今回は、初登場のデータ形式、距離行列を扱いますです。階層的なクラスタリングで使ったりするもの。通常は何かの指標等を「距離に見立てて」計算して生成する行列なのだと思いますが、今回はもろ距離そのもの(直線距離、マイル表示)で距離行列として生成済でした。クラスタリングの結果は如何に?
※「データのお砂場」投稿順Indexはこちら
R言語にデフォルトで所蔵されとりますサンプルデータをABC順(大文字先)で端から眺めております。今回のサンプルデータセット UScitiesD の説明が以下のページにあります。
Distances Between European Cities and Between US Cities
説明らしい説明もなければ、期待の処理例もありません。唯一のお役立ち情報が、このデータが米国の10都市の間の “straight line” 距離だということ。直線距離、球面である地球上の話でありますから多分「大円距離」の事だよね。まさか地球内部を突き抜けて本当に直線で測った「ユークリッド距離」ではないよね。。。
距離の単位も何も書いてありませぬ。でもま、米国だし、ぱっと見の距離感で、マイルだよね。以下マイルということで進めさせていただきます。
さて、行、列ともに各都市名が順番に割り当てられた「下三角行列」に似た配列が今回処理対象のデータです。処理にあたっては、同志社大 Mingzhe Jin先生の以下のページを参照させていただきました。
ありがとうございます。
通常、Rでクラスター分析をするという場合には、多分 距離行列(dist型)を生成するところから始めるんじゃないかと思います。距離とはいうものの、実際に取り扱うのは距離ではなく、何か各点の特徴を表す指標値がその実体。その数値差を距離に見立てて、ユークリッド距離とかマハラノビス距離とか計算して用いる、のではないかと。しかし今回はモロ距離です。
まずは生データ
