前回に引き続きHello world的データセット iris です。前回はJupyter-labでsklearn内蔵の iris データセットを開き、そのデータ構造を調べました。そしてデータのグラフを1枚描画。今回は、分類の最初の1歩ということで、「見ればわかる」人間的分類をやってみて結果をグラフに残したいと思います。
※「MLのお砂場」投稿順 index はこちら
以下実施した実習の一部は、以下の教科書の内容に基づいています。ただ、以下はPython2の時代のものなので、勝手に変更してPython3で走らせている部分もあります。
「実践 機械学習システム」Willi Richert & Luis Pedro Coelho著 斎藤訳 オライリー・ジャパン
4種のデータ全ての組み合わせについて散布図を描いてみる
前回の復習になりますが、irisの花1つのデータには以下4つの数字が入っています。
-
- sepal 萼片(がく片) 長さと幅[cm]
- petal 花弁 長さと幅[cm]
前回はそのうち、sepalの長さと幅についてグラフ化してみました。しかし数字が4個あれば、XY2次元の散布図とすると合計6組の組み合わせが可能です。以下のコードで、全組み合わせを一覧できるグラフをまずは描いてみました。
from sklearn.datasets import load_iris
from matplotlib import pyplot as plt
import numpy as np
data = load_iris()
features = data['data']
feature_names = data['feature_names']
target = data['target']
target_names = data['target_names']
labels = target_names[target]
def pltSub(fplt, elmx, elmy, lblx, lbly):
global target_names
for t, marker, c in zip(range(3), ">ox", "rgb"):
fplt.scatter(features[target == t, elmx],
features[target == t, elmy],
marker=marker,
c=c)
fplt.set_xlabel(lblx)
fplt.set_ylabel(lbly)
fplt.legend(target_names)
fig = plt.figure()
p11 = fig.add_subplot(2, 3, 1)
pltSub(p11, 0, 1, "sepal length [cm]","sepal width [cm]")
p12 = fig.add_subplot(2, 3, 2)
