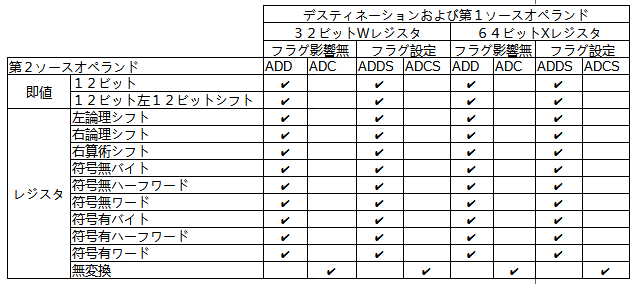
Armの64ビット命令、32ビットの時と比べると条件付き実行のフィールドが無くなって「スッキリ」した印象です。しかし、RISC-Vを眺めた後でA64(AArch64)を眺めるとなんと複雑な。伝統?のシフトできるレジスタオペランドは健在。フラグ操作のON/OFFも加わって組み合わせが多いです。とても1回では見切れませぬ。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
「最初はADD」ということで整数加算命令を「エクササイズ」してみることにいたしました。参照するのはArm社の以下のドキュメントであります。
Arm Architecture Reference Manual for A-profile architecture
高々整数加算命令、と思いきや、とても老人の忘却力に対抗できるシンプルさではありません。思わず表計算ソフトにて一覧表を作成してしまいました。冒頭のアイキャッチ画像に掲げましたもの。
今回は上の表の「ADD」列、「即値」行部分のみを動かしてみたいと思います。動作実験に使用しているのは、フツーのAndroidスマホ(当然AArch64コアSoC搭載)です。パソコンからSSH接続してClangでビルドし、GDBで観察を行っております。
ターゲット関数を記述したアセンブラファイル
ADD即値命令を練習するためのアセンブラファイルには実質1命令のアセンブラ関数を4個定義してみました。
-
- ワード(32ビット幅)、即値333をソース第1に加えて結果を返す
- ダブルワード(64ビット幅)、即値333をソース第1に加えて結果を返す
- ワード(32ビット幅)、即値333を12ビット左シフトしたものをソース第1に加えて結果を返す
