ついにSIMDレジスタへのベクトルロード命令へと進出?いたしました。4命令LD1、LD2、LD3、LD4と並んでいるうち、今回は最初のLD1を動かしてみたいと思います。「1」なんて簡単だろ~と思うなかれ。相手はベクトルっす。メンドイ奴らです。その上、ロードされた様子を観察するだけでも一苦労(特に老眼の目には)
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
SIMDレジスタへのベクトルロード
まずお断りしておくと、ベクトルロード命令にはベクトルロードなりのアドレシングモードがあるようなのです。当然、続けざまにロードを繰り返したりしたいだろうし。でも今回はベクトルロードの初回なのでアドレシングモードはベースレジスタだけ、No Offsetモードで実習してみます。
ニーモニック的にはLD1からLD4の4種存在するのですが、1とか4とか言っているのは「構造」に含まれる要素数です。レジスタの長さでもベクトルの長さでもありません。1構造に1要素しか入っていなければLD1、1構造に4要素入っていればLD4てな塩梅です。例えば1構造に4個の単精度浮動小数が入っているなどということも想定内です。そのため恐ろしい(?)ことにLD1命令でも
-
- 複数のレジスタを連続してロードできる(No Offsetでも)
- 「ベクトルの長さ」ならば最大64要素を1命令で扱える
ということになってます。LD1恐るべし。
SIMDレジスタの観察もメンドイ
さて、SIMDレジスタへのロードですが、SIMDレジスタ上で複数要素を扱う関係上、レジスタイメージで値がどこにロードされているのか確認したいです。そのため、SIMDレジスタの観察をデバッガ (gdb) 使って行うことにいたしました。しかし、
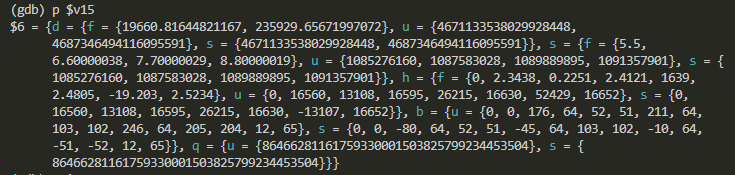
1本のSIMDレジスタ(128ビット)はバイトからクワッドワードまでのビット幅解釈があり、浮動小数、整数の両表現があり得、当然、符号無、符号付きもあるので、gdbのレジスタ表示はとても長い
デス。老眼の目には過ぎたる表記なんであります。以下では注目すべき値のところにマーカーで色をつけて分かりやすくしたつもりですが、だいたい老眼でよく見えてないので見逃してるかも。
今回実験のアセンブリ言語関数
「いつものように手抜きな」関数プロローグ無、エピローグ無の被テスト関数群が以下に。今回は特に、実行結果をC言語のmain関数に戻すことを諦め、デバッガでレジスタを観察するだけにしているので、被テスト命令以外は空虚。
SIMDレジスタの表記のメンドクささの部分をご覧くだされや。
.globl fld1R1S0, fld1R1S1, fld1R2S2, fld1R2S4
.text
.balign 4
fld1R1S0:
ld1 {v10.S}[0], [x0]
ret
fld1R1S1:
ld1 {v11.S}[1], [x0]
ret
fld1R2S2:
ld1 {v12.2S, v13.2S}, [x0]
ret
fld1R2S4:
ld1 {v14.4S, v15.4S}, [x0]
ret
一応コメントしておくと
{v10.S}[0] は、ベクトルレジスタの10番目(0から数えて)のレジスタv10を単精度浮動小数Sが詰まっているとしたときの第0番要素(LSB側)ってこってす。書いているだけで疲れてしまう。
{v12.2S, v13.2S}は、ベクトルレジスタの12番目と13番目の2本を連続。ただし、SIMDレジスタは64ビット幅のモードで単精度浮動小数2要素づつだと。
{v14.4S, v15.4S}は、ベクトルレジスタの14番目と15番目の2本を連続。ただし、SIMDレジスタは128ビット幅のモードで単精度浮動小数4要素づつだと。
