どんだけあるんだA64のSIMD即値シフト命令ということですが、後一息デス。今回は残る「ナロー化一族(勝手命名)」を2回に分けて練習する予定の1回目です。ロング化が左シフトのみであったのに対して、ナロー化は右シフトのみです。右シフトした結果のビット幅を半分にして格納するナロー化一族。でもいろいろあるのよ。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
今回練習するナロー化一族の命令
ナロー化一族(以下でNarと記す)はすべて右シフト(以下でRgtと記す)命令です。
上記のように、一番シンプルなのが、SHRNとSHRN2です。SIMDの各要素毎、ソースを即値オペランドで右シフトした結果のビット幅を半分に切り捨てて結果を取り出しデスティネーションに格納します。その際、いつものように
-
- 無印のSHRNは、SIMDレジスタの下半分(LSB側)に結果を格納
- 「2」印のSHRN2は、SIMDレジスタの上半分(MSB側)に結果を格納
というスタイルでビット幅半分になった要素どもを格納します。
今回は、上記のSHRN、SHRN2に、以下の「オプション」をつけたものたちを練習します。
-
- RSHRN、RSHRN2、結果を丸める
- SQSHRN、SQSHRN2、ソースを符号付数とみてシフト結果を飽和させる
- UQSHRN、UQSHRN2、ソースを符号無数とみてシフト結果を飽和させる
「オプション」一つづつなので、今回は単純明快なんであります。「複数重なっていて込み入った命令ども」が8個もあるのですが、次回です。恐ろしいなA64。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。当然SIMD要素幅はいろいろとれるのですが、いつもの手抜きでソース要素のビット幅はワード(32bit)のみです。今回はナロー一族なので、連動してデスティネーション要素のビット幅はハーフワード(16bit)のみとなります。
.globl shrn4V, shrn24V, rshrn4V, rshrn24V, sqshrn4V, sqshrn24V, uqshrn4V, uqshrn24V
.text
.balign 4
shrn4V:
ld1 {v0.4S, v1.4S}, [x0]
shrn v0.4H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
shrn24V:
ld1 {v0.4S, v1.4S}, [x0]
shrn2 v0.8H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
rshrn4V:
ld1 {v0.4S, v1.4S}, [x0]
rshrn v0.4H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
rshrn24V:
ld1 {v0.4S, v1.4S}, [x0]
rshrn2 v0.8H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
sqshrn4V:
ld1 {v0.4S, v1.4S}, [x0]
sqshrn v0.4H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
sqshrn24V:
ld1 {v0.4S, v1.4S}, [x0]
sqshrn2 v0.8H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
uqshrn4V:
ld1 {v0.4S, v1.4S}, [x0]
uqshrn v0.4H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
uqshrn24V:
ld1 {v0.4S, v1.4S}, [x0]
uqshrn2 v0.8H, v1.4S, #8
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。今回も、扱うデータが符号付でも符号無でもCのデータ型などは踏みつぶしてしまって全てuint32_t型にしてあります。符号付きか符号無かは各自HEX表記を見て理解する、ということで。いつもの手抜きだよ。
#include <stdio.h>
#include <stdint.h>
#include <math.h>
#define MAXMEM (8)
uint32_t TargetMEM[MAXMEM];
extern void shrn4V(uint32_t *);
extern void shrn24V(uint32_t *);
extern void rshrn4V(uint32_t *);
extern void rshrn24V(uint32_t *);
extern void sqshrn4V(uint32_t *);
extern void sqshrn24V(uint32_t *);
extern void uqshrn4V(uint32_t *);
extern void uqshrn24V(uint32_t *);
void initTGT() {
TargetMEM[0] = 0x11111111;
TargetMEM[1] = 0x11111111;
TargetMEM[2] = 0x11111111;
TargetMEM[3] = 0x11111111;
TargetMEM[4] = 0x00345678;
TargetMEM[5] = 0x9ABCDEF0;
TargetMEM[6] = 0xCCCC008D;
TargetMEM[7] = 0xFFFF000E;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i<4; i++) {
printf("%02d: %08x\n", i, TargetMEM[i]);
}
}
int main(void) {
initTGT();
shrn4V(TargetMEM);
dumpTGT("shrn v0.4H, V1.4S, #8");
initTGT();
shrn24V(TargetMEM);
dumpTGT("shrn2 v0.8H, V1.4S, #8");
initTGT();
rshrn4V(TargetMEM);
dumpTGT("rshrn v0.4H, V1.4S, #8");
initTGT();
rshrn24V(TargetMEM);
dumpTGT("rshrn2 v0.8H, V1.4S, #8");
initTGT();
sqshrn4V(TargetMEM);
dumpTGT("sqshrn v0.4H, V1.4S, #8");
initTGT();
sqshrn24V(TargetMEM);
dumpTGT("sqshrn2 v0.8H, V1.4S, #8");
initTGT();
uqshrn4V(TargetMEM);
dumpTGT("uqshrn v0.4H, V1.4S, #8");
initTGT();
uqshrn24V(TargetMEM);
dumpTGT("uqshrn2 v0.8H, V1.4S, #8");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdSFTImm7.c simdSFTImm7.s $ ./a.out
標準出力に現れた結果を比較しやすいように上下2段x横4列にしてみました。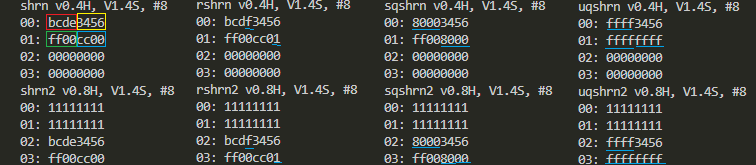 注目するところに色つけてあります。
注目するところに色つけてあります。
まず上下ですが、上の無印命令の系統は128ビット幅のSIMDレジスタの下の方64ビットに結果を格納していることが分かると思います。上の64ビットにはゼロづめです。
一方、下の「2」印の命令の系統は、SIMDレジスタの上の64ビットに結果を格納しています。そして下の64ビットは、以前の値が維持されてます。上記で0x11111111というのは「以前の値」です。
左端は何もしない素のナロー化右シフトです。32ビット値を右シフトした後、下の16ビットを取り出してデスティネーションに書き込んでます。
左から2つめは丸めです。右シフトして右に消えたハズのビット(の最上位)を見て結果の最下位ビットに+1されることがあります。「素の」ときと違うところに下線引いてあります。
左から3つ目は符号付のサチュレーション(飽和)です。符号付16ビット数の最大、最小を超えた場合にサチュレーションを行ってます。やはり「素の」ときと違うところに下線引いてあります。
右端は符号無のサチュレーション(飽和)です。シフト結果が16ビットに収まらない場合にサチュレーションを行ってます。やはり「素の」ときと違うところに下線引いてあります。
まあ、これでも「シンプル」な方。次回が恐ろしいぞ。