前回 http requestノードを使ってWebサイトにアクセスできることを確かめました。今回はWebサイトから取得したxmlファイルを処理するために xml(パーサ)ノードを使ってみます。なるべくホンマ物のデータを処理したかったのですが、外部のサイトにご迷惑かけぬよう、一端ダウンロードしたファイルをローカルに保存して処理しています。
※「ブロックを積みながら」投稿順 index はこちら
前々から、地震、火山などの情報には関心を持っていました。自分なりに情報整理したいという希望もあり、今回サンプルデータとして以下の気象庁のXMLデータ提供ページから「地震火山」に関する「長期フィード」1ファイルをダウンロードさせていただきました。
2次的な利用が許されているとは言え、「適切な利用をお願い」されており、「誤った利用の無いよう」に要請されてもいるので、サンプル処理の結果については「ボカシて」おります。
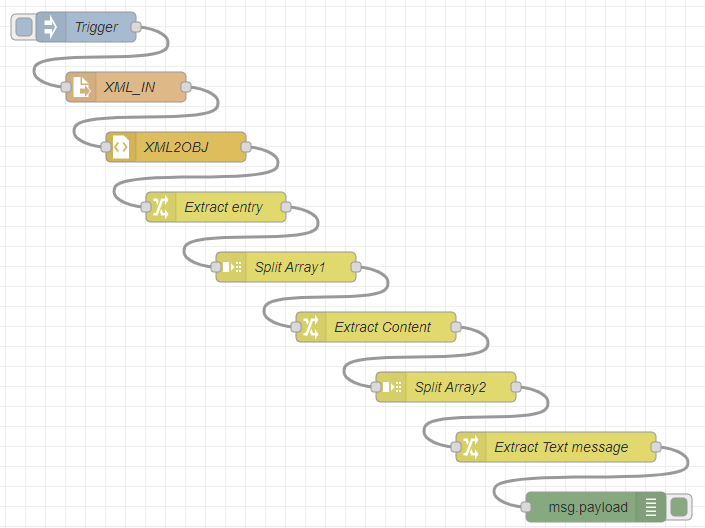
処理フロー
冒頭のアイキャッチ画像に処理フローを掲げました。以下の1本道であります。
-
- Injectノード、サンプルフローを起動する「手動」トリガ
- file in ノード、ローカルファイルシステムからのXMLファイル読み出し
- xml(パーサ)ノード、XMLファイルをJSONオブジェクトに変換
- changeノード、JSONオブジェクト内の実データ配列を抽出
- splitノード、上記の配列を要素(オブジェクト)に分割
- changeノード、上記のオブジェクト内のデータ構造配列を抽出
- splitノード、上記の配列を要素(オブジェクト)に分割
- changeノード、オブジェクト内の文字列部分を抽出
- debugノード、文字列を表示
うち1,5,7,9は特に何の設定もしていないデフォルトのままのノードであるので、それ以外の設定を見ていきます。
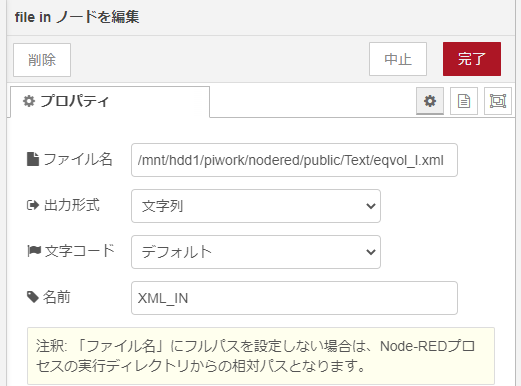
file inノード
この部分をhttp requestノードに置き換えれば、ネットからファイルを取ってこれる筈ですが、今回はローカルストレージに確保したファイルをfile in ノードで取り出して処理しています。出力形式は文字列でそのまま下流に垂れ流しです。
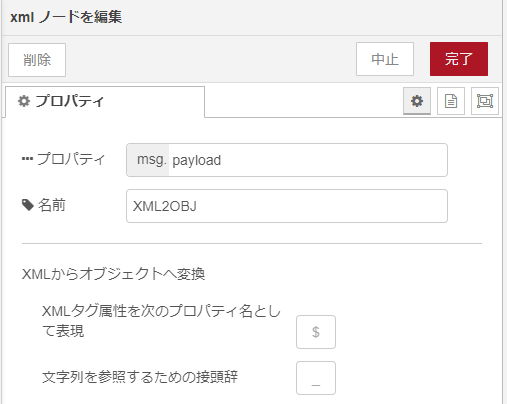
xml(パーサ)ノード
