前回、前々回とA64のSIMD比較命令を練習。今回から要素のビット幅が「変わる」SIMD算術演算命令に入ります。通常のSIMD命令は要素のビット幅は不変なのでコイツ等はちょっと変わり者です。しかし変わり者といえどフツーにひと揃いの演算が含まれております。命令多過ぎA64。いったい何個あるんじゃあ。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
要素のビット幅が狭くなる、広くなる命令群
演算すると要素のビット幅が狭くなる(narrow)と広くなる(wide)命令セットには、加減算、乗算、積和演算など一通りの命令が備わっています。今回は、まず「演算パターン」を抑えておくべし、とのことで加算系命令に絞って練習することにいたしました。しかし、加算に限っても以下の12ニーモニック分も命令があるのです。
-
- ADDHN, ADDHN2 Add returning high, narrow
- RADDHN, RADDHN2 Rounding Add returning high, narrow
- SADDL, SADDL2 Signed Add Long
- SADDW, SADDW2 Signed Add Wide
- UADDL, UADDL2 Unsigned Add Long
- UADDW, UADDW2 Unsigned Add Wide
狭くなる奴が丸め付と丸め無で2種類、しかし2がつく奴と2がつかない奴がいるので2x2で合計4種類です。広くなるものが符合付、符号無で2種類、上と同様に2がつく奴と2がつかない奴がある上に、LongとWideという区別まであります。2x2x2で8種類ね。総合計12種類デス。やってられんな。。。
今回は、以下の4ニーモニックに絞って練習してみることにいたしました。
-
- ADDHN
- ADDHN2
- UADDW
- UADDW2
こ奴らのパターンを抑えておけば、なんとかなるっと。ホントか?
ADDHNとADDHN2を図示してみる
英語の文章でくだくだ説明されても忘却力の年寄は読んだそばから忘れてしまうので図にしてみましたぞ。16ビット幅の整数型要素2つを足して「ハイ側」のバイトを8ビット幅の「狭い」整数型のベクトルとして取り出す操作です。こんな感じ。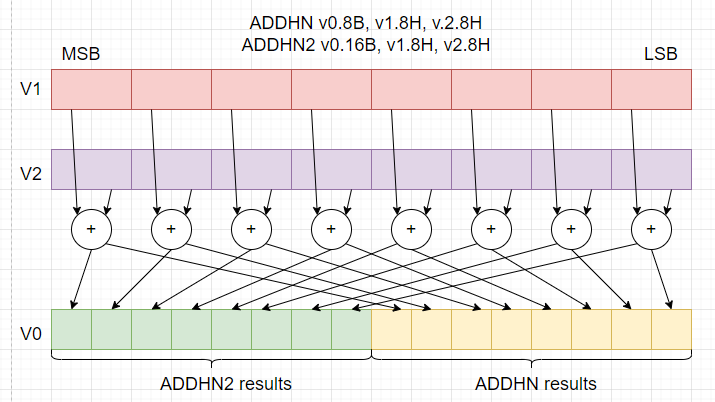
図にしたら何てこともありません。2がついているのとついていないのは結果の8ビット要素のベクトルをデスティネーション・レジスタの上側に置くか、下側に置くかの違いっす。
しかし、アセンブラのコーディング上は、8Bだったり8Hだったり16Bだったりと表記が混在しとります。慣れないと大混乱?慣れたりしないか、こんな命令。。。
UADDWとUADDW2を図示してみる
今度は要素のビット幅を「広く」する命令です。こちらの場合、一方のソースの幅が「広く」て、他方が「狭い」形です。そして計算すると広い方に「合わせた結果」が得られます。第1ソースが「広い」か、第2ソースが「広い」かでWIDEとLONGの種別あり、「じゃない」方が「狭い」となります。メンドクセーので図示してみます。こんな感じ。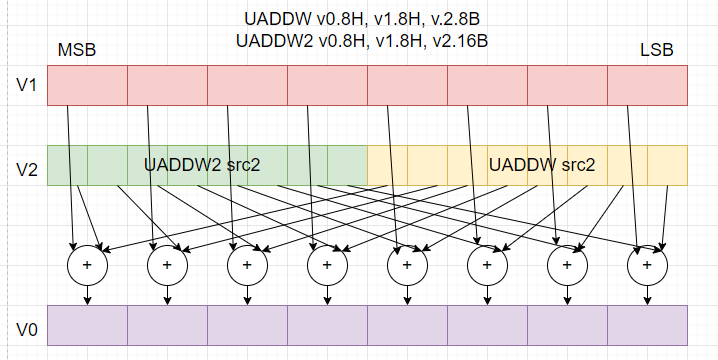
上記は16ビット幅要素に8ビット幅要素を足して結果16ビットになるパターンンです。2がついているのとついていないのは幅が狭い側のソースをレジスタの上側に置くか、下側に置くかの違いです。
ここでも8Hと書くか、8Bと書くか、16Bと書くか混乱します。アセンブラが文句を言ったら考えるっと。
実験に使ったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下です。
.globl addhn8V, addhn28V, uaddw8V, uaddw28V
.text
.balign 4
addhn8V:
ld1 {v1.8H, v2.8H}, [x0], #32
addhn v0.8B, v1.8H, v2.8H
st1 {v0.8H}, [x0]
ret
addhn28V:
ld1 {v1.8H, v2.8H}, [x0], #32
addhn2 v0.16B, v1.8H, v2.8H
st1 {v0.8H}, [x0]
ret
uaddw8V:
ld1 {v1.8H, v2.8H}, [x0], #32
uaddw v0.8H, v1.8H, v2.8B
st1 {v0.8H}, [x0]
ret
uaddw28V:
ld1 {v1.8H, v2.8H}, [x0], #32
uaddw2 v0.8H, v1.8H, v2.16B
st1 {v0.8H}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。Cで書くと今回も何気にメンドイのは、アセンブラへ行って帰ってくると「実際の」変数型が変化してしまうことです。Cのレベルでは全てuint16_t型じゃと割り切って、テキトーに出し入れしてます。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (24)
uint16_t TargetMEM[MAXMEM];
extern void addhn8V(uint16_t *);
extern void addhn28V(uint16_t *);
extern void uaddw8V(uint16_t *);
extern void uaddw28V(uint16_t *);
void initTGT1() {
TargetMEM[0] = 0x0000;
TargetMEM[1] = 0x0000;
