RTLSDRのデータをPythonにて取得し音声再生、無線データはScilabへも輸出。ScilabにてPythonと同処理を行おうとしてコケました。どこが悪いのか追及するために前回Pythonの途中経過データをゴッソリ出力。今回はScilab処理結果と逐一比較しながらデバッグ。まあ、音は出るようになったんだけれども。
※「手習ひデジタル信号処理」投稿順 Indexはこちら
前回ソースに1か所問題あり
今回Scilab上で処理を進めていて前回の中間データ「ゴッソリ」版のPythonソースに1か所不具合発覚。1回目のデシメーション処理結果を出力するところで、まさかの出力フォーマット指定抜けです。前回ソースの以下の行
np.savetxt(FNAME_D1, self.d1data)
上記を下の行のようにfmt=指定つけないとなりません。
np.savetxt(FNAME_D1, self.d1data, fmt='%.18e %+.18ej')
そうしないと、Scilabで該当ファイルを「読める」のですが、値は全部NaNになってナンだかな~ということになります。すみません。
ステップバイステップ処理の準備
相当前の回で作成済の関数を2つ使うので最初はそれらを使うためのおまじないから
exec('genFIRLP2.sci', -1)
exec('plotFFT2.sci', -1)
つづいて、Python側で取得した信号類を一気にロードしておきます。
txFnam=fullfile("C:\var", "Tx.csv");
txaFnam=fullfile("C:\var", "Tx_audio.csv");
tx1Fnam=fullfile("C:\var", "Tx_d1d.csv");
tx2Fnam=fullfile("C:\var", "Tx_d2d.csv");
txdFnam=fullfile("C:\var", "Tx_demod.csv");
tx=csvRead(txFnam);
tx_audio=csvRead(txaFnam);
tx_d1d=csvRead(tx1Fnam);
tx_d2d=csvRead(tx2Fnam);
tx_demod=csvRead(txdFnam);
