前回のキモは「デ・インタリーブ」でしたが、今回は「レプリケーション」です。同じ要素を全てのレーンに複製して書き込むもの。前回の「デ・インタリーブ」が要素の個数に応じてLD1からLD4まで4通りあったのと同様、今回もLD1RからLD4Rまで4通りの命令が存在します。SIMD計算するときには「アリガチ」な操作ね。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
Load single structure and replicate
この命令群の動作は以下の例のLD1R部分をご覧いただけば一目瞭然だと思います。1個の値を全部のレーンに複製ロードするもの
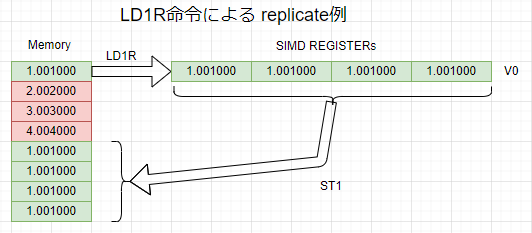
LD1Rは、1要素を1レジスタの全レーンにロードする命令ですが、LD2Rは、2要素を2レジスタの全レーンにロード、以下同文でLD4R命令まで存在します。
このような操作は、端的なところでいうと「ベクトル」の「スカラー」倍操作の「スカラー」部分をセットするのに使えたりします。前回やったLD1からLD4の操作が「ベクトル」部分のセットに使えるのと対になっとります。
SIMDでデータ処理をする際には結構よくある操作じゃないかと思います。
実験につかったアセンブリ言語記述の被テスト関数
例によって、手抜きの関数プロローグ、エピローグ無の被テスト関数です。本来はバイト整数から倍精度浮動小数まで複製するデータの幅はいろいろとれるのですが、例によって単精度浮動小数だけデス。
アドレシングモードなどはほぼLD1命令などと近いのですが、アセンブラを書いていて即値インデックスできる範囲に違いがあることに気づかされました。以下のようなエラーが出たので。
前回はLD1命令に即値で#48などとオフセットを与えてポストインデックスして問題なかったのですが、LD1R命令の場合、上記のように#16でインバリッドになってしまいます。取りうる値は、#1、#2、#4、#8の4種類でした。これは、「単一の値」を複製してロードするので単一の値のビット幅だけポストインデックスできれば良いということだと思います。
実験に使ったソースが以下に(前回ソースのチョイ変デス。)
.globl fld1RS4
.text
.balign 4
fld1RS4:
ld1r {v0.4S}, [x0], x1
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
これまた前回コードのチョイ直しのmain関数が以下に。LD1Rをやる前のメモリをダンプ、LD1R+ST1をやった後のメモリをダンプというお手軽コードです。前述の「LD1R命令によるreplicate例」と同様な動作が観察される筈のもの。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (8)
float TargetMEM[MAXMEM];
extern void fld1RS4(float *, uint64_t idx);
void initTGT(float c) {
for (int i=0; i < MAXMEM; i++) {
TargetMEM[i] = c * (i+1);
}
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < MAXMEM; i++) {
printf("%d: %f\n", i, TargetMEM[i]);
}
}
int main(void) {
float * adr = NULL;
initTGT(1.001f);
dumpTGT("Before LD1R");
fld1RS4(TargetMEM, 16);
dumpTGT("After LD1R");
return 0;
}
実験結果
以下のようにしてビルドして実行しています。
$ gcc -g -O0 fld1r.c fld1r.s $ ./a.out
標準出力にたれ流された結果が以下に。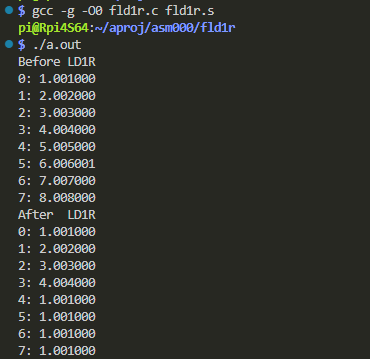
予定通りに「レプリケート」されてるみたい。