前回につづき今回も因子分析(factor analysis)です。わけわからないまま手を動かしてグラフにしています。データセットは「シカゴの郊外の中一、中二くらいの生徒さん145名分の24種の心理学テストの結果」の分散共分散行列みたいです。今回は、分けわからないまま promax回転とな。
※「データのお砂場」投稿順Indexはこちら
R言語に「漏れなくついてくる」であろうサンプルデータセットをABC順に端から「当たって」います。前回 Harmanさんの御本のテーブル2.3のデータだったので、今回 Harmanさんの御本のテーブル7.4のデータだったとしても驚くことはありません。でも、分けわからないのは同じですけど。
データセットの解説ページ
データセットの解説ページへのリンクを貼らせていただきました。これによって今回のデータが何やら心理学のテストの集計結果であることは判明いたしました。
確かに24種類の測定項目がふくまれとるようです。そして、それらの項目名は調べれば判明するものが多そう(ちょっとだけ調べてみた)で、心理学上の概念が浮かびあがってくる気もします(個人の妄想です?)調べれば泥沼(心理学のお人すみません)にハマり込むこと必定。ま、しかし、この因子分析なるもの、どうももともと心理学の測定のために発展してきた、という歴史があるようです。これは王道のデータなのか。この24種の測定項目の背後に隠れている「潜在因子」が因子分析によって明らかになるのだ。知らんけど。
生データ
今回もまず生データを見てみました。構造的には前回とまったく同じです。データの入れ物はList構造で、その中にMatrix(行列)が入っています。ただ測定項目が24種もあるだけに、行列の大きさはデカイです。頭の部分をみたところが以下に。

因子分析開始
わけわかっていませんが、前回やってみているので、手を動かすことは可能。ホイホイっと。まずは1因子で計算してみろ、と。こんな感じ。
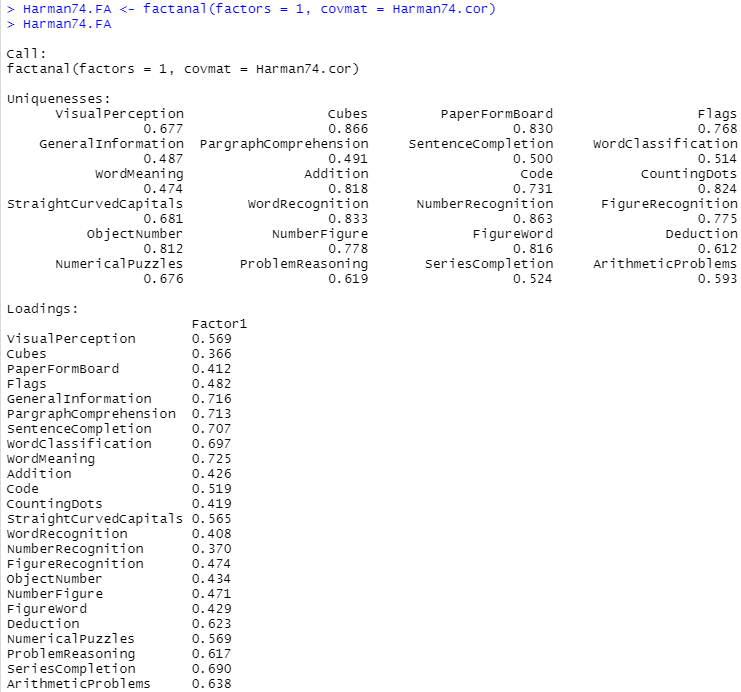
