前回は、SIMD要素のビット幅が狭く(narrow)なる、広く(wide/long)なる命令の転送パターンを整数加算を例にいくつか練習してみました。今回は、丸め有/丸め無、符合付/符号無、各種組み合わせを練習してみます。題材は整数加算のみなんだけれども。いったいどんだけ組み合わせがあるんじゃ。つくづく命令多過ぎA64。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
ビット幅が狭くなるときの丸め、広くなるときの符号
通常SIMD演算では要素ビット幅は不変ですが、前回から練習している者どもは変化してしまう変わり者どもです。今回は整数Add題材ですが、他の演算でもいろいろあるかと思えば変種多過ぎ。
さて、Addした結果で要素ビット幅が狭くなるときは、計算結果の「MSB側」を取り出すことになっているので、符号を気にする必要はありませぬ。その代わり「下の方」を結果に「どう反映するか」の扱いが2種類あります。こんな感じ。
| result | to the lower half | to the upper half |
|---|---|---|
| truncated | ADDHN | ADDHN2 |
| rounded | RADDHN | RADDHN2 |
下の方を切り捨てしまうのがADDHN、ADDHN2、下の方の最上位ビットをみて結果の最下位ビットに丸めを反映させるのがRADDHN、RADDHN2であると。
一方、Addした結果で要素ビット幅が広くなるときは、符号拡張するのかゼロ拡張で良いのか決めないとなりませんぬ。組み合わせはこんな感じ。
| sign/unsign | from the lower half | from the upper half |
|---|---|---|
| signed Long | SADDL | SADDL2 |
| signed Wide | SADDW | SADDW2 |
| unsigned Long | UADDL | UADDL2 |
| unsigned Wide | UADDW | UADDW2 |
前回もやりましたが、Wideの方はソース1は結果と同じビット幅ですが、ソース2は半分のビット幅です。また、今回練習のLongの方は、ソース1もソース2も結果の半分のビット幅です。ややこしい。。。
実験に使ったアセンブリ言語記述の被テスト関数
いつものように手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下です。メンドクセーのでニーモニックの末尾に「2」がつく方は省略してしまいました。2付やるとケースが倍になるぜよ。そちらは前回記事をご覧くだされや。
.globl addhn8V, raddhn8V, uaddw8V, uaddl8V, saddw8V, saddl8V
.text
.balign 4
addhn8V:
ld1 {v1.8H, v2.8H}, [x0], #32
addhn v0.8B, v1.8H, v2.8H
st1 {v0.8H}, [x0]
ret
raddhn8V:
ld1 {v1.8H, v2.8H}, [x0], #32
raddhn v0.8B, v1.8H, v2.8H
st1 {v0.8H}, [x0]
ret
uaddw8V:
ld1 {v1.8H, v2.8H}, [x0], #32
uaddw v0.8H, v1.8H, v2.8B
st1 {v0.8H}, [x0]
ret
uaddl8V:
ld1 {v1.8H, v2.8H}, [x0], #32
uaddl v0.8H, v1.8B, v2.8B
st1 {v0.8H}, [x0]
ret
saddw8V:
ld1 {v1.8H, v2.8H}, [x0], #32
saddw v0.8H, v1.8H, v2.8B
st1 {v0.8H}, [x0]
ret
saddl8V:
ld1 {v1.8H, v2.8H}, [x0], #32
saddl v0.8H, v1.8B, v2.8B
st1 {v0.8H}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。実際のアセンブリ言語命令では符号付き処理でも、これまた何気にCのレベルでは全てuint16_t型じゃと割り切って書いているもの。面倒くさがり。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (24)
uint16_t TargetMEM[MAXMEM];
extern void addhn8V(uint16_t *);
extern void raddhn8V(uint16_t *);
extern void uaddw8V(uint16_t *);
extern void uaddl8V(uint16_t *);
extern void saddw8V(uint16_t *);
extern void saddl8V(uint16_t *);
void initTGT1() {
TargetMEM[0] = 0x0000;
TargetMEM[1] = 0x0000;
TargetMEM[2] = 0x0001;
TargetMEM[3] = 0x0001;
TargetMEM[4] = 0x0080;
TargetMEM[5] = 0x0080;
TargetMEM[6] = 0x0100;
TargetMEM[7] = 0x0100;
TargetMEM[8] = 0x0000;
TargetMEM[9] = 0x00FF;
TargetMEM[10] = 0x0000;
TargetMEM[11] = 0x00FF;
TargetMEM[12] = 0x0000;
TargetMEM[13] = 0x00FF;
TargetMEM[14] = 0x0000;
TargetMEM[15] = 0x01FF;
TargetMEM[16] = 0x0000;
TargetMEM[17] = 0x0000;
