今回のサンプルデータセットには “Student’s Sleep Data” というタイトルがついてます。以前であれば「学生さんのデータなの?」とボケをかますところです。今では知っています。また出たなStudent先生、t検定をやれってことですかい?データ自体は「眠くなるお薬」を飲んだ時の睡眠時間のデータらしいっす。
※「データのお砂場」投稿順Indexはこちら
R言語所蔵のサンプルデータセットをABC順(大文字)優先で拝見させていただいております。
今回のサンプルデータセット
サンプルデータセットの解説ページが以下に。
この大文字に始まるStudentこそは、かのStudent(ペンネーム)大先生であります。データは眠くなるような薬(酔い止めみたいなもの?)が2種類、被験者が10名様、2x10で20のケースについて、睡眠時間がどんだけ伸びたのだかのデータらしいっす。一部フィールド名はちょいとmisleadingだと解説ページにも書かれておりました。
group
というフィールドは薬の種類を表しているみたいです。「このフィールドでグループわけせよ」ということ?知らんけど。
まずは生データ
生データは、通常のデータフレームでした。睡眠時間の「伸び」はextraというフィールドです。ついでにデータ全体のsummary()もとってみました。
薬飲んだのに睡眠時間が短くなっているケースもあるみたいです。まあ、そういうこともあるわいなあ。たかだか10名様で1回づつ別の薬を飲んでもらってデータをとって、どのくらい信憑性があるの?と思ってしまいますが。
小さいデータセットなので、全体をダンプしてみました。こんな感じ。IDっていうのが各被験者様に紐づいているファクタみたいです。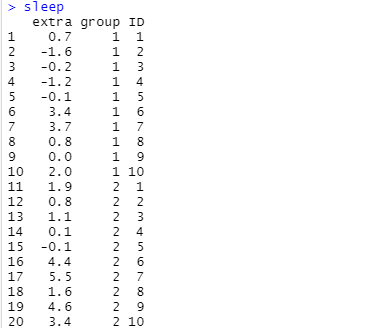
とりあえずグラフ
今回は解説ページに処理例が記載されとります。しかし処理例を練習する前に多少は自力更生、プロットくらいはしてみます。この手の「分散分析的」比較データの場合、とりあえずボックスプロットしておけば「だいたいの感触が分かる」ということは忘却力の年寄にも分かってきましたぞ。
今回のボックスプロットはいつもの「エコノミスト誌」風の体裁にしてみました。
library(ggplot2)
library(ggthemes)
p<-ggplot(sleep, aes(x=group, y=extra))+geom_boxplot()
p + labs(title="Student's Sleep Data") + ylab("numeric increase in hours of sleep") + theme_economist()
プロット結果が以下に。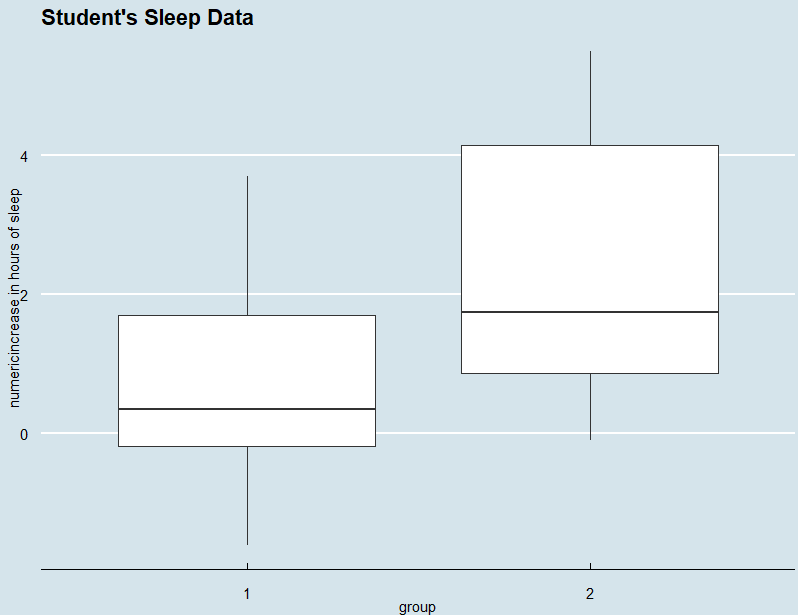
groupとあるのは前述のとおり薬の種類デス。1の薬より2の薬の方が効きが良いのでないかい?
上記のボックスプロットの真ん中の線は中央値であって、平均値ではありませぬ。一応、各groupの平均値も求めておくってもんでしょう。こんなやり方でよかですか?
library(tidyverse) work <- group_by(sleep, group) result <- summarize(work, mean(extra)) result
結果がこちら。やはり2の薬の方が結果が長いっす。
処理例をやってみる
今回の解説ページには処理例も記載されていたので、そのまま実行してみます。当然ですが、「スチューデントのt検定」が登場します。ポイントは「2つのお薬の効果には差がない」という帰無仮説が棄却できるかどうかというところ。なお、t検定については以下のページが短くて分かりやすかったです。あざ~す。
処理例通りにt検定(t.test)しているところが以下に。

真ん中辺に p-value = 0.002833 と出力されとります。5%でも1%でも下回っている数字なので、つまりは「差が無い」という帰無仮説は棄却される(まどろっこしい言い方よな。)
なおwithで囲んで処理してます。これは今回の学びですな。「書き換えられちゃう」データの場合、私は事前にコピー(クローン)を作って処理してましたが、withで囲めばその内部で起こった副作用的なものはwithの外へ出れば消えてなくなるみたいデス。便利ね。
しかし処理例ではもう一歩「踏み込んだ」処理をしているのであります。10名の被験者様全員が薬1と2の両方を服用しているので、それぞれの被験者毎の1と2の時間差を計算して新データsleep1を作ってました。
sleep1は上記のように単なる数値ベクトルです。
これをstripchart(1次元のバラツキをみる)とboxplotしてみろと。![]()
結果はこんな感じ。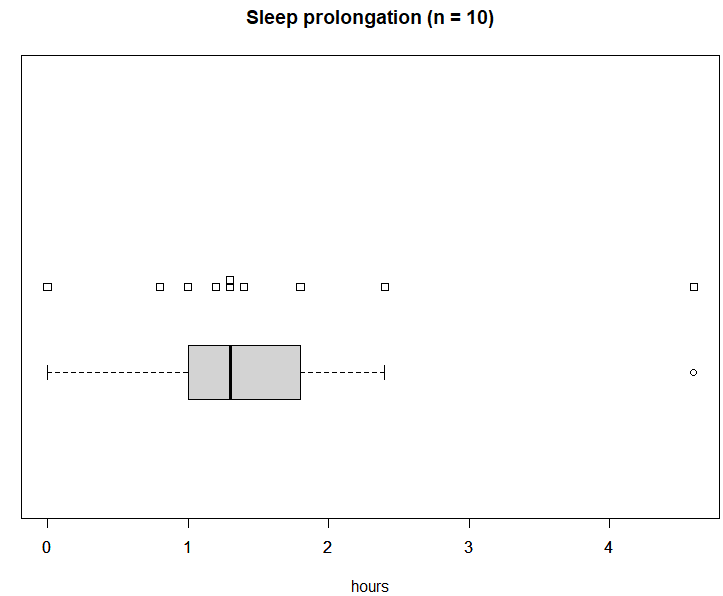
おひとり様、大外れ(眠り過ぎてる)な人がいるのね。9番目の被験者様だよ。一方、5番目の被験者様は薬などまったく関係ない感じ。