Scilab側では、元の信号 Tx.csvを出発点に処理していき、その中間結果を適宜Python側と比較していくことで、問題のステップを発見しようという、単純で工夫のないアプローチです。
Fa = 44100; Fi = Fa * 6; Fs = Fa * 48; Fcutoff = Fs / 8 / 2; FcutoffS = Fa / 2;
上記のうち、Fa = 44100は、音声信号のサンプリング周波数。Fi = Fa * 6は、RTLSDRから得た信号を初段の8:1のデシメーションかけた後、復調処理するときのサンプリング周波数、Fs = Fa * 48は、RTLSDRから取得するIQ無線信号のサンプリング周波数であります。RTLSDRで取得する無線信号の中心周波数自体はめでたく切りの良い80MHzのTokyo FM様に向けております。
また、Fcutoff = Fs / 8 / 2は、8:1の第1段デシメーション処理する前にかけるLPFのカットオフ周波数、FcutoffS = Fa / 2は、2段目の6:1デシメーション処理前のLPFのカットオフ周波数です。
また、Pythonから輸入した信号を確認するため、プロットしたり音声再生したりして確認してます。こんな感じ。
playsnd(tx_audio, Fa); plotFFT2(Fs/8, tx_d1d', 1); plotFFT2(Fs/8, tx_demod', 1); plotFFT2(Fa, tx_d2d', 1); plot(tx_audio);
さて、ここからがScilabでの実処理です。
初段8:1デシメーション処理
ここは既に前々回に「出来た」と思った部分ですが、データ取り直しているので再度実行です。
coeff100=genFIRLP2(Fs, 100, Fcutoff, 1); sampleTX1D=polyphase_decimation(tx, coeff100, 8); plotFFT2(Fs/8, sampleTX1D', 1);
上記のFFTプロット結果をPythonデータのFFTプロットと比べたものが以下に。
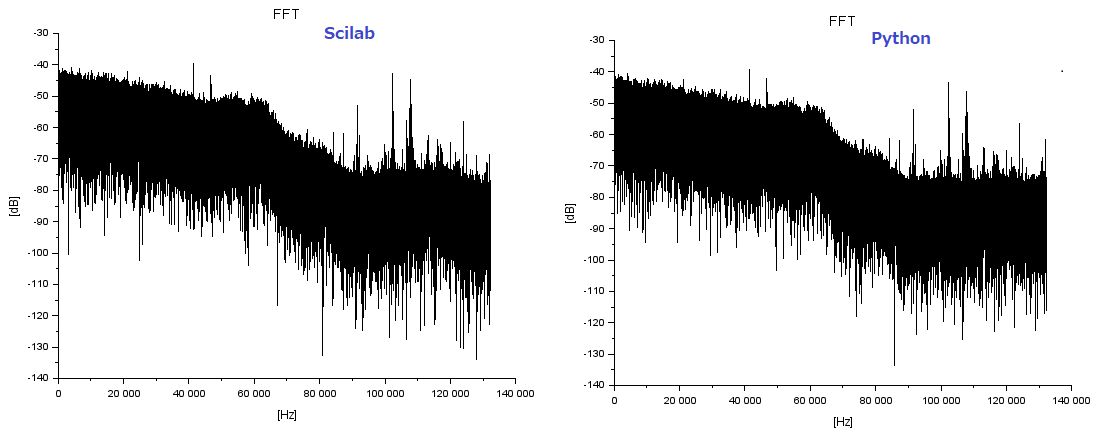
