前回はLD1命令を練習。1ストラクチャが1要素の一番「シンプル」なベクトルロード命令です。今回はLD1と対になるST1命令をつかってベクトルストアを練習してみます。ベクトルロードしたものを即ストア。折角なので前回未使用だったポスト・インデックス・アドレシングも使用。「シンプル」といいながら1命令の動作がデッカイドー。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
ベクトル・ストア命令と今回実験の関数
ベクトル・レジスタをオペランドにとるベクトル・ストア命令は、前回のベクトル・ロード命令同様、各要素、バイトからクワッドワードまでのビット幅に対応しています。全部練習するのはメンドイので前回同様に単精度浮動小数(ワード幅、32ビット)だけを練習してお茶を濁します。てへ。
LD1命令でメモリからロードしたベクトルをST1命令でメモリにストアするのですが、同じメモリアドレスに書き戻したのではなんだか分からないので、LD1命令のアドレシングモードにポスト・インデックスを採用し、ロード後のアドレス・レジスタの内容をロードしたベクトルの長さ分ずらしてみます。なお、ポストインデックス処理のアドレス確認のため fld1R4S4p という関数を設けてます。
また、LD1もST1もターゲットとなるレジスタは4本までとれるので、今回はフルに4本ロードして4本ストアすることにしてみます。
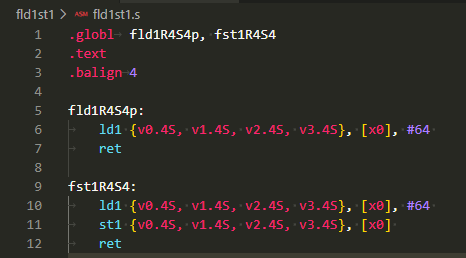
結果、「いつものように手抜きな」関数プロローグ無、エピローグ無の被テスト関数ですが、64バイト(単精度浮動小数16個)を一気にロード、および一気にロードしてストアするものが以下に。
.globl fld1R4S4p, fst1R4S4
.text
.balign 4
fld1R4S4p:
ld1 {v0.4S, v1.4S, v2.4S, v3.4S}, [x0], #64
ret
fst1R4S4:
ld1 {v0.4S, v1.4S, v2.4S, v3.4S}, [x0], #64
st1 {v0.4S, v1.4S, v2.4S, v3.4S}, [x0]
ret
C言語記述のmain関数
前回、ベクトルレジスタの内容を直接 gdb で観察したのが、老眼の目に辛かったので、今回はメモリにストアしてprintfで表示してます。この方がお楽(かといって一致比較までソフトで完結してしまうと楽しくないし。)
最初に、ベクトルロード命令のポスト・インデックス・アドレシングでx0が更新されることを確認、つづいて「ロードしたものを即ストア」してみます。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (32)
float TargetMEM[MAXMEM];
extern float * fld1R4S4p(float *);
extern void fst1R4S4(float *);
void initTGT(float c) {
for (int i=0; i < MAXMEM; i++) {
TargetMEM[i] = c * (i+1);
}
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < MAXMEM; i++) {
printf("%d: %f\n", i, TargetMEM[i]);
}
}
int main(void) {
float * adr = NULL;
initTGT(1.001f);
printf("TargetMEM ADR=0x%016lx\n", TargetMEM);
adr = fld1R4S4p(TargetMEM);
printf("POST-INDEX ADR=0x%016lx\n", adr);
dumpTGT("Before STORE");
fst1R4S4(TargetMEM);
dumpTGT("After STORE");
return 0;
}
ビルドして実行
コンパイルと実行の最初の部分が以下に。与えたメモリアドレスがPOST-INDEXで0x40バイト(64バイト)分ズレたのが分かりますかね。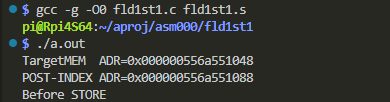
つづいて以下はロード、ストアのメモリ領域の初期値です。このうち先頭側の16個のデータをベクトルレジスタに1命令でロードし、その後、後ろの16個のデータに上書きする予定っす。まずは初期値を覚えて?おいてくだされ。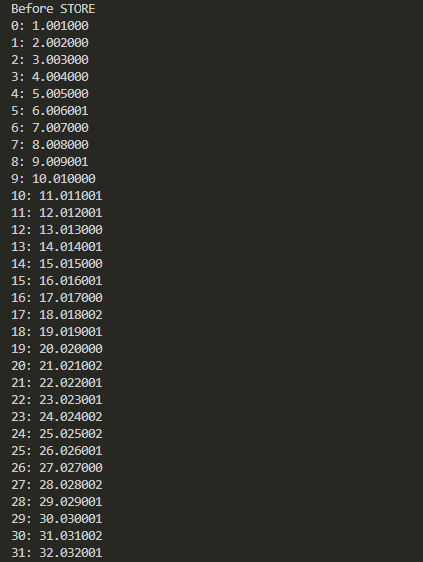
ロードして即ストアの結果が以下に。後半の16個のデータが書き換わっているのがわかりますか。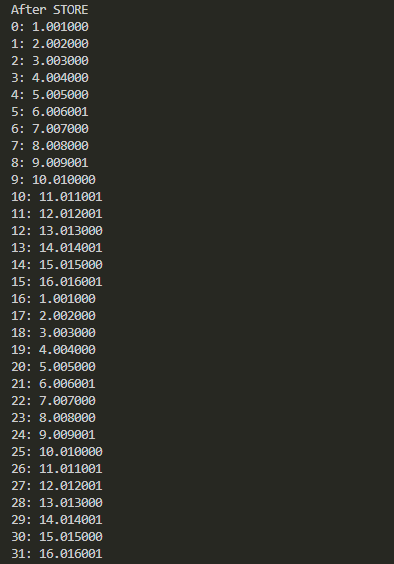
ロードしたものを即ストアしただけ、一気に64バイトだけれども。