TargetMEM[2] = 0x0001;
TargetMEM[3] = 0x0001;
TargetMEM[4] = 0x0080;
TargetMEM[5] = 0x0080;
TargetMEM[6] = 0x0100;
TargetMEM[7] = 0x0100;
TargetMEM[8] = 0x0000;
TargetMEM[9] = 0x00FF;
TargetMEM[10] = 0x0000;
TargetMEM[11] = 0x00FF;
TargetMEM[12] = 0x0000;
TargetMEM[13] = 0x00FF;
TargetMEM[14] = 0x0000;
TargetMEM[15] = 0x01FF;
TargetMEM[16] = 0x0000;
TargetMEM[17] = 0x0000;
TargetMEM[18] = 0x0000;
TargetMEM[19] = 0x0000;
TargetMEM[20] = 0x0000;
TargetMEM[21] = 0x0000;
TargetMEM[22] = 0x0000;
TargetMEM[23] = 0x0000;
}
void initTGT2() {
TargetMEM[0] = 0x0100;
TargetMEM[1] = 0x0100;
TargetMEM[2] = 0x0200;
TargetMEM[3] = 0x0200;
TargetMEM[4] = 0x0300;
TargetMEM[5] = 0x0300;
TargetMEM[6] = 0x0400;
TargetMEM[7] = 0x0400;
TargetMEM[8] = 0x0100;
TargetMEM[9] = 0x0302;
TargetMEM[10] = 0x0504;
TargetMEM[11] = 0x0706;
TargetMEM[12] = 0x0708;
TargetMEM[13] = 0x0708;
TargetMEM[14] = 0x0708;
TargetMEM[15] = 0x0708;
TargetMEM[16] = 0x0000;
TargetMEM[17] = 0x0000;
TargetMEM[18] = 0x0000;
TargetMEM[19] = 0x0000;
TargetMEM[20] = 0x0000;
TargetMEM[21] = 0x0000;
TargetMEM[22] = 0x0000;
TargetMEM[23] = 0x0000;
}
uint16_t getLow(int idx, int pos) {
if (idx & 0x01) {
return (TargetMEM[(idx>>1)+pos] >> 8) & 0xFF;
} else {
return TargetMEM[(idx>>1)+pos] & 0xFF;
}
}
uint16_t getHigh(int idx, int pos) {
if (idx & 0x01) {
return (TargetMEM[(idx>>1)+pos] >> 8) & 0xFF;
} else {
return TargetMEM[(idx>>1)+pos] & 0xFF;
}
}
void dumpTGTL(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%04x opr 0x%04x -> 0x%02x\n", i, TargetMEM[i], TargetMEM[i+8], getLow(i, 16));
}
}
void dumpTGTH(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%04x opr 0x%04x -> 0x%02x\n", i, TargetMEM[i], TargetMEM[i+8], getHigh(i, 20));
}
}
void dumpTGTL2(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%04x opr 0x%02x -> 0x%04x\n", i, TargetMEM[i], getLow(i, 8), TargetMEM[i+16]);
}
}
void dumpTGTH2(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%04x opr 0x%02x -> 0x%04x\n", i, TargetMEM[i], getHigh(i, 12), TargetMEM[i+16]);
}
}
int main(void) {
initTGT1();
addhn8V(TargetMEM);
dumpTGTL("addhn");
addhn28V(TargetMEM);
dumpTGTH("addhn2");
initTGT2();
uaddw8V(TargetMEM);
dumpTGTL2("uaddw");
uaddw28V(TargetMEM);
dumpTGTH2("uaddw2");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdaddhn.c simdaddhn.s $ ./a.out
-
- ADDHN、ADDHN2
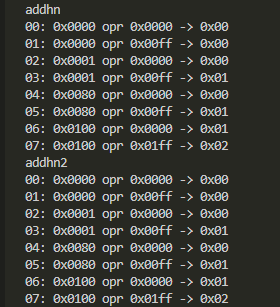
-
- UADDW、UADDW2
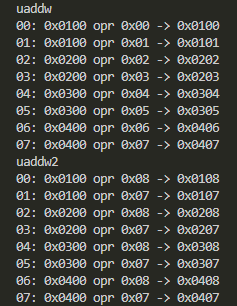
計算は出来たみたい。メンドクセーけど。