Armは64ビット化するときに32ビットであった「余計なもの」を捨ててます。しかしレジスタをシフトしてから演算という命令は捨てなかったです。アドレス計算などに便利なようでいて、実はそれほど頻繁に使う分けでもない命令(個人の感想です。)RISC-Vなどは持ってない類。もはやArmの伝統といっても良い機能かと。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
Armのレジスタ間の加算命令の場合、第2オペランドと第3オペランドを加算して第1オペランドに代入するのですが、第3オペランドについてはシフトとシフト量という指定をすることができます。シフトは
-
- 左論理シフト LSL
- 右論理シフト LSR
- 右算術シフト ASR
とフル装備です。シフト量についても6ビット幅で指定可能なので64ビットまでの第3オペランドレジスタをいかようにもシフト可能です。
なかなか便利に見えますが、実装上は1命令でバレルシフタを通してから演算してキャリーチェーンを通過させないとならないので物理的な遅延を考えると不利じゃないかと思います。オペランドをシフトしてから演算というシーケンスはシフト命令と演算命令の2ステップに分解して実行すれば良いだけなのでx86(x64)もRISC-Vもそうしている筈。しかしArmの場合、単なるAddはシフト量0のAddとして表現できるくらいで、シフト付きが基本であります。
以前作成した表の中で今回使用してみた命令を赤枠で囲みました。以下の部分。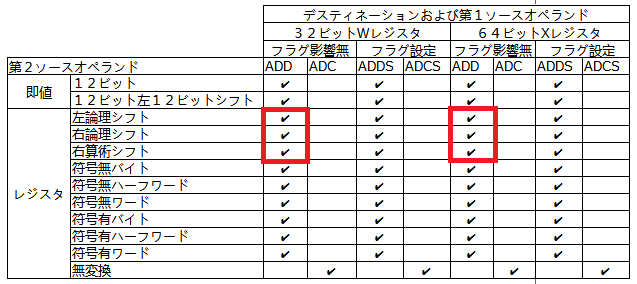
なお、命令を記述するにあたって参照しているのはArm社の以下のドキュメントです。
Arm Architecture Reference Manual for A-profile architecture
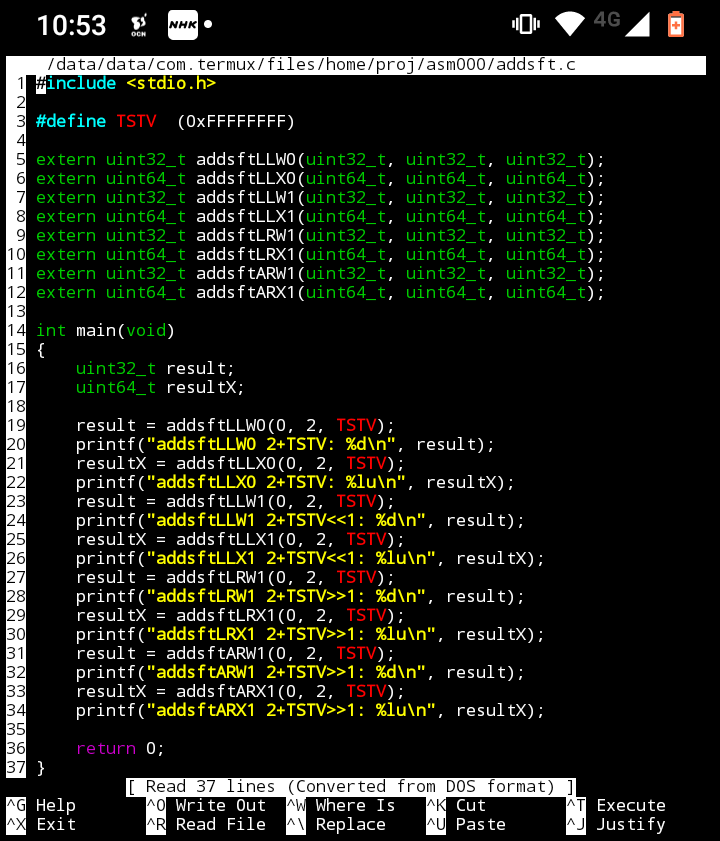
アセンブラのソースコード
テスト用に実質、1命令1関数として、8関数を定義してみました。
-
- レジスタ幅は32ビット(W)と64ビット(X)の2通り
- シフトはLSL、LSR、ASRの3通り
- シフト量はLSLのみ0ビットと1ビットの2通り、他は1ビット
アセンブリ言語ソースが以下に。
.globl addsftLLW0, addsftLLX0, addsftLLW1, addsftLLX1, addsftLRW1, addsftLRX1, addsftARW1, addsftARX1
.text
.balign 4
addsftLLW0:
add w0, w1, w2, LSL #0
ret
addsftLLX0:
add x0, x1, x2, LSL #0
ret
addsftLLW1:
add w0, w1, w2, LSL #1
ret
addsftLLX1:
add x0, x1, x2, LSL #1
ret
addsftLRW1:
add w0, w1, w2, LSR #1
ret
addsftLRX1:
add x0, x1, x2, LSR #1
ret
addsftARW1:
add w0, w1, w2, ASR #1
ret
addsftARX1:
add x0, x1, x2, ASR #1
ret
テスト用の上位のCソース
あいも変わらぬ、ぐだぐだのソースが以下に。
#include <stdio.h>
#define TSTV (0xFFFFFFFF)
extern uint32_t addsftLLW0(uint32_t, uint32_t, uint32_t);
extern uint64_t addsftLLX0(uint64_t, uint64_t, uint64_t);
extern uint32_t addsftLLW1(uint32_t, uint32_t, uint32_t);
extern uint64_t addsftLLX1(uint64_t, uint64_t, uint64_t);
extern uint32_t addsftLRW1(uint32_t, uint32_t, uint32_t);
extern uint64_t addsftLRX1(uint64_t, uint64_t, uint64_t);
extern uint32_t addsftARW1(uint32_t, uint32_t, uint32_t);
