前回までベクトルロード/ストアは「1要素」のLD1/ST1命令使ってました。しかしA64の命令セットには1要素から4要素まで、ロードはLD1からLD4、ストアはST1からST4まであるのです。今回はLD3命令を使って「3要素」のときの動作を確認してみます。キーワードは de-interleaving とな。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
de-interleaving
A64のベクトルロード、ストア命令の動作は、図にすれば一目瞭然なのだけれど、言葉では説明がムツカシくなる事柄じゃないかと思います(国語力が無いだけ?)今回は、LD3命令でも単精度浮動小数引数の場合を練習しているので、今回例をそのまま図にしてみました(LD3にしたのは上記のArm社マニュアルのLD3の項にだけ図が載っていて分かりやすいからです。)こんな感じ。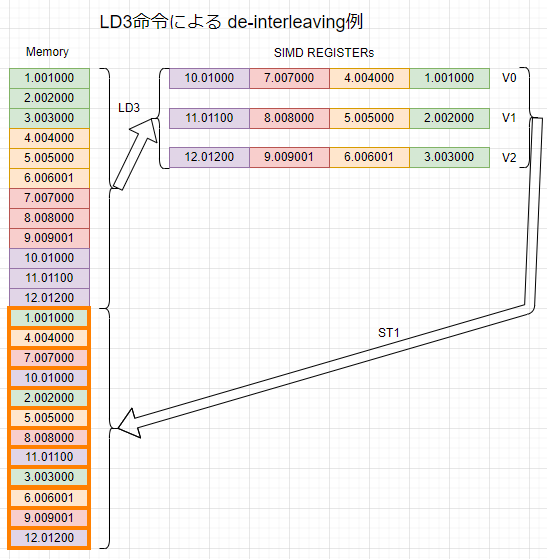
左側にMemoryとあるのがMemoryの「イメージ」です、上がアドレスの小さい側で下がアドレス大。単精度浮動小数なので各箱は4バイトです。そこに「並び順が分かりやすい」単精度浮動小数点数がつめこまれています。LD3命令をつかって3要素x4組=合計12の単精度浮動小数点数(計48バイト)をベクトル・ロードしてみます。転送先はV0、V1、V2の3本のSIMDレジスタです。
SIMD REGISTERsのところに3本のレジスタ「イメージ」が描かれています。1本のレジスタは128ビット幅なので、1本に4個の単精度浮動小数点数が格納できます。上図では右LSB、左MSBです。このような並び順にすることが「デ・インターリービング」であるようです。知らんけど。
ST1命令を使えば、この並び順のままメモリへ格納することができるので右側の矢印のところで、オレンジ色のメモリ箱へストアしています。メモリの上と下を比べると並び順が変わったのがよく分かると思います。
SIMDの場合、演算する要素同士は異なるレジスタの同じレーンに存在していないとならないです。メモリ上の並び順通りでは計算しずらい場合もままあるので、この手の並び順の変更が1命令で出来るのはありがたいことかと。でもRISCにしちゃ随分複雑な命令っすけど。
実験につかったアセンブリ言語記述の被テスト関数
例によって、手抜きの関数プロローグ、エピローグ無の被テスト関数です。ld3命令をつかってx0でアドレス指定されたメモリから3本のベクトルレジスタに単精度浮動小数点数をロードしてます。前回やったポスト・インデックスアドレスを使っているので、命令実行後、x0が保持しているポインタは+48(バイト)進みます。
LD3の直後にST1しているので、こんどはベクトルレジスタのイメージそのままの並び順で+48されたアドレスに値が書き戻されます。
.globl fld3R3S4
.text
.balign 4
fld3R3S4:
ld3 {v0.4S, v1.4S, v2.4S}, [x0], #48
st1 {v0.4S, v1.4S, v2.4S}, [x0]
ret
C言語記述のmain関数
前回コードのチョイ直しのmain関数が以下に。LD3+ST1をやる前のメモリをダンプ、LD3+ST1をやった後のメモリをダンプというお手軽コードです。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (24)
float TargetMEM[MAXMEM];
extern void fld3R3S4(float *);
void initTGT(float c) {
for (int i=0; i < MAXMEM; i++) {
TargetMEM[i] = c * (i+1);
}
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < MAXMEM; i++) {
printf("%d: %f\n", i, TargetMEM[i]);
}
}
int main(void) {
float * adr = NULL;
initTGT(1.001f);
dumpTGT("Before LD3");
fld3R3S4(TargetMEM);
dumpTGT("After LD3");
return 0;
}
実験結果
以下のようにしてビルドして実行しています。
$ gcc -g -O0 fld3.c fld3.s $ ./a.out
標準出力にたれ流された結果をBeforeAfterで比べ易いように並べたものが以下に。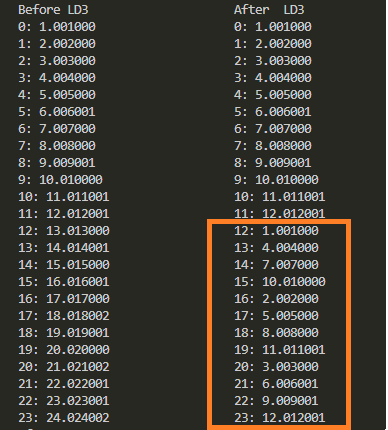
LD3+ST1で並び順ががらっと変更されているのが分かりますな。強力。