R言語所蔵のサンプルデータセットを端から眺めております。サンプルといいつつ「知らない世界」を垣間見せてくれるのが密かな楽しみです。データセットを開かなければ多分知ることは無かったものばかり。だた今回のデータセットはSimulatedです。統計処理の練習用に人工的に作られたもの。どうも製造プロセスの「何か」らしいが。
※「データのお砂場」投稿順Indexはこちら
R言語向けのパッケージ boot には、サンプルデータセット多数が含まれております。それを ABC順に「舐めて」ます。今回のサンプルデータセットはcapabilityとな。
capability データセット
bootパッケージ、今回のデータセットのタイトルは以下です。
Simulated Manufacturing Process Data
「製造プロセス」をシミュレートし、人工的に生成された数値の集合みたいです。それが製造物の何か長さなのか、性能なのか、分量なのかは全く必要なし。顔の無い無名のデータどもです。この老人の「密かな楽しみ」からするとかなり遠いもの。しかし、統計処理の練習データとして立派に使え、ってこってすかい?
先ずは生データ
bootパッケージ内のデータセットなので、事前にbootパッケージをライブラリとしてロードしておかねばなりません。その前提でまずは生データ。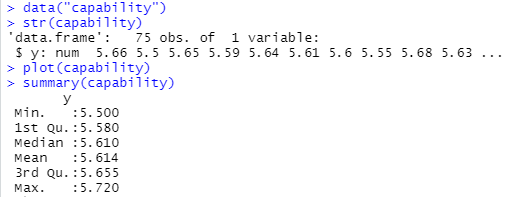
上記では、つい plot(capability) などとしてしまってますが、あんまりなグラフが一葉作られただけなので無視しました。このデータセットの場合は以下のように「ビジュアライズ」するのが適当かと。