- ダブルワード(64ビット幅)、即値333を12ビット左シフトしたものソース第1に加えて結果を返す
お分かりの通り、2命令を費やせば24ビット幅の即値を加算(第1ソースが0ならば実質MOV)できるという強力さです。使用したアセンブリ言語ソースが以下に。
addimmTST.s
.globl addimmW, addimmX, addimmW12, addimmX12
.text
.balign 4
addimmW:
add w0, w1, #333
ret
addimmX:
add x0, x1, #333
ret
addimmW12:
add w0, w1, #333, LSL #12
ret
addimmX12:
add x0, x1, #333, LSL #12
ret
なお、LSL #12などと厳めしく書いてありますが、他のシフトとの表記の整合性のためだと思います。とりえる値は、#0で「シフトしない」か、#12で12ビットシフトするかだけです。勿論左シフトのみ。
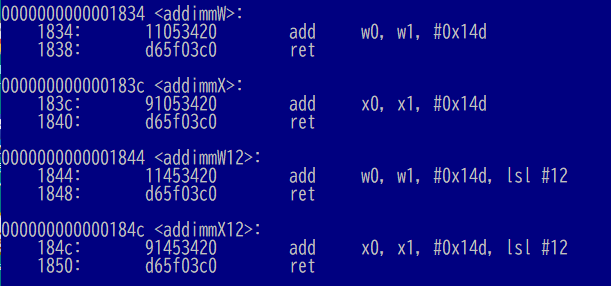
念のためアセンブラをかけた後のオブジェクトファイルをダンプしてみたものが以下に。機械語命令コードを観察すると wの命令と、xの命令の違いはビット31が立っているか否かです。立っていたら64ビット幅、立っていなかったら32ビット幅と。
テストケースを記述したCのmain関数
上記のアセンブリ言語定義の関数を呼び出すCのメインが以下に。
addimmTST.c
#include <stdio.h>
#define TARGETVAL (0xFFFFFFFF - 300)
extern uint32_t addimmW(uint32_t, uint32_t);