デシメーション前のLPFの係数は異なっている筈なのだけれど、まあまあ「似たような」波形じゃないかと。そんなほんわかしたところで良いのか。
FM復調処理
問題は次のステップにありました。まずは、ダメだったFFTプロットの比較から。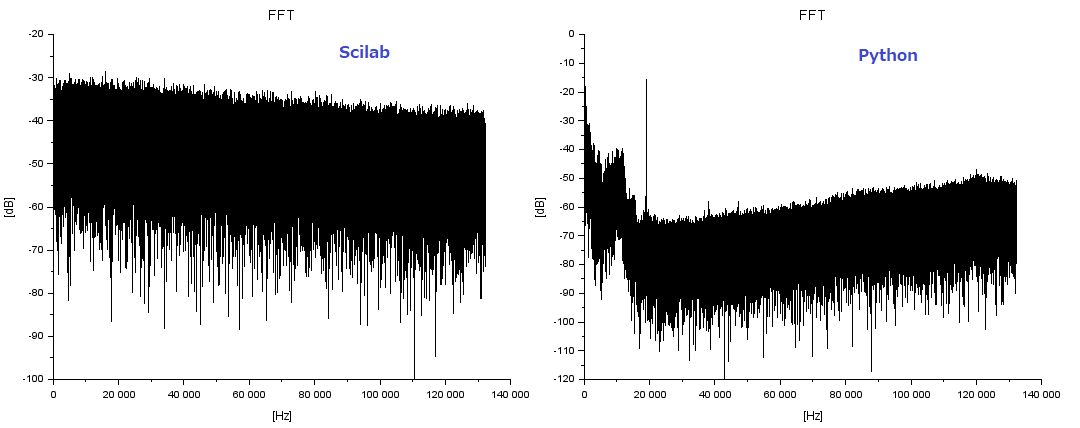
なんだ、全然違うじゃん! バグの原因はココだね。バグを見つければいつもツマラン原因であることが多いです。今回は、処理の途中の「複素共役」とりわすれとな。修正したScilab処理が以下に。
pd8A=sampleTX1D(2:length(sampleTX1D)); pd8B=sampleTX1D(1:length(sampleTX1D)-1); pd8C=pd8A .* conj(pd8B); sampleDemod = atan(imag(pd8C), real(pd8C)); plotFFT2(Fs/8, sampleDemod', 1);
conj()関数1個挿入したら、以下のようになりました。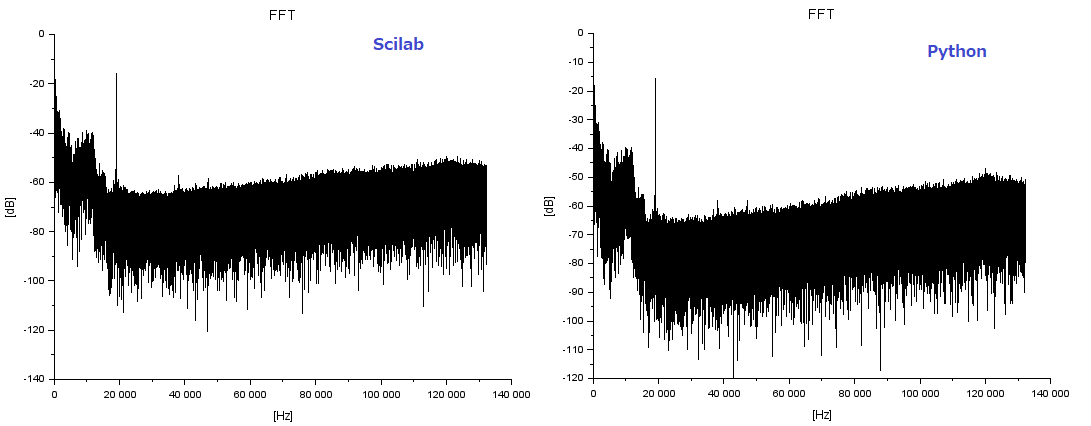
第2段6:1デシメーション処理
第2段デシメーションのScilabコードが以下に。
coeff100S=genFIRLP2(Fi, 100, FcutoffS, 1); sampleTX2D=polyphase_decimation(sampleDemod, coeff100S, 6); plotFFT2(Fa, sampleTX2D', 1);
結果のFFTプロットの比較が以下に。
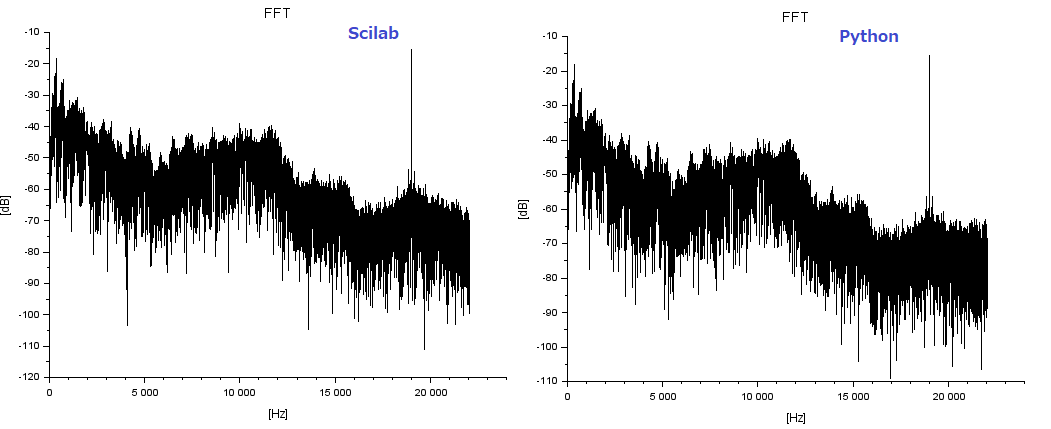 音声ファイル化
音声ファイル化
後は音声ファイル化するのみ。
sampleAudio=(sampleTX2D/%pi * 32768); plot(sampleAudio); playsnd(sampleAudio, Fa);
生成できた音声ファイルをプロットして比べてみるとこんな感じ。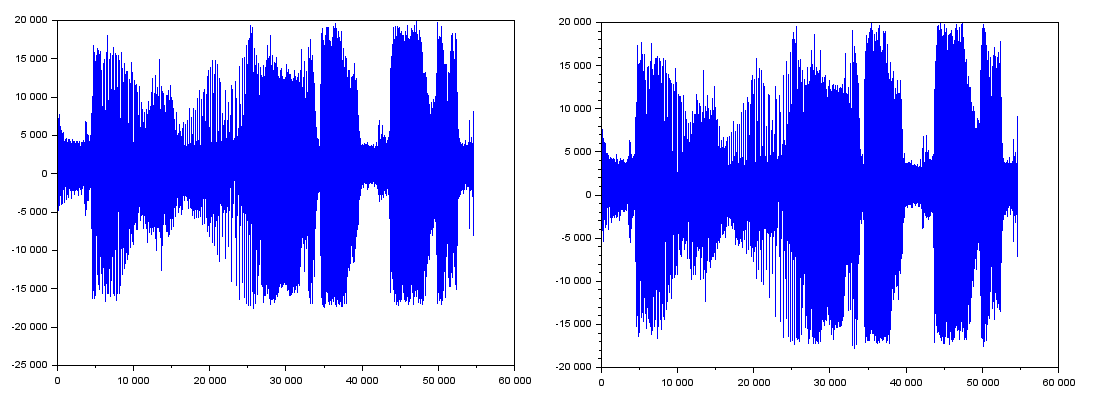
たった1秒強ですが、ちゃんとTokyo FM殿の音声が聞こえましたぞ。この1秒をScilabで聞くまで長かった。