hist(capability$y)
上記によって描かれたヒストグラムが以下に。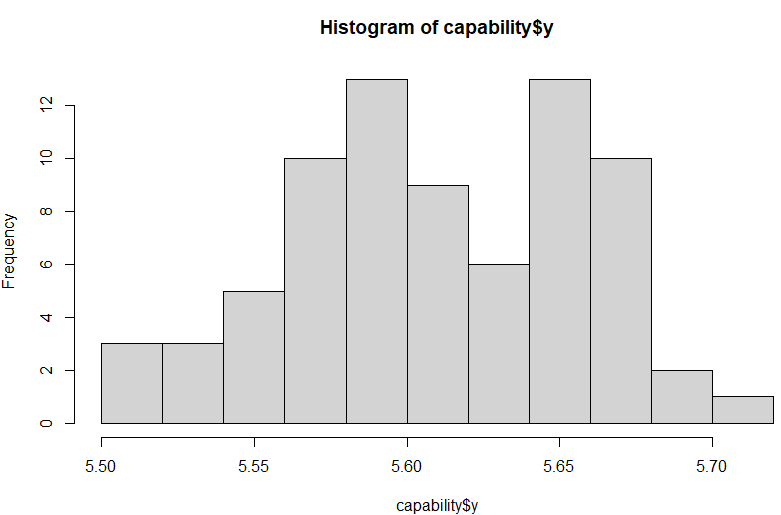
実際の工場などでも時々あるんじゃないかと思われる「ふたこぶ山」的な分布デス。品質保証とか、製造を管理などする部署の方はこの手のデータを処理する技をよくご存じじゃないかと思います。
しかし、この老人はどしたら良いの今回は?特に処理例などの記載もないし。
bootパッケージなのでブートストラップ法を適用してみる
bootパッケージのサンプルデータなので、ブートストラップ法を適用せよ、ということかい、と勝手に解釈して以下のようにしてみました。
sMean <- function(d, i) mean(d$y[i]) cap.sMean <- boot(capability, sMean, R=75, stype = "i") plot(cap.sMean)
なお、統計素人の老人がブートストラップ法についてうんぬんしてもせんないので、第98回にて参考にさせていただいた以下のページへのURLを再掲載しておきまする。「@saltcooky(saltcooky)」様の記事デス。
統計量のバラツキを知るためのブートストラップ法基礎 with R
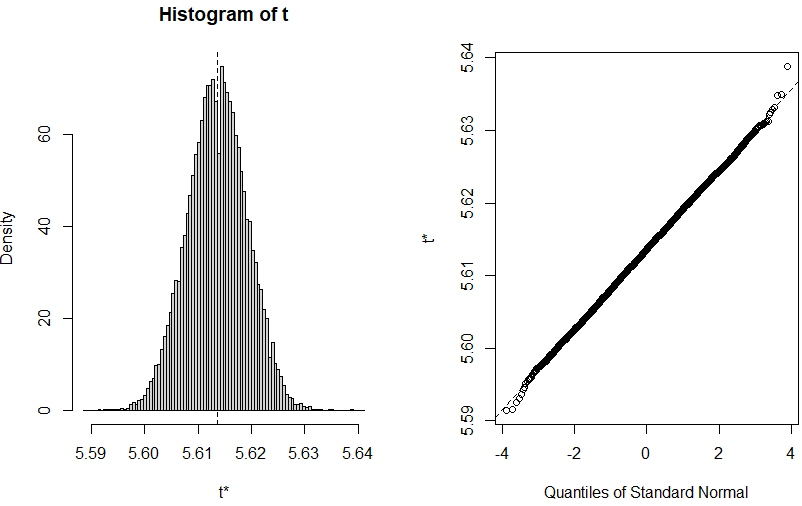
元にもどって上記の処理結果のプロットが以下に。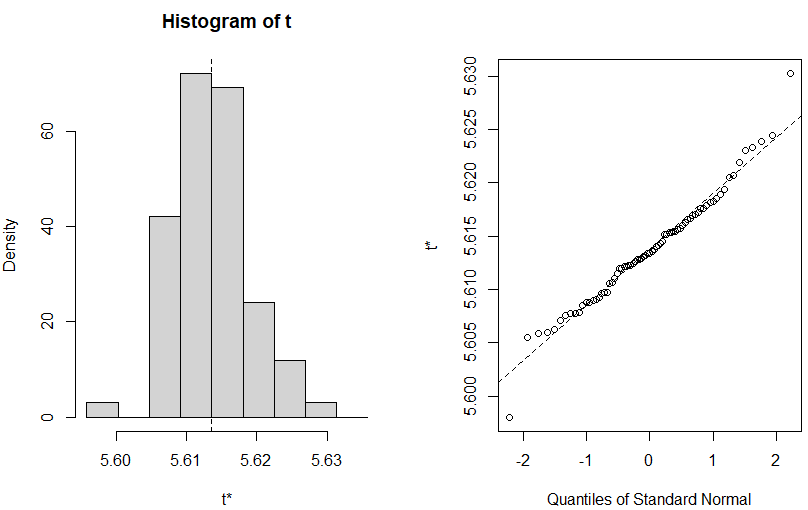
