R言語付属のデータセットをアルファベット順(大文字優先)で眺めてます。今回は「かの」Irisです。本サイトでも何度か使わせていただいたことがあります。ML(Machine Learning)業界のHello World. 定番中のド定番のデータセット。しかし、今回のR言語の処理例をみると分類でも識別でもないです。
※「データのお砂場」投稿順Indexはこちら
過去に「眺めた」Irisデータセット
Irisデータセットは「知らないとモグリ」と断言できるくらい超有名なデータセットなので別シリーズで練習やってました(私はモグリの人ですが、それでも知っておると。)それもしつこく4回も連続で。
MLのお砂場(3) ML業界のHello world? irisデータセットをのぞく
MLのお砂場(4) irisデータセットその2、Classification最初の一歩
MLのお砂場(5) irisデータセットでClustering、K-means例題を読む
MLのお砂場(6) Classifier comparison例題をしげしげと眺めるの巻
御多分にもれず Classification、Clusteringといった問題のサンプルとしてであります。
今回のサンプルデータセットの処理の「狙い」
以下のR言語付属のサンプルデータセットの解説ページを読む限り、Irisデータセットをもってきた「狙い」はクラシフィケーションでもクラスタリングでもないようです(勿論、Rでもできる筈ですが。)
データセットを列挙すると、以下のように「等価な」Irisデータセットが2つ用意されとります。

今回は、この2つの間の変換と比較が「狙い」みたいです。
生データセット
irisおよびiris3をロードして、中身を覗いてみたところが以下に。
irisデータセットはデータフレーム形式です。花弁、萼片の長さと幅の列、そしてそれぞれのレコードがIrisでもどの種類のIrisかを識別するSpecies列からなってます。それにたいして iris3は3次元のMatrixの中にデータが並べられてます。
処理例
上記のデータセット解説ページに記載の処理例は以下です。
-
- iris3のMatrix形式のデータをdataframe形式に変換
- 変換したdatafremeと元からdataframeのirisの一致をall.equal()関数で調べる

結果は、上記のように一致(TRUE)です。あたりまえか。でも上記の処理例をみると、各列名の大文字小文字の違いとか、省略の仕方とか細かいところををいろいろ始末しているところが地道。そういう細部が大事だということ?
プロット例
処理例は、上記のように「細部に気を配った」形式変換してTRUEで終わりです。しかし、Irisというと何かプロットせずにはいられませぬ。R言語の解説ページには、以下のところにプロット例もあります。
以下は1つ目のプロットの処理例。
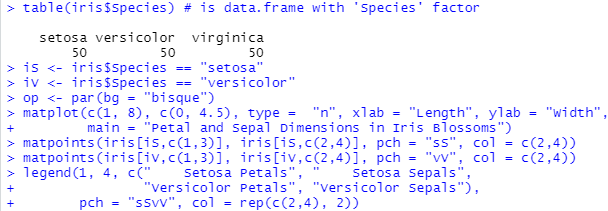
こんな感じ。簡単にクラスタリング、クラシフィケーションできそうな感じ。おや、Irisって重なって「ムツカシー」ところがあったんじゃなかったっけ。よくみたら、「簡単に分けられる2種類だけ」のプロットだね、これは。
2つ目のプロットの処理例が以下に。
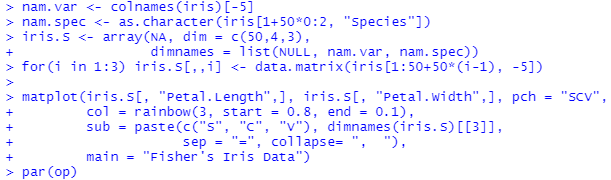
これこそ典型的なIris。Setosa種は明確に離れているけれど、versicolo種、virginica種は重なっておる、と。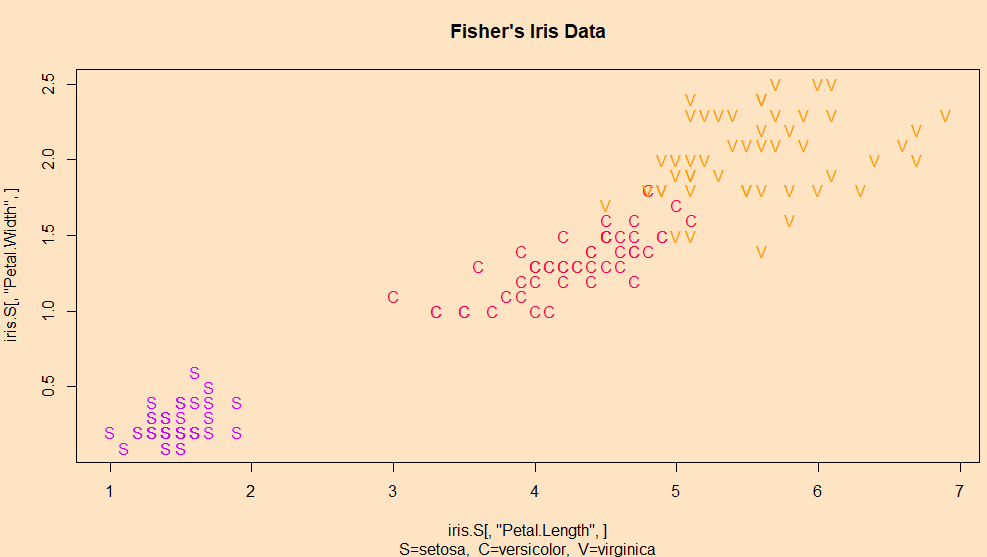
今回は処理例どおりにやってみただけ。手抜き(いつもか。)