extern uint32_t addimmX(uint64_t, uint64_t);
extern uint32_t addimmW12(uint32_t, uint32_t);
extern uint32_t addimmX12(uint64_t, uint64_t);
int main(void)
{
uint32_t result;
result = addimmW(0, 100);
printf("addimmW 100+333: %d\n", result);
result = addimmW(0, TARGETVAL);
printf("addimmW TARGETVAL+333: %d\n", result);
result = addimmX(0, TARGETVAL);
printf("addimmX TARGETVAL+333: %d\n", result);
result = addimmW12(0, 100);
printf("addimmW 100+LSL12(333): %d\n", result);
result = addimmX12(0, TARGETVAL);
printf("addimmX12 TARGETVAL+LSL12(333): %d\n", result);
return 0;
}
Cソースと、アセンブラ・ソースをビルドするのは以下に(Androidスマホ上のTermux環境ではClang/LLVMがデフォルトのためです。gccをインストールしてclangをgccに替えても同様です。なお、Termuxのデフォルトではgccはインストールされておらず、gccと打つとclangが立ち上がるようになってます。)
$ clang -g -o0 -o addimmTST addimmTST.c addimmTST.s
gdb -tui で動作観察
前回使えるようにした gdb の tui モードで該当関数をステップ実行していったところが以下に。
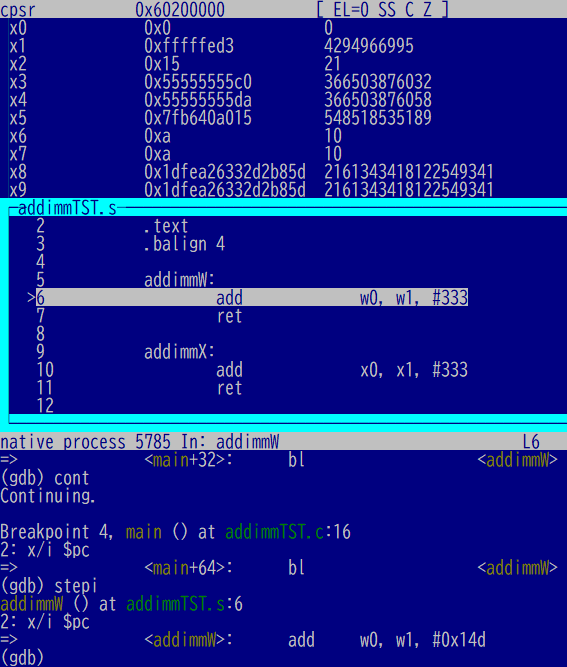
まずは32ビット幅の処理、w1(x1の下位32ビット)に100、それに即値333を足す場合。足す直前の様子が以下に。
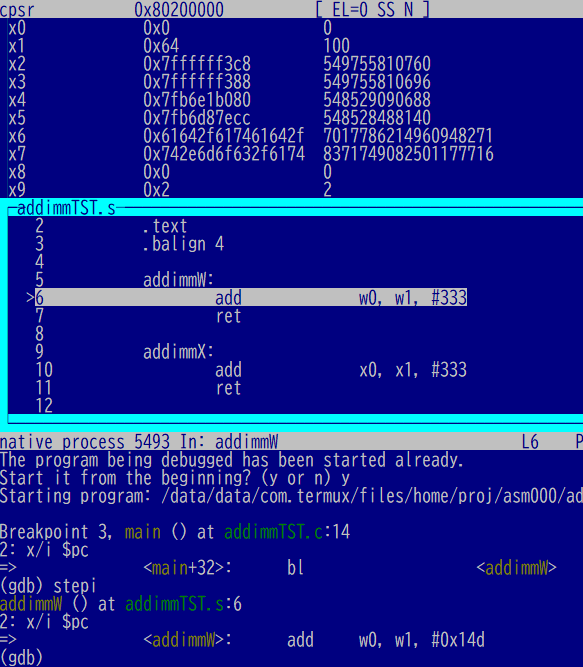
足した後です。結果はw0(x0の下位32ビット)に。100+333=433ね。
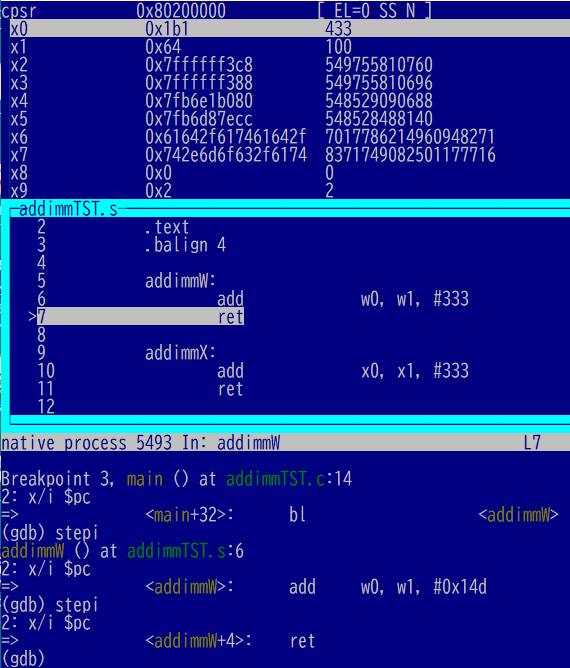
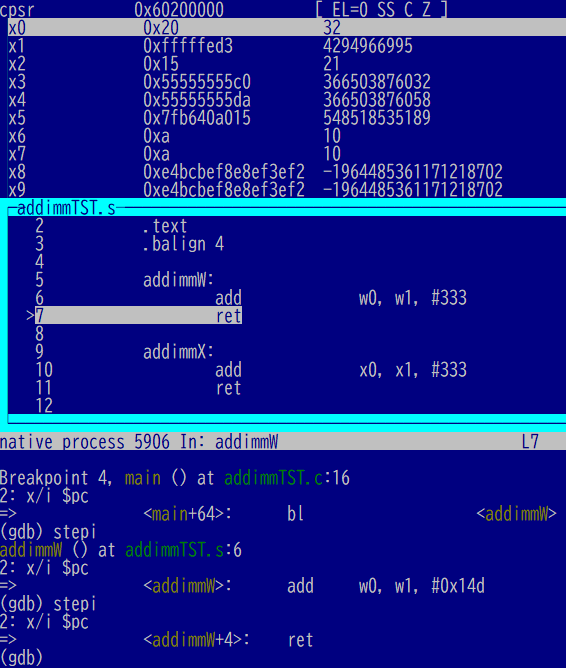
次は32ビット幅では「ラップ」してしまうやつです。100の代わりに上限ー300なる数をセット。
そこに+333したので、0を通り超えて32まで戻ってきました。
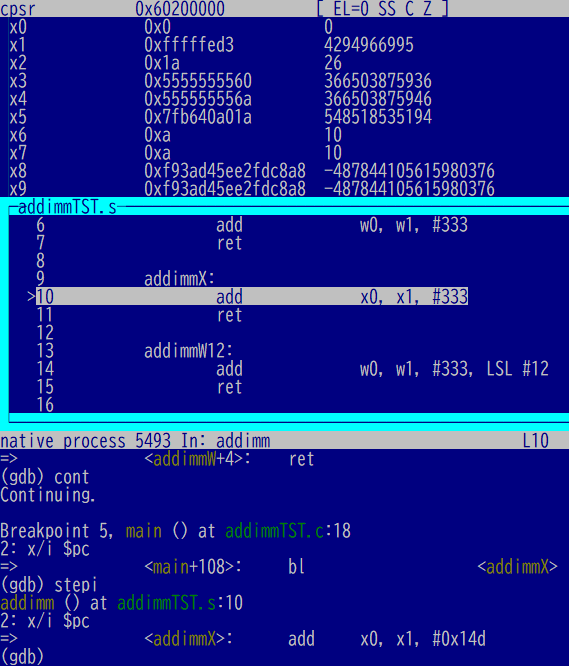
同じことを今度は64ビット幅で実行してみます。まずは加算前。
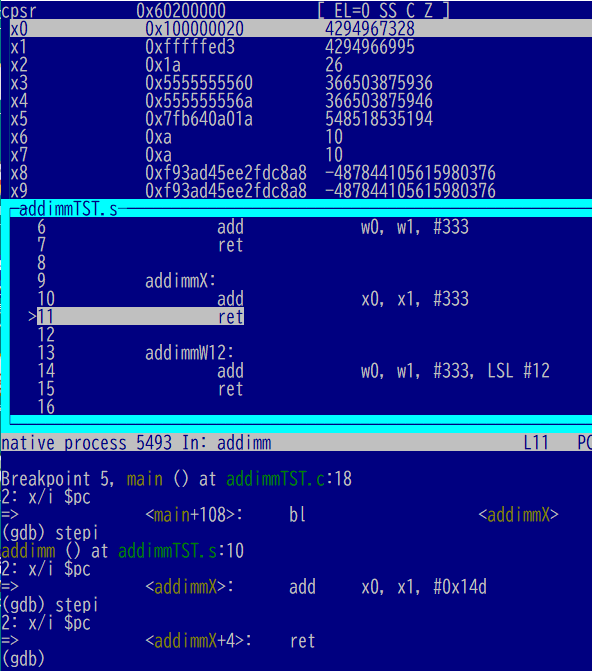
加算後が以下に。ラップせず上に突き抜けてます。予定どおり。
続いて即値を12ビット左シフトするもの。と思ったらW(ワード)の結果のキャプチャが無いデス。以下はX(ダブルワード)の実行前。
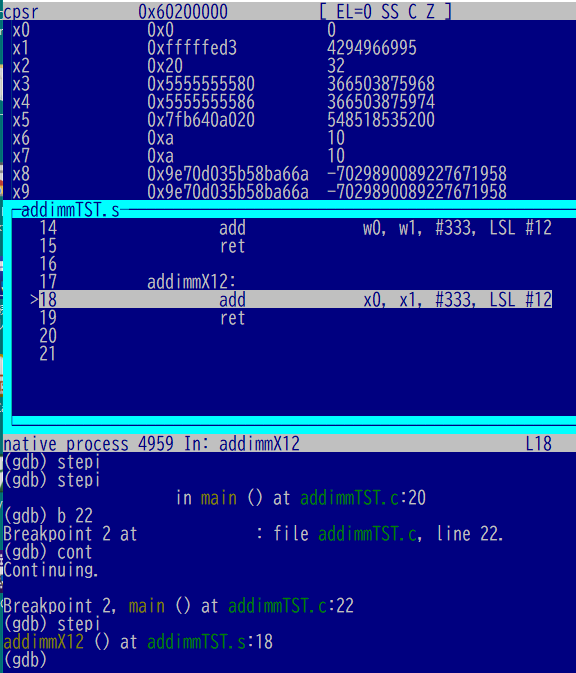
実行後がこちら。12ビットシフトした大きな値を足すことができました。
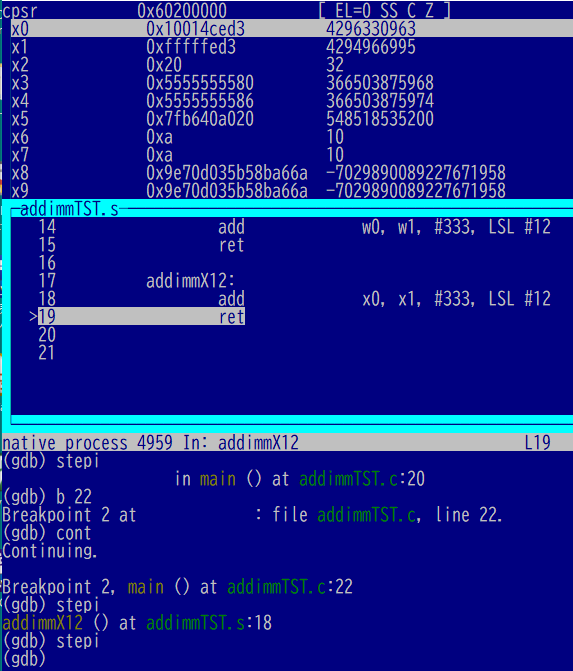
ちょっと不注意もあったけれど、思った通りに動いた感じ。しかしたかだか4命令を練習するだけでこの手間。ADD全部さらうのにどれだけかかる?手抜き得意だから大丈夫かか、自分。