生データをロードして眺めたところが以下に。データセット自体の大きさがささやかなものなので全部ダンプしても大したことないです。

最後のclass()の結果が切れてしまいました。結果は”dist”です。距離行列、というデータ型なのだと思います。
階層的クラスタリング
さて、今回は階層的クラスタリングというのをやってみるしかないです。上記ホームページを参照させていただいて、階層的クラスタリングを行うhclust()関数で使えそうなmethod全てをやってみました。こんな感じ。
USc.hccomp <- hclust(UScitiesD, method="complete") USc.sgcomp <- hclust(UScitiesD, method="single") USc.avcomp <- hclust(UScitiesD, method="average") USc.ctcomp <- hclust(UScitiesD, method="centroid") USc.mdcomp <- hclust(UScitiesD, method="median") USc.wdcomp <- hclust(UScitiesD, method="ward.D") USc.mcquitty <- hclust(UScitiesD, method="mcquitty")
なお、下から2番目の ward 法は、最初 method=”ward” として実行すると、以下のようなメッセージが出力されました。それで ward.D と変更してあります。

また、なにやら ward.D2というのもあるみたいですが、パス。
デフォルト(complete、最遠隣法)
デフォルトのmethod=”complete”、日本語で最遠隣法でクラスタリングした結果が以下に。縦方向のHeightはクラスタリングするときの「木の高さ」みたいです。
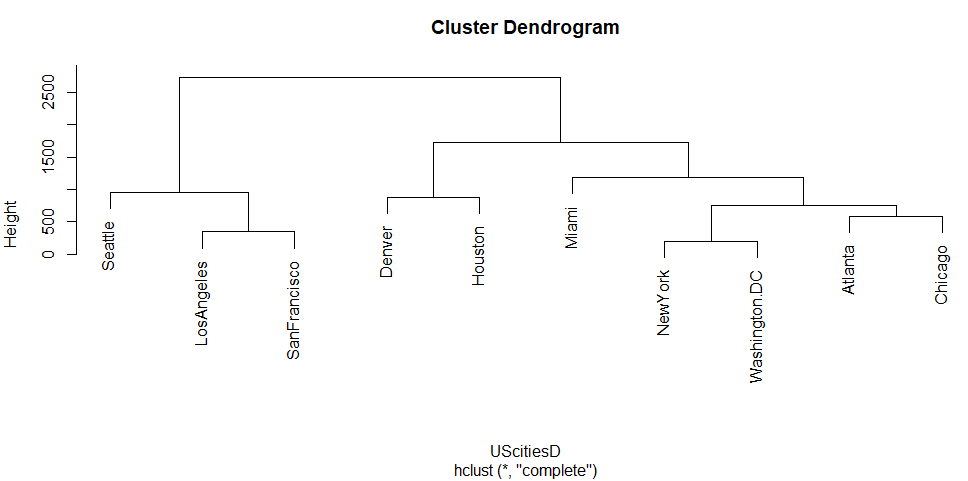
