「サイエンティフィックPythonのための」IDE、Spyder上にてScientific Python Lectures様のレクチャ実習中。NumPyの実習7回目です。今回は外部からNumpy配列にデータを「輸入」したいと思います。輸出元はR言語のサンプルデータベースです。テキストファイル経由なので何でもアリ?だと。
※「 ソフトな忘却力」投稿順 Index はこちら
※レクチャ実習中といっても、「準拠」しているのはレクチャの章立てくらいです。Scientific Python Lectures様のコースは例題だけでなく、エクササイズなども充実、それを全部順番に解いていったら必ずや立派な人になれるだろ~とは思います。でもキチンとやったら、死ぬまでに終わらない、と手抜き正当化。
Cars93「サブセット」サンプルデータベース
統計に非常な強みを持つR言語にはサンプルデータベースが大量に存在します。今回輸入を試みたのは、これまた大量に存在するR言語向けのパッケージの中からMASSパッケージの中のCars93というサンプルデータベースです。たまたま直近の別シリーズで取り扱っていたためです。別シリーズ記事が以下に。
データのお砂場(188) R言語、Cars93、1993年の乗用車のスペック {MASS}
データセットについては上記の記事をご参照くだされ。
さてこのデータベースの変数はかなり多いので、単なる操作練習にはツーマッチだと。そこで、R言語から輸出する前に以下のように加工してサブセット化してます。
library(MASS, lib.loc = "C:/Program Files/R/R-4.4.1/library")
data("Cars93")
Cars93txt <- Cars93[,c(12,13,25)]
write.csv(Cars93txt, file="Cars93txt.csv")
サブセット化されたデータベースをR言語処理系のGUI(RStudio)上で観察した結果が以下に。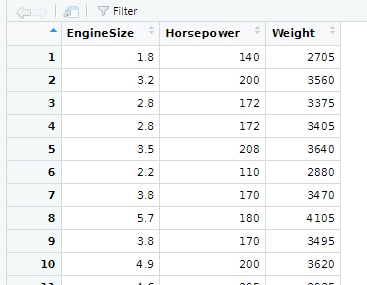
上記の操作によりファイルに書き出された Cars93txt.csv なるCSV形式のテキストファイルの冒頭部分は以下のようです。
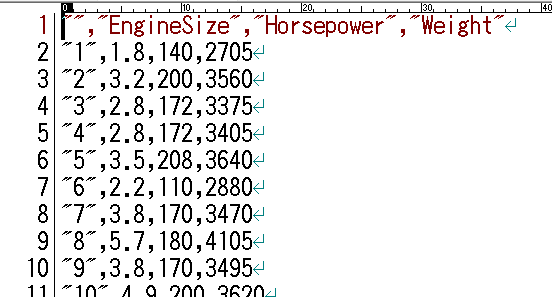
NumPy配列へのテキストファイル読み込み
R言語から書き出されたテキストファイルの行、列には、文字列でラベルが与えられています。とりあえずこいつらは不要、数値データのみ読み込みます。また、CSV形式なので「デリミタはカンマ」っす。そこで NumPyへの指示は以下です。
data = np.loadtxt('Cars93txt.csv', delimiter=',', skiprows=1, usecols=(1,2,3))
これで 変数 data にデータ配列として読み込めた筈。Spyderの変数エクスプローラで開いてみるとこんな感じ。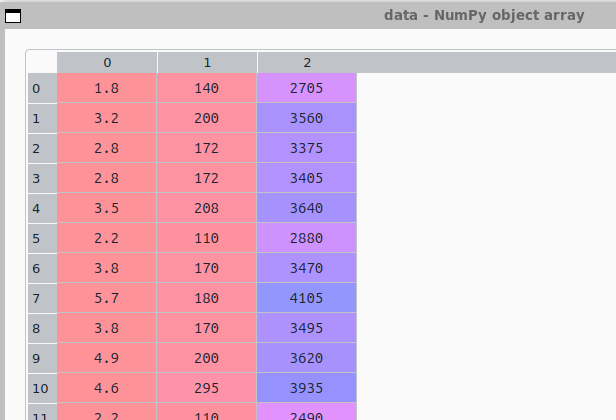
ちゃんとデータの輸入できたみたい。でもSpyderの表示の方がハデだな。