extern uint64_t addsftARX1(uint64_t, uint64_t, uint64_t);
int main(void)
{
uint32_t result;
uint64_t resultX;
result = addsftLLW0(0, 2, TSTV);
printf("addsftLLW0 2+TSTV: %d\n", result);
resultX = addsftLLX0(0, 2, TSTV);
printf("addsftLLX0 2+TSTV: %lu\n", resultX);
result = addsftLLW1(0, 2, TSTV);
printf("addsftLLW1 2+TSTV<<1: %d\n", result);
resultX = addsftLLX1(0, 2, TSTV);
printf("addsftLLX1 2+TSTV<<1: %lu\n", resultX);
result = addsftLRW1(0, 2, TSTV);
printf("addsftLRW1 2+TSTV>>1: %d\n", result);
resultX = addsftLRX1(0, 2, TSTV);
printf("addsftLRX1 2+TSTV>>1: %lu\n", resultX);
result = addsftARW1(0, 2, TSTV);
printf("addsftARW1 2+TSTV>>1: %d\n", result);
resultX = addsftARX1(0, 2, TSTV);
printf("addsftARX1 2+TSTV>>1: %lu\n", resultX);
return 0;
}
実機実行確認
実機での実行確認には例によって、普及価格帯のAndroidスマホ(Arm Cortex-A73/A53)を使用し、Termux環境にパソコンからSSH接続して行っています。Termux環境では、デフォルトでgccでなく、clang/llvmがインストール済だったので、そのまま clangでビルドしています。こんな感じ。
$ clang -g -O0 -o addsft addsft.c addsft.s
実行結果のキャプチャが以下に。
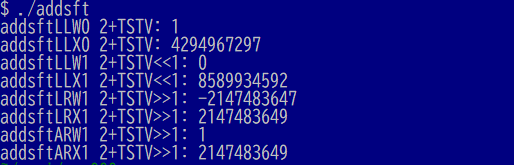
全ての命令の第2オペランドは2、第3オペランドは0xFFFFFFFFです。
最初の addsftLLW0 は、32ビット幅演算でシフト量0で足しています。32ビット幅でラップするので結果は1と。
2番目の addsftLLX0は、演算幅を64ビットにしてみたもの。シフト量は0です。結果4294967297は、16進0x100000001と。正常に繰り上がってますな。
3番目の addsftLLW1は、演算幅32ビット、第3オペランドを左論理シフト1ビットしてから加算です。0xFFFFFFFFを左1ビットシフトすると0xFFFFFFFEになるので、それに2を足すとラップして0に戻ります。
4番目のaddsftLLX1は、上記の演算幅を64ビットにした場合、ラップしないので、結果は0x1FFFFFFFE + 2 で8589934592。
5番目のaddsftLRW1は、第3オペランドを右1ビット論理シフトです。0x7FFFFFFF+2になるので、0x80000001が結果です。これをprintfで符号付き32ビット値(%d変換)すると-2147483647となります。
6番目のaddsftLRX1は、上記と同じものの64ビット版です。64ビットにすると符号ビットは無関係になるので、2147483649です。
7番目のaddsftARW1は、第3オペランドを右1ビット算術シフトです。1ビット算術シフトしても0xFFFFFFFFは変化しないので、32ビット演算結果は第1と同じ1です。
8番目のaddsftARX1は、上記の64ビット版です。第3オペランドを右1ビット算術シフトするのですが、32ビット幅の0xFFFFFFFFは「小さな正の数」なので符号は遥か上にありシフトの結果は0x7FFFFFFFです。結局6番目と同じ加算となるので結果は、2147483649です。
ひとあたりシフト付きの加算できましたかね。フラグに反映させる adds は前回やったのでパス。次回は符号付き、符号無の拡張に進みたいと思います。