今回はSIMD命令の華「transpose」命令の実習をしたいと思います。転置デス。行列にはつきもののアレです。「簡単な操作」なのでメモリ上の要素をループで読んで順序を変えて書き戻せば可能。でもメモリにアクセスする時間を考えると大変。しかしA64のTRN1、TRN2を使えばレジスタ上で転置ができてしまうっと。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
数学でよく見る図と左右が逆に描いてあり
数学で、N行M列の「行列」を描く場合、以下のように左上に[0,0]要素、右下に[N,M]要素が来るように描くことが多いじゃないかと思います。
A[0,0] A[0,1] ... A[0,M] A[1,0] A[1,1] ... A[1,M] ... ... A[N,0] A[N,1] ... A[N, M]
上記のようなデータ構造をコンピュータ上で実現する場合、使用するコンピュータ言語にもよりますが、[0,0]要素を最もメモリ番地の低いところに置き、以降、[0, 1]…とならべていき、最後(最上位)に[N,M]要素を置くのが一般的かと。
上記のようなメモリ構造からSIMDレジスタ(ベクトルレジスタ)に読み込む場合、例えば4要素のSIMDであれば[0,0]要素がレジスタのLSB側に、[0,3]要素がレジスタのMSB側にロードされます。
そしてレジスタを表記する場合「MSB側を左におく」のがこれまた一般的なので、SIMDレジスタ上に置かれた行列を眺めると「なんだか左右逆転」している感じになってしまいますが、他意はございませぬ。
4x4行列の転置
ということで以下はレジスタ上でのイメージ図です。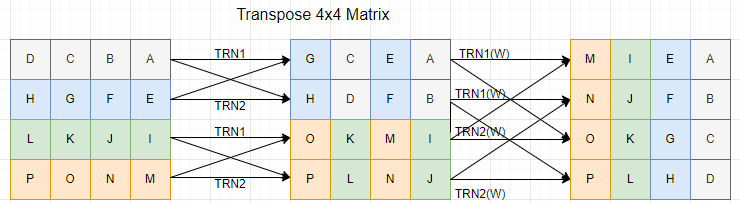
左側が「元の行列」です。右上が[0,0]要素Aで、以降右から左へ、そして下へという方向で最後の[3,3]要素Pまで並んでいます。この状態では4要素のSIMDレジスタ1本毎に色を変えてあります。
さて、最左端の4x4行列にたいして、TRN1命令とTRN2命令を矢印のようなレジスタの組み合わせで適用した結果を真ん中に書いてあります。ここで、TRN1命令とTRN2命令の動作は以下のようです。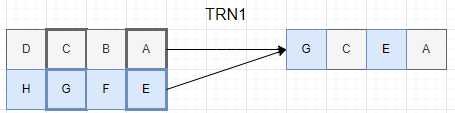
TRN1は引数にとる2つのSIMDレジスタの奇数番目要素をとりだして右のようにならべます。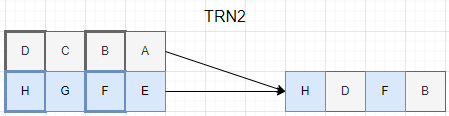
TRN2は引数にとる2つのSIMDレジスタの偶数番目要素をとりだして右のようにならべます。
さて、中間の行列に対して、再度TRN1とTRN2をレジスタの組み合わせを矢印のように変えて実行します。ただし、このときに操作する要素の幅は倍にします。すると右端のようになります。転置されとるがや。狐に化かされたか?
レジスタ上でたった8命令で4x4の転置ができました。4x4の転置ができればこれを単位として処理すれば良いので10000x10000でも10万でも持ってこい!と。
この辺の操作については、Arm御本家の以下のページに解説があります。
上記は2x2行列2個の操作で分かり難い上に、怖れ多いことですが
Figure 15 … TRN1の矢印の一部間違ってるぞ。
です。お惚け老人はFigure 15みて何故としばらく立ち止まってしまいましたぞ。
上記より、以下の先達の方のページ(日本語)の方がはるかに分かり易いかもです(NEONのイントリンシックスを使って書かれてます。当方のようにベタでアセンブラ書くような無作法なことはされてません。)
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。float型の4x4配列をSIMDレジスタ上に持ってきて転置を行ってメモリに戻すもの。
.globl transpose4V
.text
.balign 4
transpose4V:
ld1 {V0.4S, v1.4S, v2.4S, V3.4S}, [x0]
trn1 v4.4S, v0.4S, v1.4S
trn2 v5.4S, v0.4S, v1.4S
trn1 v6.4S, v2.4S, v3.4S
trn2 v7.4S, v2.4S, v3.4S
trn1 v0.2D, v4.2D, v6.2D
trn1 v1.2D, v5.2D, v7.2D
trn2 v2.2D, v4.2D, v6.2D
trn2 v3.2D, v5.2D, v7.2D
st1 {V0.4S, v1.4S, v2.4S, V3.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。4x4行列といいながら、べたな1次元配列で定義してます。
#include <stdio.h>
#include <stdint.h>
#include <math.h>
#define MAXMEM (16)
float TargetMEM[MAXMEM];
extern void transpose4V(float *);
void initTGT() {
TargetMEM[0] = 1.1f;
TargetMEM[1] = 1.2f;
TargetMEM[2] = 1.3f;
TargetMEM[3] = 1.4f;
TargetMEM[4] = 2.1f;
TargetMEM[5] = 2.2f;
TargetMEM[6] = 2.3f;
TargetMEM[7] = 2.4f;
TargetMEM[8] = 3.1f;
TargetMEM[9] = 3.2f;
TargetMEM[10] = 3.3f;
TargetMEM[11] = 3.4f;
TargetMEM[12] = 4.1f;
TargetMEM[13] = 4.2f;
TargetMEM[14] = 4.3f;
TargetMEM[15] = 4.4f;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<4; i++) {
printf("%02d: %4.1f %4.1f %4.1f %4.1f\n", 0, TargetMEM[i*4], TargetMEM[i*4+1], TargetMEM[i*4+2], TargetMEM[i*4+3]);
}
}
int main(void) {
initTGT();
dumpTGT("Before Transpose");
transpose4V(TargetMEM);
dumpTGT("After Transpose");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdTranspose.c simdTranspose.s $ ./a.out
実行結果が以下に。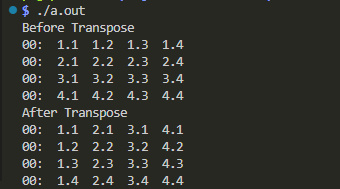
転置されているようだね。華というには地味な気もするが。。。