西海岸の都市と、コンティネンタル・デバイド以東の諸都市という感じの分類。まあ腑に落ちるんでないかい。
single、最近隣法
最近隣法というものに変更してみると、クラスタ変わりましたな。
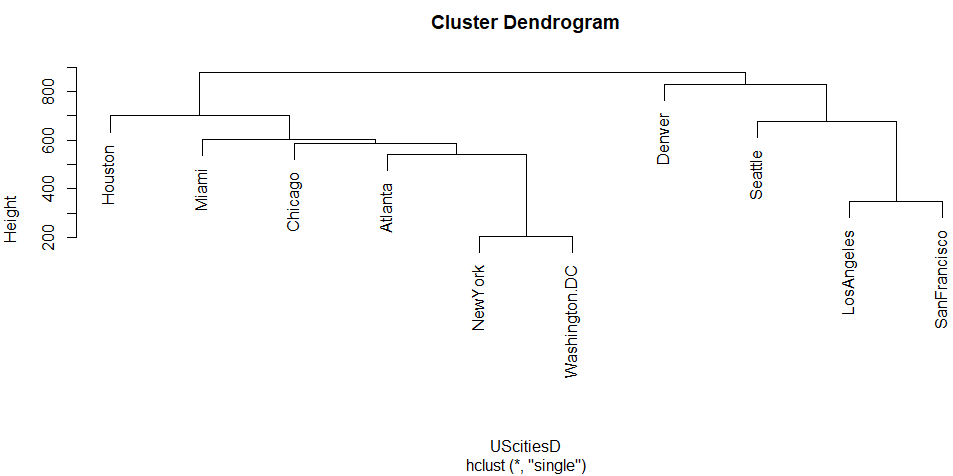
デンバーが西海岸組に編入っと。デンバーはロッキーの東側だけれど、距離やらなにやらそれでもいいかも、という気もしないでもない。
average、群平均法
次のAverageでは、また西海岸組とそれ以外という感じ。デフォルトに近いです。
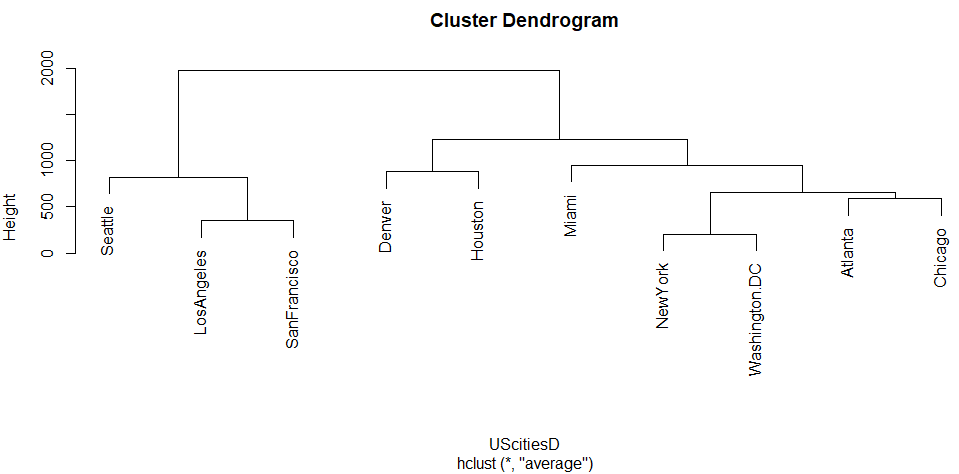
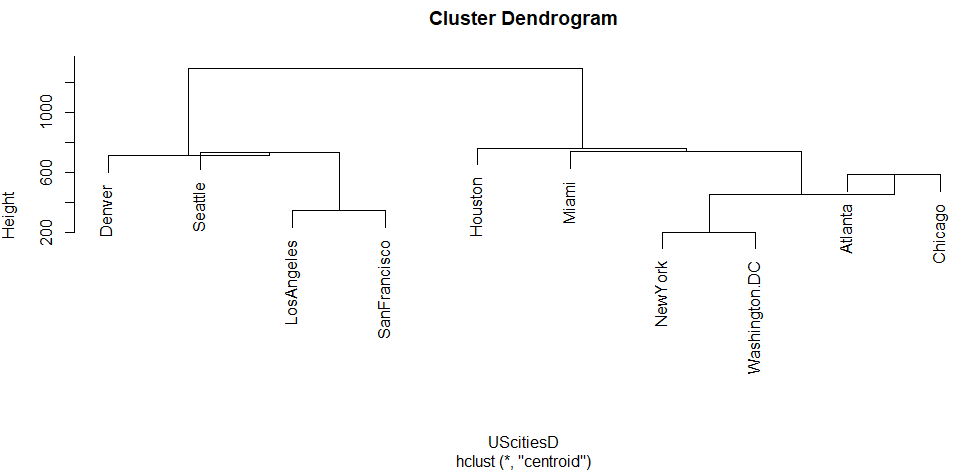
centroid、重心法
重心法という方法では何やら高さの求め方が他と違いそう。ちと見にくいです(個人の感想です。)
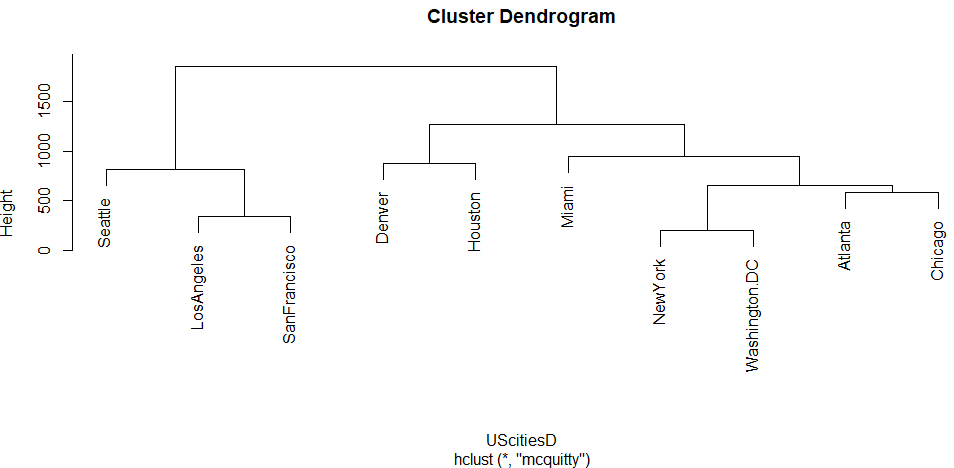
median、メディアン法
メディアンもチトです。
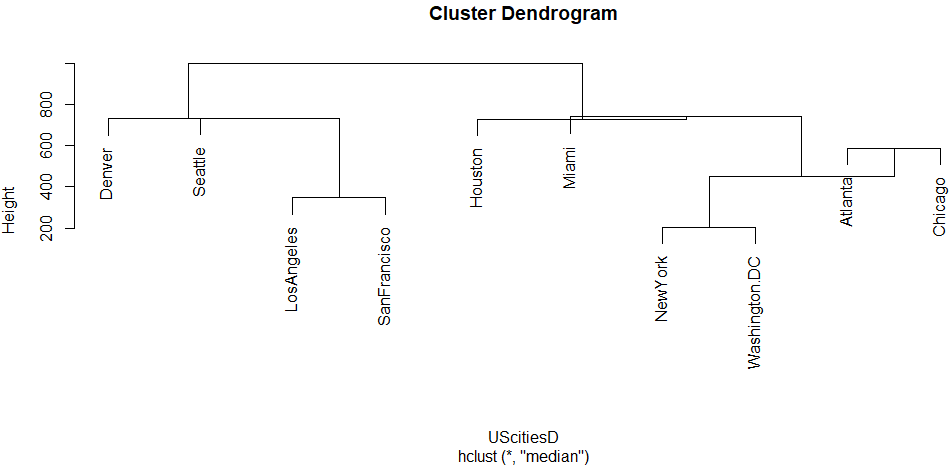
ward.D、ウォード法
ウォード法という方法では、ほぼ大陸を真ん中で東西に分けているような感じな結果。別にアルゴリズムはそんなこと考えて?ないだろうけれど。
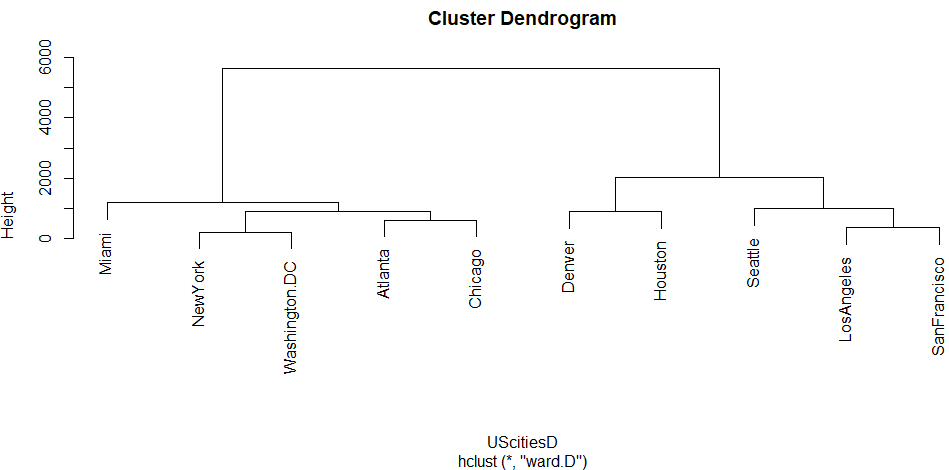
mcquitty、McQuitty法
最後にまた元に戻った感じ。
これだけみて、どれが良いとか悪いとか、言えんよなあ。でも、言えともなんとも言われていないか。
一つ思いつきました。メジャーリーグ30球団の本拠地球場間の距離で距離行列を作ってクラスタリングして、それを実際の両リーグの東、中、西の地区分けと比べてみるというのはどうざんしょ。各メソッドの実力が分かる?それとも分かるのは興行の大人の事情か?まあ、メンドイです。多分やらんけど。