訳分かっていませんが、計算はできます。しかし、隠れた因子が一つでは様にならない。前回もでしたが、数個ぐらいが順当なのか。多からず、少なからず。そこで for文で、因子数を変化させて、計算してみよ、と例はおっしゃる。もしも、手動でやったならば死ぬまでに終わらないかもしれませんが、Rのお陰で一瞬です。
for(factors in 2:5) print(update(Harman74.FA, factors = factors))
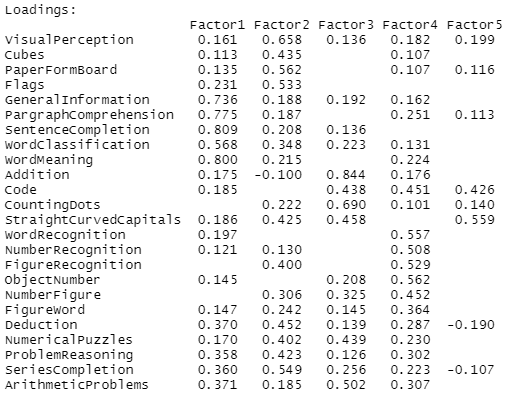
以下は5因子のときの Loadings (因子負荷量)の計算結果。なんじゃこりゃ。
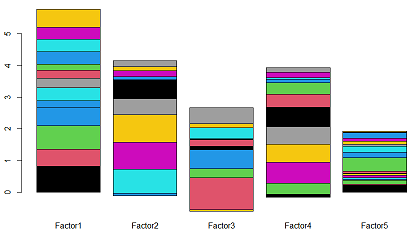
それぞれの潜在因子毎に因子負荷量を「線形結合」した様子を棒グラフにいたしました。因子4個くらいがいい感じかね、5個目はちょっと弱い?見た目が全ての感想です。
しかし、今回は「メリハリ」をつけるために、計算している「空間」を回転させて再計算した方が良いみたいです。promax回転とな。何それ、ももう手が届かない遠方に来てしまった気がします。ま、計算は簡単。Rが皆やってくれます。こんな感じ。
![]()
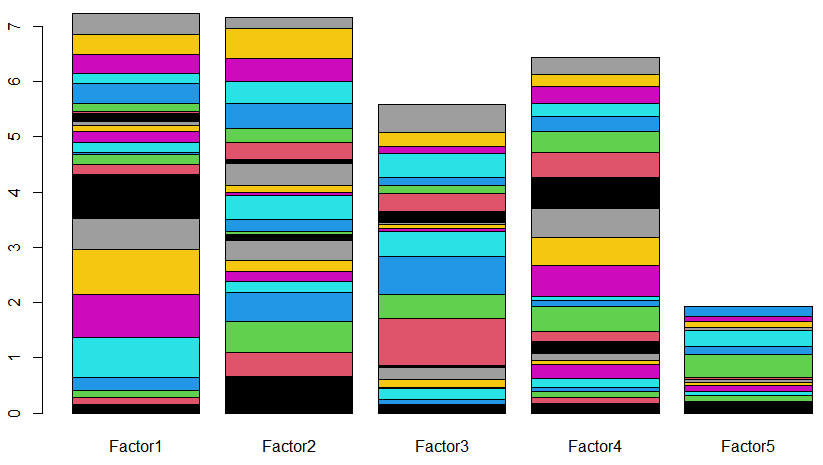
計算結果をグラフにしたところが以下に。
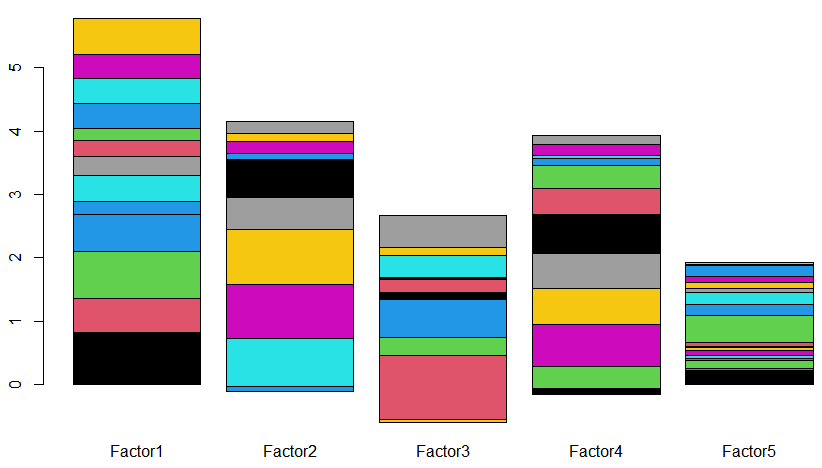 確かに上のグラフに比べると、メリハリついた感がありです。上のグラフでは、ごちゃまんと沢山の測定項目(因子)が盛り込まれていたですが、下のグラフでは比較的少ない測定項目に帰着している感じがあり、です。
確かに上のグラフに比べると、メリハリついた感がありです。上のグラフでは、ごちゃまんと沢山の測定項目(因子)が盛り込まれていたですが、下のグラフでは比較的少ない測定項目に帰着している感じがあり、です。
あくまで見た目の感想、本人、何もわかっちゃおりません。残念。