TargetMEM[18] = 0x0000;
TargetMEM[19] = 0x0000;
TargetMEM[20] = 0x0000;
TargetMEM[21] = 0x0000;
TargetMEM[22] = 0x0000;
TargetMEM[23] = 0x0000;
}
void initTGT2() {
TargetMEM[0] = 0x0100;
TargetMEM[1] = 0x01F9;
TargetMEM[2] = 0x0200;
TargetMEM[3] = 0x02F9;
TargetMEM[4] = 0x0300;
TargetMEM[5] = 0x03F9;
TargetMEM[6] = 0x0400;
TargetMEM[7] = 0xFFF9;
TargetMEM[8] = 0x0100;
TargetMEM[9] = 0x0302;
TargetMEM[10] = 0x0504;
TargetMEM[11] = 0xFF06;
TargetMEM[12] = 0x0708;
TargetMEM[13] = 0x0708;
TargetMEM[14] = 0x0708;
TargetMEM[15] = 0x0708;
TargetMEM[16] = 0x0000;
TargetMEM[17] = 0x0000;
TargetMEM[18] = 0x0000;
TargetMEM[19] = 0x0000;
TargetMEM[20] = 0x0000;
TargetMEM[21] = 0x0000;
TargetMEM[22] = 0x0000;
TargetMEM[23] = 0x0000;
}
uint16_t getLow(int idx, int pos) {
if (idx & 0x01) {
return (TargetMEM[(idx>>1)+pos] >> 8) & 0xFF;
} else {
return TargetMEM[(idx>>1)+pos] & 0xFF;
}
}
uint16_t getHigh(int idx, int pos) {
if (idx & 0x01) {
return (TargetMEM[(idx>>1)+pos] >> 8) & 0xFF;
} else {
return TargetMEM[(idx>>1)+pos] & 0xFF;
}
}
void dumpTGTL(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%04x opr 0x%04x -> 0x%02x\n", i, TargetMEM[i], TargetMEM[i+8], getLow(i, 16));
}
}
void dumpTGTH(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%04x opr 0x%04x -> 0x%02x\n", i, TargetMEM[i], TargetMEM[i+8], getHigh(i, 20));
}
}
void dumpTGTL2(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
// printf("%02d: 0x%04x opr 0x%04x -> 0x%04x\n", i, TargetMEM[i], TargetMEM[i+8], TargetMEM[i+16]);
printf("%02d: 0x%04x opr 0x%02x -> 0x%04x\n", i, TargetMEM[i], getLow(i, 8), TargetMEM[i+16]);
}
}
void dumpTGTL3(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%02x opr 0x%02x -> 0x%04x\n", i, getLow(i, 0), getLow(i, 8), TargetMEM[i+16]);
}
}
void dumpTGTH2(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
// printf("%02d: 0x%04x opr 0x%04x -> 0x%04x\n", i, TargetMEM[i], TargetMEM[i+8], TargetMEM[i+16]);
printf("%02d: 0x%04x opr 0x%02x -> 0x%04x\n", i, TargetMEM[i], getHigh(i, 12), TargetMEM[i+16]);
}
}
int main(void) {
initTGT1();
addhn8V(TargetMEM);
dumpTGTL("addhn");
raddhn8V(TargetMEM);
dumpTGTL("raddhn");
initTGT2();
uaddw8V(TargetMEM);
dumpTGTL2("uaddw");
uaddl8V(TargetMEM);
dumpTGTL3("uaddl");
saddw8V(TargetMEM);
dumpTGTL2("saddw");
saddl8V(TargetMEM);
dumpTGTL3("saddl");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdraddhn.c simdraddhn.s $ ./a.out
-
- ADDHN、RADDHN
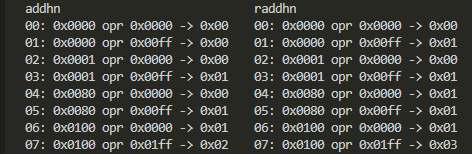
よく見たら切り捨てと丸めの差が分かる、きっと。
-
- UADDL、UADDW、SADDL、SADDW
符合付/符号無で差があるところにお印をつけてみましたぞ。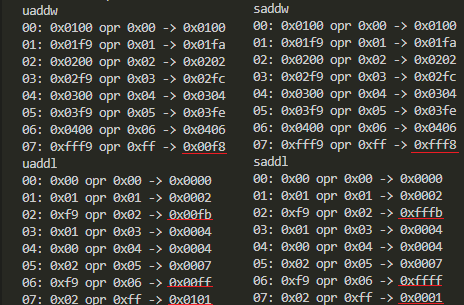
キッチリやったら、これの何十倍もテストケースが膨れ上がるぜよ。メンドクセー。