前回に続きSIMDの比較命令の練習です。今回は浮動小数型。条件一致すればオール1、不一致でオール0が結果です。いつもの通りA64の命令多すぎ、と書いておきます。前回の整数型であったビット比較が無くなって1個減ったと思ったら、絶対値比較が2個も増えている。かえって練習するパターン増だと。流石だなA64。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
SIMD浮動小数点数の比較命令
前回整数型のSIMD比較命令の一覧表であった符合付、符号無の種別がなくなった分、シンプルにはなってます。みんな符合つきだもんね。しかし前回同様、対ゼロ比較は優遇されてます。また整数型ではなかった絶対値とって比較というニーモニックが追加されてます。
| 比較 | 符号付 |
|---|---|
| = | FCMEQ |
| =0 | FCMEQ |
| ≧ | FCMGE |
| ≧0 | FCMGE |
| > | FCMGT |
| >0 | FCMGT |
| ≦0 | FCMLE |
| <0 | FCMLT |
| |S1|≧|S2| | FACGE |
| |S1|>|S2| | FACGT |
例によって、浮動小数点数の要素は半精度、単精度、倍精度の引数をとることができるのですが、Arm v8.0には半精度のサポートはありません(v8.2以降。)メンドイので、いつもの通り単精度(float)しか練習しないけれども。
実験に使ったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下です。一通り「なでる」だけなのだけれども多いっす。充実というべきか。
.globl fcmeq4V, fcmeqZ4V, fcmge4V, fcmgeZ4V, fcmgt4V, fcmgtZ4V, fcmleZ4V, fcmltZ4V, facge4V, facgt4V
.text
.balign 4
fcmeq4V:
ld1 {v1.4S, v2.4S}, [x0], #32
fcmeq v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
fcmeqZ4V:
ld1 {v1.4S, v2.4S}, [x0], #32
fcmeq v0.4S, v1.4S, #0.0
st1 {v0.4S}, [x0]
ret
fcmge4V:
ld1 {v1.4S, v2.4S}, [x0], #32
fcmge v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
fcmgeZ4V:
ld1 {v1.4S, v2.4S}, [x0], #32
fcmge v0.4S, v1.4S, #0.0
st1 {v0.4S}, [x0]
ret
fcmgt4V:
ld1 {v1.4S, v2.4S}, [x0], #32
fcmgt v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
fcmgtZ4V:
ld1 {v1.4S, v2.4S}, [x0], #32
fcmgt v0.4S, v1.4S, #0.0
st1 {v0.4S}, [x0]
ret
fcmleZ4V:
ld1 {v1.4S, v2.4S}, [x0], #32
fcmle v0.4S, v1.4S, #0.0
st1 {v0.4S}, [x0]
ret
fcmltZ4V:
ld1 {v1.4S, v2.4S}, [x0], #32
fcmlt v0.4S, v1.4S, #0.0
st1 {v0.4S}, [x0]
ret
facge4V:
ld1 {v1.4S, v2.4S}, [x0], #32
facge v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
facgt4V:
ld1 {v1.4S, v2.4S}, [x0], #32
facgt v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。今回の浮動小数点数の比較命令が、何気にメンドイのは、Cからはfloat型の値を配列に与えているのに、SIMD演算の結果はオール0かオール1のビット列なので符合無整数で戻すのが自然ということです。このため、これまたいつもの通りでunion定義してますが、typedefメンドイです。
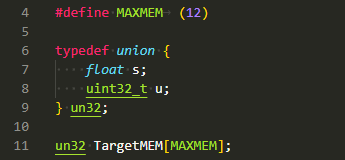
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (12)
typedef union {
float s;
uint32_t u;
} un32;
un32 TargetMEM[MAXMEM];
extern void fcmeq4V(un32 *);
extern void fcmeqZ4V(un32 *);
extern void fcmge4V(un32 *);
extern void fcmgeZ4V(un32 *);
extern void fcmgt4V(un32 *);
extern void fcmgtZ4V(un32 *);
extern void fcmleZ4V(un32 *);
extern void fcmltZ4V(un32 *);
extern void facge4V(un32 *);
extern void facgt4V(un32 *);
void initTGT() {
TargetMEM[0].s = 0.0;
TargetMEM[1].s = 1.25;
TargetMEM[2].s = -1.25;
TargetMEM[3].s = -1.5;
TargetMEM[4].s = 1.25;
TargetMEM[5].s = 1.25;
TargetMEM[6].s = -1.25;
TargetMEM[7].s = -1.25;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 4; i++) {
printf("%02d: %3.3f opr %3.3f -> 0x%08x\n", i, TargetMEM[i].s, TargetMEM[i+4].s, TargetMEM[i+8].u);
}
}
void dumpTGTZ(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 4; i++) {
printf("%02d: %3.3f opr 0.000 -> 0x%08x\n", i, TargetMEM[i].s, TargetMEM[i+8].u);
}
}
int main(void) {
initTGT();
fcmeq4V(TargetMEM);
dumpTGT("fcmeq");
fcmeqZ4V(TargetMEM);
dumpTGTZ("fcmeq zero");
fcmge4V(TargetMEM);
dumpTGT("fcmge");
fcmgeZ4V(TargetMEM);
dumpTGTZ("fcmge zero");
fcmgt4V(TargetMEM);
dumpTGT("fcmgt");
fcmgtZ4V(TargetMEM);
dumpTGTZ("fcmgt zero");
fcmleZ4V(TargetMEM);
dumpTGTZ("fcmle zero");
fcmltZ4V(TargetMEM);
dumpTGTZ("fcmlt zero");
facge4V(TargetMEM);
dumpTGT("facge");
facgt4V(TargetMEM);
dumpTGT("facgt");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdfcmp.c simdfcmp.s $ ./a.out
-
- イコール比較、レジスタ間と対ゼロ
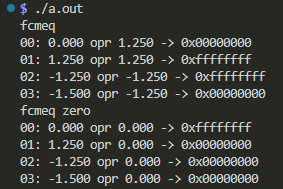
-
- 大なりおよび大なりイコール比較、レジスタ間と対ゼロ
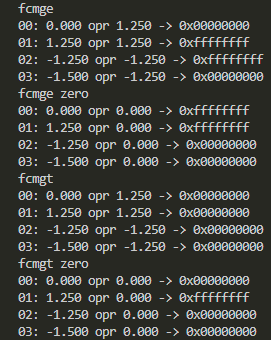
-
- 小なりおよび小なりイコール比較は対ゼロしかありませぬ
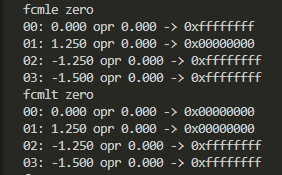
-
- 最後は絶対値とってからの大なりおよび大なりイコール比較
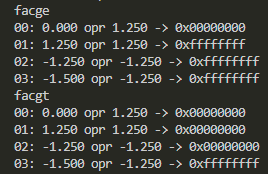 いつもの通り、命令多すぎA64。
いつもの通り、命令多すぎA64。