十分な回数サンプリングを繰り返せば、偉大な「中心極限定理」により正規分布に近づくハズ。上記はちょっとサンプリング回数少なすぎるんでないかい。。。
ということで以下の2種類、再計算してみました。
cap.sMean2000 <- boot(capability, sMean, R=2000, stype = "i") cap.sMean20000 <- boot(capability, sMean, R=20000, stype = "i")
2000回だろうが、20000回だろうが、一瞬で処理が終わりました。
まずは2000回のグラフ。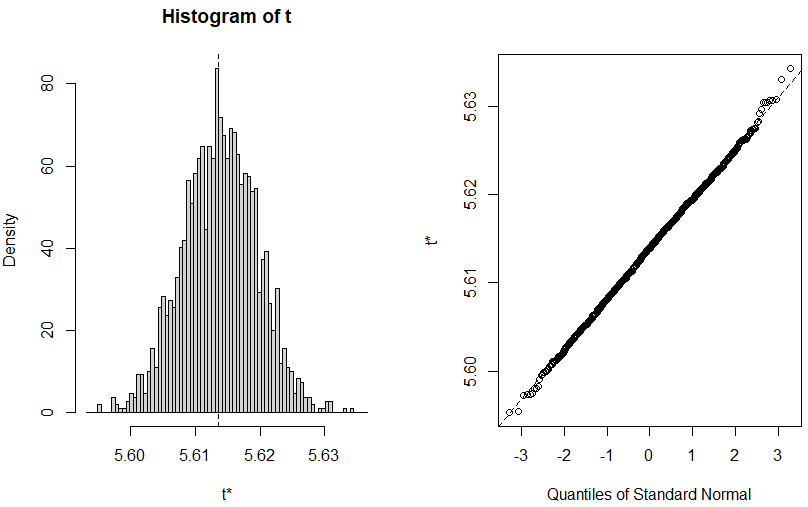
結構、いい感じでないかい。2σ付近までは想定通りだけれど、3σになるとちょっと想定から外れている?知らんけど。
計算結果が以下に。
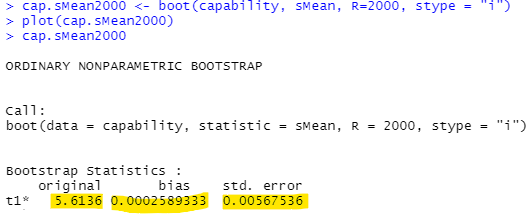
originalが推定される平均値、biasが平均値の偏り、そしてstd. errorが「標準誤差」ってことで良いのかな?
もう一発、20000回にしてみた場合。
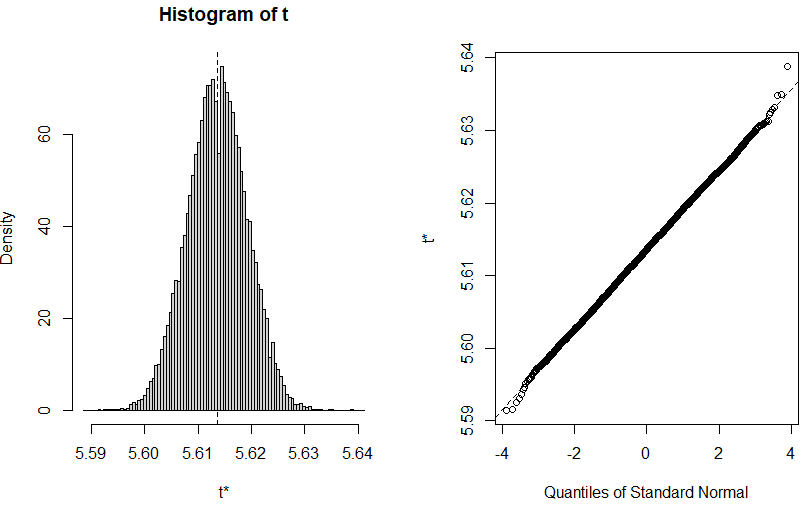
さらに標準正規分布に近付いた気がする。しかし真ん中に穴が開くのは何故?
計算結果が以下に。
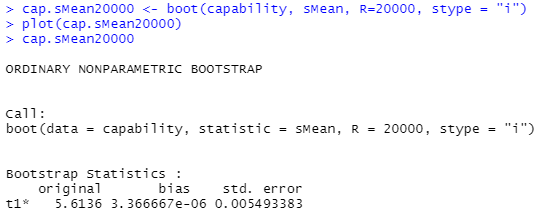
まあ、2000回でも20000回でも「標準誤差」は大差ない?いいのかそういうことで。わからんぞなもし。