前回はFADD命令をさわり、ARMv8p0には半精度浮動小数点型が無かったというお間抜け発覚。今回はFADD以外のFloating-point arithmetic (two sources)の残りFSUB, FMUL, FNMUL, FDIVであります。まあ、以下同文っていう感じなんでありますが。単精度と倍精度。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
Floating-point arithmetic (two sources)の残り
ひととおりの命令に触ってみる、というのはRISC-Vではそれほど苦労もしなかった記憶が、Armの64ビットでは延々と続く長大な作業となっております。いつ果てることか先が見えませぬ。
まあ、ぶつくさ言わずに前回の残りです。2つのソースレジスタをとってその間で演算をして結果をデスティネーションレジスタに返すもの。浮動小数点を扱う命令群の中では、ある点を除き一番わかりやすい命令群じゃないかと思います。まあ、ある点というのは例外の発生でありますが、今のところは踏み込みませぬ。
前回のFADDを含めると以下の5命令であります。
-
- FADD
- FSUB
- FMUL
- FNMUL
- FDIV
加減乗除で4命令と思いきや、FMUL(乗算)にはFNMUL(乗算後ネゲート)という相棒がおり、合計5命令となります。私はFNMUL命令がいることでどのくらいの御利益があるのか知りません。Arm様がどのようなご判断で乗算後ネゲート命令を加えたのか知りたいものですが、手がかりも見つからず。あれば使うからまあいいか。
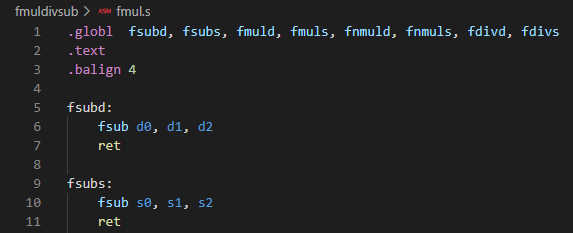
さて、例によってほぼほぼ1命令、1関数のアセンブリ言語記述被テスト関数群が以下に。短いので関数プロローグ、エピローグ無の手抜きです。
.globl fsubd, fsubs, fmuld, fmuls, fnmuld, fnmuls, fdivd, fdivs
.text
.balign 4
fsubd:
fsub d0, d1, d2
ret
fsubs:
fsub s0, s1, s2
ret
fmuld:
fmul d0, d1, d2
ret
fmuls:
fmul s0, s1, s2
ret
fnmuld:
fnmul d0, d1, d2
ret
fnmuls:
fnmul s0, s1, s2
ret
fdivd:
fdiv d0, d1, d2
ret
fdivs:
fdiv s0, s1, s2
ret
C言語記述のmain関数
以下が上記の関数群を呼び出して、うわべをさっと1回なでるだけのmain()関数です。前回は半精度が使える?と半精度用のヘッダなど取り込んでましたが、今回はそのようなものは無し。サッパリしたもんです。
#include <stdio.h>
#include <stdint.h>
extern double fsubd(double, double, double);
extern float fsubs(float, float, float);
extern double fmuld(double, double, double);
extern float fmuls(float, float, float);
extern double fnmuld(double, double, double);
extern float fnmuls(float, float, float);
extern double fdivd(double, double, double);
extern float fdivs(float, float, float);
int main(void)
{
double resultD;
float resultS;
resultD = fsubd(0.0, 1.234567890123456, 1.0);
printf ("fsubd(0.0, 1.234567890123456, 1.0): %.16e\n", resultD);
resultS = fsubs(0.0f, 1.234567f, 1.0f);
printf ("fsubs(0.0f, 1.234567f, 1.0f): %f\n", resultS);
resultD = fmuld(0.0, 1.234567890123456, 1.5);
printf ("fmuld(0.0, 1.234567890123456, 1.5): %.16e\n", resultD);
resultS = fmuls(0.0f, 1.234567f, 1.5f);
printf ("fmuls(0.0f, 1.234567f, 1.5f): %f\n", resultS);
resultD = fnmuld(0.0, 1.234567890123456, 1.5);
printf ("fnmuld(0.0, 1.234567890123456, 1.5): %.16e\n", resultD);
resultS = fnmuls(0.0f, 1.234567f, 1.5f);
printf ("fnmuls(0.0f, 1.234567f, 1.5f): %f\n", resultS);
resultD = fdivd(0.0, 1.234567890123456, 1.5);
printf ("fdivd(0.0, 1.234567890123456, 1.5): %.16e\n", resultD);
resultS = fdivs(0.0f, 1.234567f, 1.5f);
printf ("fdivs(0.0f, 1.234567f, 1.5f): %f\n", resultS);
return 0;
}
適当なリテラル値を書き込んでおりますが、倍精度は桁が多いのう。
ビルドして実行
被テスト・アセンブラ命令は関数の中に押し込めてあるので大丈夫だとは思うのですが、気を抜いて、コンパイラ様が気を利かせてくれたりするとマズイので、鉄板の -O0 付です。まあ、テストしたつもりが、実は中身は空だった、なんてことがまれにあり。コンパイラの最適化は恐ろしいっす(普通はありがたいんだが。)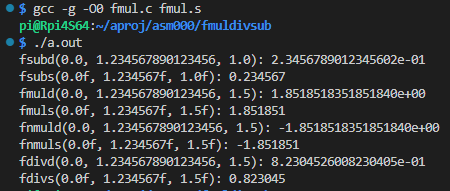
特に波乱もなく、実行されている感じですな。細かい検算してないケド。まあ以下同文だし、ともかく触ったということでいいか。