社のWeb開発環境 Mbed Compilerを使わせていただいております。登録すればインストールせずに即使える開発環境です。実機ターゲットは、ST Microelectronics社のNucleo-F401REボード(STM32F401REマイコン搭載。コアは Arm Cortex M4F)です。
Queue
Arm Mbed OS6のQueueは、並行に走っている複数スレッド(Mbed OSではタスクでなくスレッドと呼びますです)間で通信するための仕組みです。Queueの一方の端から入れた情報が、他端から、基本は先入れ先出し方式で取り出すことができます(プライオリティ制御も可能とな。使ってみてないケド。)Mbed OS6には、似た機能のAPIにMail (BOX)という仕組みもあるようです。通信の実体メッセージまで格納することができるMailの仕組みと比べると、Queueは、実体メッセージの置き場所は管理してくれず、ポインタのみの格納です。通常はメモリをアロケートするような仕組みと組わせて使うみたいです(今回は「静的」にやっつけてしまいましたが。)
以下がMbed 公式の Queueに関するドキュメントのページです。
※疑問があるのよ。
キューにデータを出し入れするコードを書くのにドキュメントを読み、以下のように認識しました。
-
- exampleコードでは、put() / get() を使っている
- しかしAPIドキュメントを見ると put() / get() 以外に try_put() / try_get() などのtry_からはじまるメソッド群がある。こちらの方が使い易そうに見える。
- また、以下のヘッダファイルの定義をみると put() / get() は推奨されていない印象を受ける。try_系を使う方が良いように思える。
上記のヘッダファイルから1箇所引用させていただくと、以下のようです。
MBED_DEPRECATED_SINCE(“mbed-os-6.0.0”, “Replaced with try_put and try_put_for. In future put will be an untimed blocking call.”)
しかし、try_put()使ってみたら、そんなメソッド知らない、と言われてしまいました。エラー。Mbed OSのリビジョンを確認してみましたが、現行の最新版である筈のv6.15でした。何故にtry_チョメチョメが使えない?未だに不明です。
しかたないので、以下のコードは、旧式?の put() / get() で書いてます。
実験用のコード
実験は以下のようです。
-
- タスク1は、疑似乱数で10から2550までの10の倍数を生成する。QUEUEを調べてフルでなければ、生成した数をQUEUEにput()する。put()した数字は標準出力に報告する。QUEUEにput出来ても出来なくても生成した数字ミリ秒だけ待つ。ランダムな間隔でputとその表示が起こる。
- タスク2は、毎10ミリ秒毎にQUEUEをチェックし、QUEUEが空でなければQUEUEからデータを取り出す。getした数字を標準出力に報告する。
- main()関数は、上記2つのタスクを起動後、無関係にLチカしつづける。
#include "mbed.h"
#include "platform/mbed_thread.h"
#include "stdlib.h"
#define BLINKING_RATE_MS (500)
#define QUEUE_DEPTH (8)
Queue<int, QUEUE_DEPTH> qu;
int dataBuffer[QUEUE_DEPTH];
int dataIdx;
Thread t1;
Thread t2;
void t1_thread()
{
int waitMS;
while (true) {
waitMS = (rand() & 0xFF) * 10;
dataBuffer[dataIdx] = waitMS;
if (!qu.full()) {
qu.put(&(dataBuffer[dataIdx]));
printf("Put: %d\r\n",dataBuffer[dataIdx]);
}
dataIdx = dataIdx < (QUEUE_DEPTH - 1) ? dataIdx + 1 : 0;
ThisThread::sleep_for(waitMS);
}
}
void t2_thread()
{
while (true) {
if (!qu.empty()) {
osEvent evt = qu.get();
int *mess = (int *)evt.value.p;
printf("Get: %d\r\n",*mess);
}
ThisThread::sleep_for(10);
}
}
int main()
{
printf("\r\n\r\n*** Queue Sample ***\r\n");
dataIdx = 0;
DigitalOut led(LED1);
t1.start(t1_thread);
t2.start(t2_thread);
while (true) {
led = !led;
thread_sleep_for(BLINKING_RATE_MS);
}
}
ビルド結果
上記コードのMbed Compilerによるビルド結果は以下のようです。
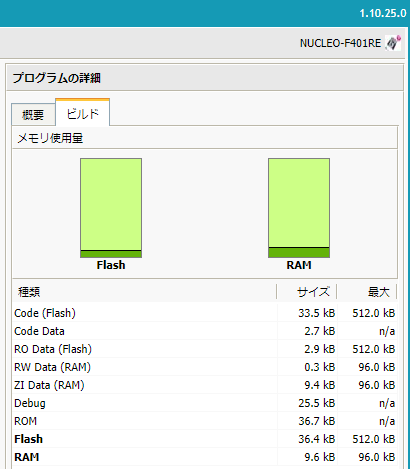
ここでも、ちょっとムムムな感じ。
第39回、第40回と、Mbed OS6のオブジェクトを生成してますが、それらの回では「あまっているRAMはだいたい」ZI Dataで埋まっているように見えてました。しかし、今回はそういう感じはないです。こちらの方が普通な感じではあるのだけれど、使うAPIによってメモリの使い方が大きく異なる理由が知りたい!
ま、ビルドそのものは成功し、オブジェクトが得られたので、Nucleo-F401REに書き込んで動かしてみます。
実機動作結果
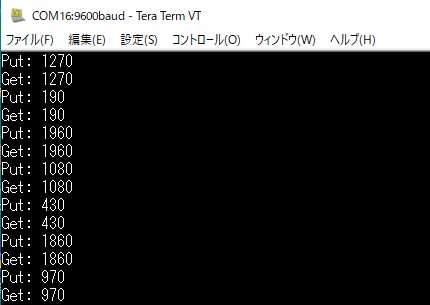
冒頭のアイキャッチ画像に、Nucleo-F401REの標準出力に接続した仮想端末の様子を掲げました。乱数で生成されたと思われる10ms単位の数字をPut して Get して期待どおりの挙動であります。
しかし、なんだかな~ 釈然としないのう。