
前回はSIMDの転置(transpose)命令に「絶対自分じゃ思いつかね~」と感心しました。今回はSIMDでも即値(イミーディエイト)をソースにとる命令群です。たった8ビットなんだけれどもその効果たるや意外と複雑?中でも8ビット即値を浮動小数にエンコードしてロードするFMOV命令にはちょいとてこずりましたぞ。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
今回練習してみるSIMD即値命令群
今回は「第1オペランドで指定したSIMDレジスタ(ベクトル)中の全要素に第2オペランドで指定した単一の8ビット即値を作用させ、SIMDレジスタに書き戻す命令」群です。ニーモニック的には以下の5個です。
-
- BIC
- ORR
- MOVI
- MVNI
- FMOV
ニーモニック的には既に何度も練習したことがあるような気がします。けれどもSIMDの即値命令としては初めてのハズ。SIMDレジスタの要素のビット幅は即値の8ビットより広いのがほぼほぼ当然なので、8ビットをどう当てはめるのか、かなり工夫されている感じの命令です。BIC、ORR、MOVI、MVNIの4命令については第3オペランドに左シフト量をとり(シフト量は0、8、16、24という8ビット単位です)即値は8ビットしかないのだけれども32ビットワードの最上位バイトまで作用させられるようになってます。
BICはビット・クリア、ORRはビット・セットとして要素の一部ビットのみの操作に使用できます。一方MOVI、MVNI(反転MOV)は、即値ロードなので要素のビット幅の全てを使い、「即値をシフトした」値を書き込みます。
最後のFMOV命令は、第2オペランドにとる「8ビット幅の即値からエンコードされる」浮動小数をSIMDレジスタの各要素にロードする命令です。皆さまご存じのとおり単精度の浮動小数の場合、浮動小数点数全体としては以下のビット数が必要です。
-
- 符号ビット1ビット
- 指数部8ビット(値は下駄を履いている)
- 仮数部23ビット(暗黙のビットあり)
8ビット即値では上記全部を埋められないので、「ある決まり」に従って上記ビットにはめ込むことになってます。
馬鹿なので、最初、第2引数を #127 とか「整数の即値」で書いてアセンブラに文句を言われました。
Error: invaild floating-point constant at operand 2
というエラー発生です。よくよく調べてみると機械語命令に埋め込まれる即値は8ビットなのですが、アセンブラで記述する第2オペランドは 小数点を含む記法で書けたのです。#1.0 と書けば浮動小数点数 1.0 がロードされると。
しかし、#1.45 とかテキトーな数を記述するとやっぱり怒られます。こんな感じ。
そのココロは、「8ビットの即値で指定可能な」浮動小数を第2引数に記さねばならんのでした。たとえば
#1.4375
ならばアセンブラは問題なく受け入れてくれます。でも、お惚け老人には8ビット即値に対応する浮動小数を計算するのはツライ、とても無理、と思ったらいつも眺めている命令セットマニュアルの以下の表に「一覧」がありました。
Table C2-2 Floating-point constant values
この表に掲載されている値のみがFMOVが第2引数に受け入れ可能な数値だと。表(符号マイナスも可)にない即値を書くとエラーになります。メンドクセー命令だな、ほんと。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。
.globl bic4V, orr4V, movi4V, mvni4V, fmov4V
.text
.balign 4
bic4V:
ld1 {V0.4S}, [x0]
bic v0.4S, #15, LSL #16
st1 {v0.4S}, [x0]
ret
orr4V:
ld1 {V0.4S}, [x0]
orr v0.4S, #15, LSL #24
st1 {v0.4S}, [x0]
ret
movi4V:
ld1 {V0.4S}, [x0]
movi v0.4S, #129, LSL #8
st1 {v0.4S}, [x0]
ret
mvni4V:
ld1 {V0.4S}, [x0]
mvni v0.4S, #129, LSL #24
st1 {v0.4S}, [x0]
ret
fmov4V:
ld1 {V0.4S}, [x0]
fmov v0.4S, #1.4375
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。
#include <stdio.h>
#include <stdint.h>
#include <math.h>
#define MAXMEM (4)
uint32_t TargetMEM[MAXMEM];
float TargetMEM2[MAXMEM];
extern void bic4V(uint32_t *);
extern void orr4V(uint32_t *);
extern void movi4V(uint32_t *);
extern void mvni4V(uint32_t *);
extern void fmov4V(float *);
void initTGT() {
TargetMEM[0] = 0x12345678;
TargetMEM[1] = 0x9ABCDEF0;
TargetMEM[2] = 0x5A5A5A5A;
TargetMEM[3] = 0xFFFFFFFF;
}
void initTGT2() {
TargetMEM2[0] = 1.0f;
TargetMEM2[1] = 2.0f;
TargetMEM2[2] = 0.5f;
TargetMEM2[3] = 0.25f;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<4; i++) {
printf("%02d: %08x\n", i, TargetMEM[i]);
}
}
void dumpTGT2(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<4; i++) {
printf("%02d: %f\n", i, TargetMEM2[i]);
}
}
int main(void) {
initTGT();
bic4V(TargetMEM);
dumpTGT("bic v0.4S, #15, LSL #16");
initTGT();
orr4V(TargetMEM);
dumpTGT("orr v0.4S, #15, LSL #24");
initTGT();
movi4V(TargetMEM);
dumpTGT("movi v0.4S, #129, LSL #8");
initTGT();
mvni4V(TargetMEM);
dumpTGT("mvni v0.4S, #129, LSL #24");
initTGT2();
fmov4V(TargetMEM2);
dumpTGT2("fmov v0.4S, #1.4375");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdImm.c simdImm.s $ ./a.out
実行結果が以下に。
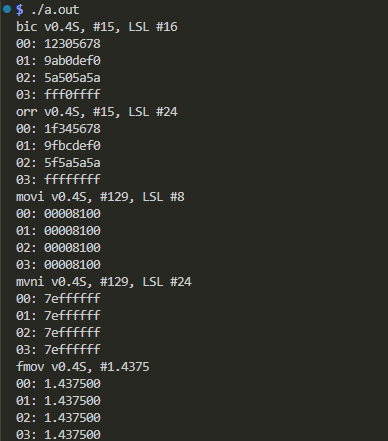 期待どおりね。FMOVにはちょっとてこずったけど、表さえあれば簡単じゃん。
期待どおりね。FMOVにはちょっとてこずったけど、表さえあれば簡単じゃん。