今回からSIMDレジスタ2個の内容を「混ぜあわせて並び変える」permute命令群の練習に入りたいと思います。SIMD命令でプログラムを書こうとすると避けて通れないどころか、ここの始末のエレガントさで性能段違いっす。まさにSIMDの華というべきか。ホントか?誰が言った?今回はその露払いね。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
Permute命令群
この命令群には以下の7個の命令が含まれます。
-
- EXT、 Extract vector from a pair of vectors
- TRN1、 Transpose vectors (primary)
- TRN2、 Transpose vectors (secondary)
- UZP1、 Unzip vectors (primary)
- UZP2、 Unzip vectors (secondary)
- ZIP1、 Zip vectors (primary)
- ZIP2、 Zip vectors (secondary)
そのうち2番目と3番目こそ、ここの本丸、「転置」命令です。一気に本丸へ攻め込めないので、今回は残りの1、4、5、6、7を練習してみます。
参照しているArm社のマニュアルは、図の一枚でも描いておいてくれたら分かり易いのにと思う命令にも文章だけで素っ気なく通り過ぎることが多いです。しかし、ここPermute一族では珍しく操作の図が描いてあります。図にすれば一目瞭然な操作も文章では凡人は誤解するからかも。
当方も図をでその動作を説明しますが、後で実習するときの数値例に即したものにしてあります。
-
- Ext命令
Ext命令はソース1(以下図では緑)とソース2(以下図では青)を連結してその途中を「抽出」するような操作を行います。以下図の例は #1 を指定して1要素ずらして「抽出する」形の場合です。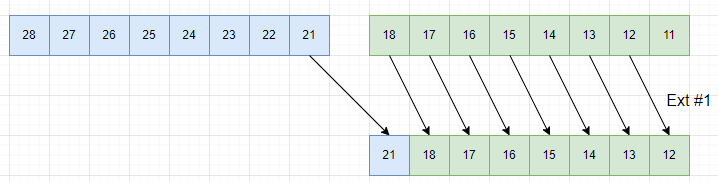
なお、Ext命令の「要素」は常にバイトです。操作対象のSIMDレジスタを128ビット幅で行うか、64ビット幅で行うかの選択ありです。
-
- Uzp1命令、Uzip2命令、Zip1命令、Uzip2命令
操作については下の図をご覧くだされ。UzpとZipがちょうど逆の操作になっていて、ZipしてUzpとか、その逆に戻ることをご確認くだされ。また1と2は偶奇というべきか、ハイ側ロー側というべきかの指定。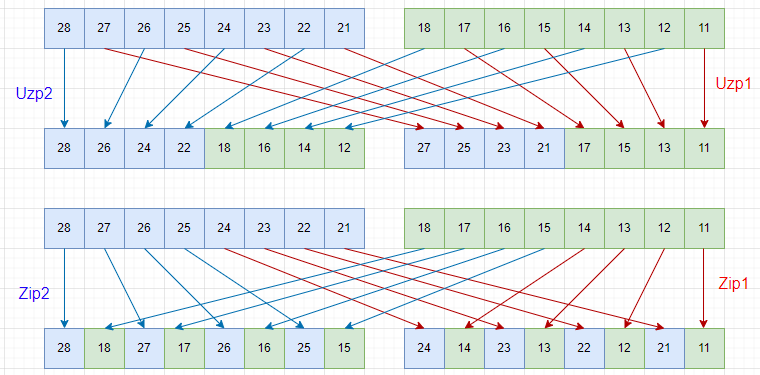
なお、Uzp、Zip命令の「要素」はバイト、ハーフワード、ワードをとることができ、SIMDレジスタは128ビット幅、64ビット幅のどちらでも操作可能です。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。練習は64ビット幅レジスタのみ、バイト要素のみです。
.globl ext8V, uzp18V, uzp28V, zip18V, zip28V
.text
.balign 4
ext8V:
ld1 {V0.8B, v1.8B, v2.8B}, [x0]
ext v0.8B, v1.8B, v2.8B, #1
st1 {v0.8B}, [x0]
ret
uzp18V:
ld1 {V0.8B, v1.8B, v2.8B}, [x0]
uzp1 v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
uzp28V:
ld1 {V0.8B, v1.8B, v2.8B}, [x0]
uzp2 v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
zip18V:
ld1 {V0.8B, v1.8B, v2.8B}, [x0]
zip1 v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
zip28V:
ld1 {V0.8B, v1.8B, v2.8B}, [x0]
zip2 v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。
#include <stdio.h>
#include <stdint.h>
#include <math.h>
#define MAXMEM (24)
uint8_t TargetMEM[MAXMEM];
extern void ext8V(uint8_t *);
extern void uzp18V(uint8_t *);
extern void uzp28V(uint8_t *);
extern void zip18V(uint8_t *);
extern void zip28V(uint8_t *);
void initTGT() {
TargetMEM[0] = 0x00;
TargetMEM[1] = 0x00;
TargetMEM[2] = 0x00;
TargetMEM[3] = 0x00;
TargetMEM[4] = 0x00;
TargetMEM[5] = 0x00;
TargetMEM[6] = 0x00;
TargetMEM[7] = 0x00;
TargetMEM[8] = 0x11;
TargetMEM[9] = 0x12;
TargetMEM[10] = 0x13;
TargetMEM[11] = 0x14;
TargetMEM[12] = 0x15;
TargetMEM[13] = 0x16;
TargetMEM[14] = 0x17;
TargetMEM[15] = 0x18;
TargetMEM[16] = 0x21;
TargetMEM[17] = 0x22;
TargetMEM[18] = 0x23;
TargetMEM[19] = 0x24;
TargetMEM[20] = 0x25;
TargetMEM[21] = 0x26;
TargetMEM[22] = 0x27;
TargetMEM[23] = 0x28;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<8; i++) {
printf("%02d: %02x opr %02x -> %02x\n", 0, TargetMEM[i+8], TargetMEM[i+16], TargetMEM[i]);
}
}
int main(void) {
initTGT();
ext8V(TargetMEM);
dumpTGT("ext v0.8B, v1.8B, v2.8B, #1");
initTGT();
uzp18V(TargetMEM);
dumpTGT("uzp1 v0.8B, v1.8B, v2.8B");
initTGT();
uzp28V(TargetMEM);
dumpTGT("uzp2 v0.8B, v1.8B, v2.8B");
initTGT();
zip18V(TargetMEM);
dumpTGT("zip1 v0.8B, v1.8B, v2.8B");
initTGT();
zip28V(TargetMEM);
dumpTGT("zip2 v0.8B, v1.8B, v2.8B");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdPermute.c simdPermute.s $ ./a.out
Ext命令の実行結果が以下に。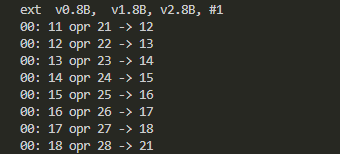
4種のZip、Uzp命令の結果が以下に。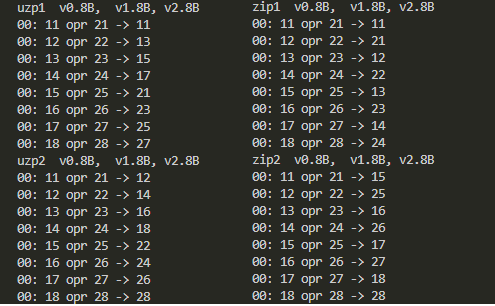
さて次回はお楽しみの転置だな。