ld1といいつつ、数える「単位」が1要素ずつなだけで、随分な数の要素を連続して扱えてしまいます。
C言語記述のmain関数
今回のmain関数は外形だけ。gdbで起動するための入れ物みたいなもんです。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (8)
float TargetMEM[MAXMEM];
extern void fld1R1S0(float *);
extern void fld1R1S1(float *);
extern void fld1R2S2(float *);
extern void fld1R2S4(float *);
void initTGT(float c) {
for (int i=0; i < MAXMEM; i++) {
TargetMEM[i] = c * (i+1);
}
}
int main(void) {
initTGT(1.111f);
fld1R1S0(TargetMEM);
initTGT(2.001f);
fld1R1S1(TargetMEM);
initTGT(1.001f);
fld1R2S2(TargetMEM);
initTGT(1.1f);
fld1R2S4(TargetMEM);
return 0;
}
gdbで動作確認
ビルド後、gdbで命令単位のステップ実行を行い、SIMDレジスタが変化する様子を観察してみます。まずは起動から。
最初に観察すべき被テスト関数の呼び出し部分にブレークポイントをちりばめたうえ、停止の度にアセンブリ言語命令とPCの値を表示するようにおまじないをしかけてから run だと。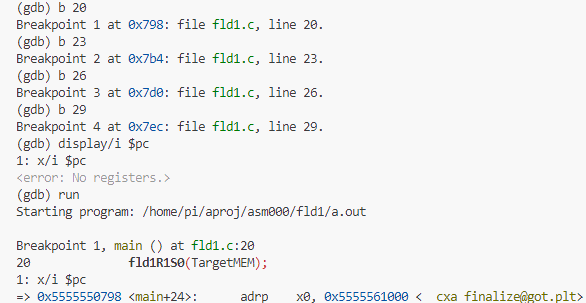
ブレークポイントで止まった後は、stepiを何度か繰り返して、ターゲットの命令のところまで行きます。ターゲットにたどり着いたら、該当命令実行前にこれからロードするメモリアドレスに何が入っているのか(黄色のマーカ)を確認し、ターゲット命令を実行、その直後のSIMDレジスタの様子を観察します。こんな感じ。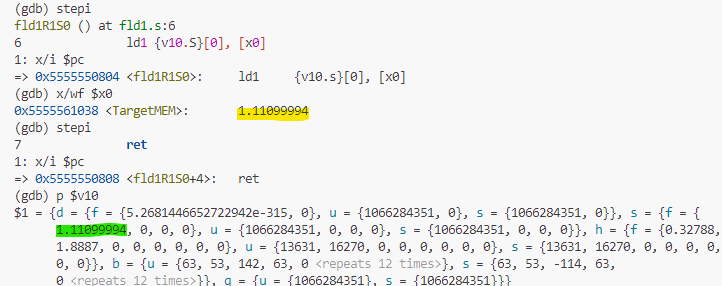
黄色のデータが、緑のレジスタ要素にロードされているのが分かりますか?上記はv10.s[0]に1要素のみのロード。
v10.s[0]では普通にスカラーロードと同じ場所でつまりませぬ。1本のSIMDレジスタの中の2番目の要素v11.s[1]に向けてロードしてみます。要素は1個だけどもベクトルロードね。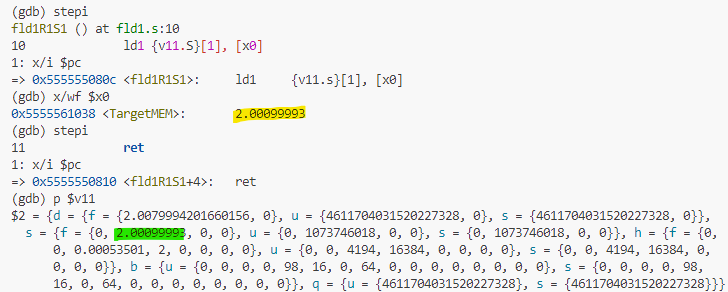
緑色のマーカ部分が2番目のSIMD要素であることが分かりますか。こうすればお好みの要素に1個1個アクセスすることもできると。
しかしね、ベクトルというからには複数要素を一気にロードしたいデス。以下では、v12とv13に単精度浮動小数を詰め込んでますが、「.2s」ということで1レジスタに2要素の「幅狭」モードです。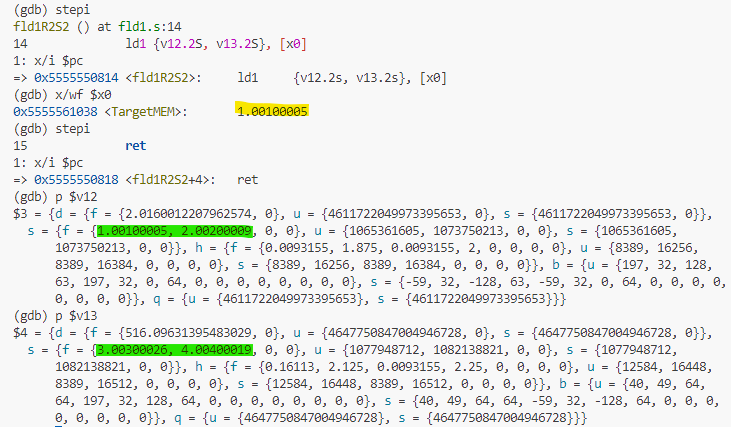
2レジスタに各2要素(LD1なので1構造=1要素)、合計4要素を1命令でロードできました。
もう一丁ということで、1レジスタに各4要素、4x2レジスタで8要素をロード一撃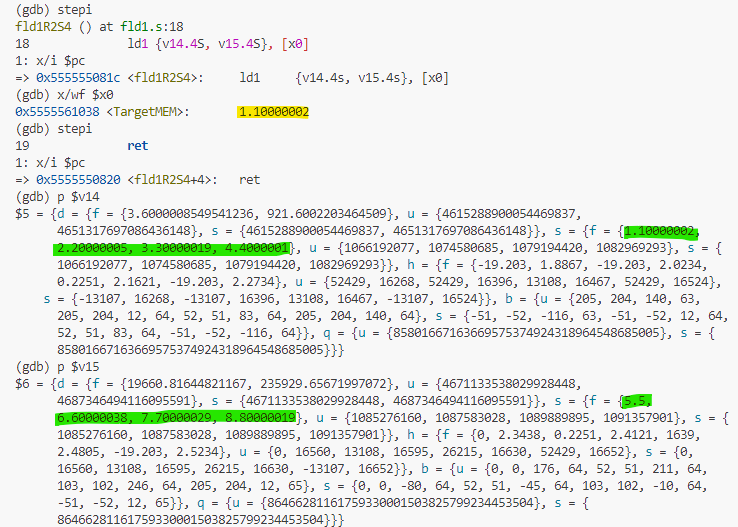 が以下に。
が以下に。
いろいろ出来るのは分かったデス。でも同時指定可能なレジスタはもっと多いし、当然単精度だけでなく、バイトかクワッドワードまであり~の。おまけにインデックスアドレシングもあり。目が回ります。次回が思いやられるな。