上流から文字列として落ちてきたXMLファイルの実体をオブジェクト(JSON)へと変換するパーサとして使っています。このノードは入力にオブジェクトを与えると出力としてXMLを得ることもできるようです。
なお、XMLからオブジェクトへのデフォルト設定での変換時には、以下の設定に見えるようにタグ属性は $ という名のプロパティに、文字列は _ という名のプロパティに変換されます。後で抽出するときに参照することになります。
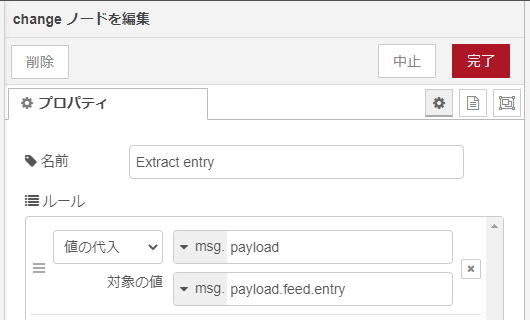
changeノード(その1)
取得したXMLファイルの上位構造には、何時のどのような素性のデータといった「書誌」的な情報など各種の必須情報が含まれています。個別の地震とか火山などの具体的な情報は、かなり奥の方に配列として格納されています。
changeノード(その1)は、個別の地震とか火山とかのデータ実体を列挙している配列を取り出すために使っています。
changeノードに後続する splitノードで、取得した配列を要素毎に分割しています。各要素が個別の地震や火山情報などとなっているようです。
changeノード(その2)
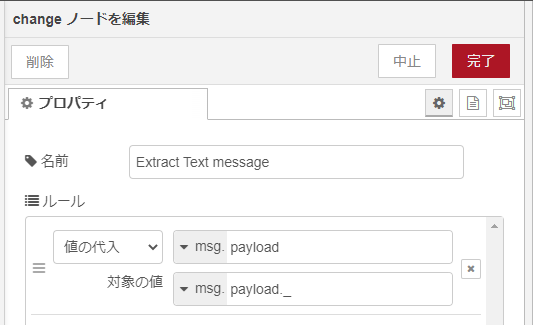
上の処理で個別の地震や火山情報毎に分割されていますが、その中にさらに構造があります。情報のタイトルや時刻、オーサーなどが含まれます。その中で発表された情報の「本文」はcontentというプロパティに格納されています。
2番目のchangeノードでは、content部分を取り出しています。
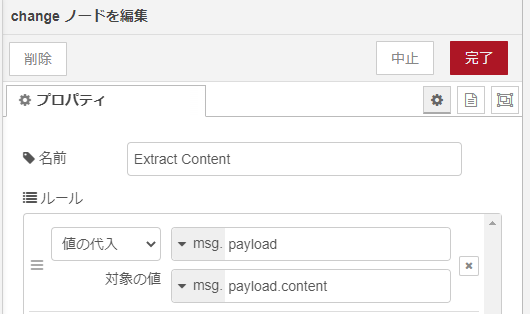
changeノード(その3)
content部分もまたオブジェクトであり、xml(パーサ)ノードで述べたように、タグ属性”text”は$プロパティ、文字列部分は _プロパティに載っています。3番目のchange ノードでは 文字列部分(本文)を抽出しています。
debugノードの出力(抽出結果)
1本のXMLファイルを処理したところ400件以上の情報が列挙されてきましたが、そのうち2件分の出力を「ぼかした」形で掲げます。
 まあ、とれているんでないかい。
まあ、とれているんでないかい。
こうして説明を書くとなかなかメンドイように見えますが、ノードを置いて繋げていくだけでこういう処理が簡単にできてしまうNodeREDは本当にお楽。