pltSub(p12, 0, 2, "sepal length [cm]","petal length [cm]")
p13 = fig.add_subplot(2, 3, 3)
pltSub(p13, 0, 3, "sepal length [cm]","petal width [cm]")
p21 = fig.add_subplot(2, 3, 4)
pltSub(p21, 1, 2, "sepal width [cm]","petal length [cm]")
p22 = fig.add_subplot(2, 3, 5)
pltSub(p22, 1, 3, "sepal width [cm]","petal width [cm]")
p23 = fig.add_subplot(2, 3, 6)
pltSub(p23, 2, 3, "petal length [cm]","petal width [cm]")
fig.tight_layout()
fig.show()
描いた散布図上でのプロット点は以下のようです。
-
- Iris-Setosa 赤の三角
- Iris-Versicolour 緑の丸
- Iris-Virginica 青の×
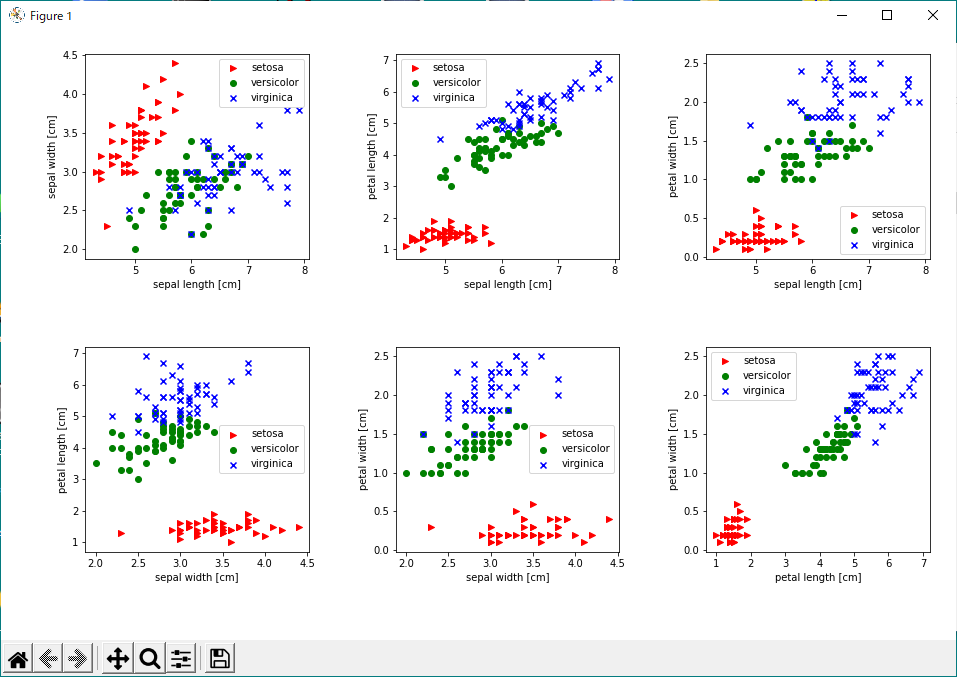
上記のプロットを見ると、明らかに赤のSetosaという種類のアヤメは他の2種から離れたところにいることが分かります。人間からすると 花弁(petal) 長さと幅を使えば簡単に分類できそうに思えます。
このヒューリスティックな分類方法のうちpetal length基準の方法をそのままコード化したものが以下に(以下は教科書コードそのまま)本来なら機械に学習してもらう部分。
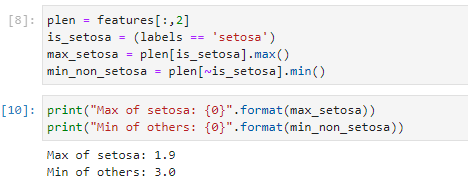
上記の計算から、MaxとMinの中間点にスレショルドを置くというこれまた人間的な方法で、識別関数を作り、勝手に全データに対して適用してみたものが以下に。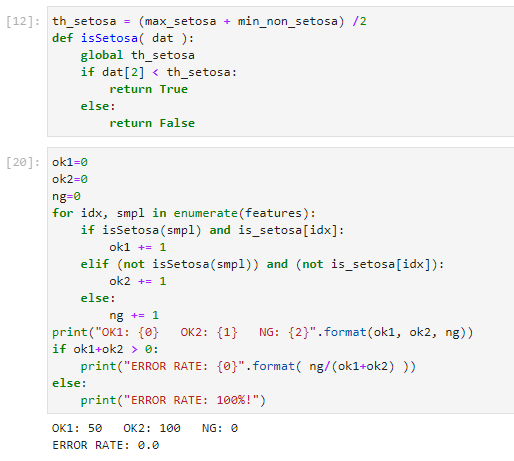
100%分類成功とな。ただ教科書には学習に使うデータセットと評価のためのデータセットを分ける必要性(交差検定)についての説明が続くのです。上記の件では、散布図みたら明らかなのでこれまたヒューリスティックにOKしてしまいます(それでよいのか。)
分類の様子をグラフ化してみる御勝手コードが以下に。手元のJupyter-lab環境では、”%matplotlib tk”(別ウインドウでグラフを開く)でないと動作しなかったです。なして?

冒頭のアイキャッチ画像と同じものですが、再掲。setosa種と他の2種については、ぱっと見のヒューリスティックな分類方法でイケてしまうと。
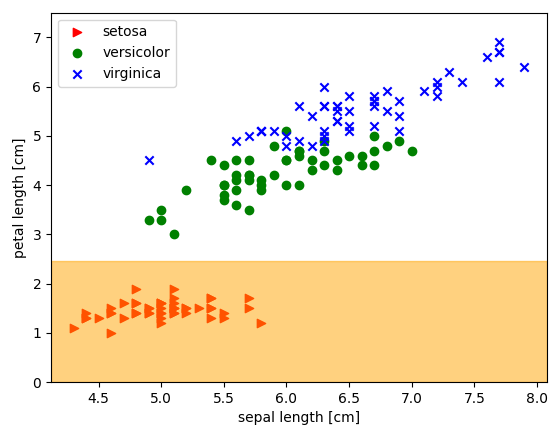
また「本格的」MLの出る幕なかったですが、分類は分類、最初の1歩だと。次回はMLらしくなるのか?