今回はFMOV命令です。浮動小数点数の転送命令。浮動小数点といっても何の変換操作もなし、単なるビットパターンのコピーです。命令はたった一つFMOV。しかしこれが意外に面倒デス。今回でも組み合わせが多いのに、ターゲットマシンが半精度を使える機種だったらもっとやらないといけなかったです。頭文字Fの命令にチョロイのはいない。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
FMOV
FMOVと一つのニーモニックのもとにくくられてますが、実体は3種類の命令と見た方がよさそうです。
-
- 浮動小数点レジスタへの即値ロード
- 浮動小数点レジスタ間の転送
- 浮動小数点レジスタと整数レジスタ間の転送
これと単精度、倍精度の組み合わせがからみます。ターゲットマシンCortex-A72は半精度浮動小数不在なのでこれでも組み合わせが大分少ないっす。ARMv8.2以降の半精度があるマシンだとほんと組み合わせが多いなあという感じ。今回の範囲だけを図にしたものを再掲します。なお箱ひとつ32ビット幅です。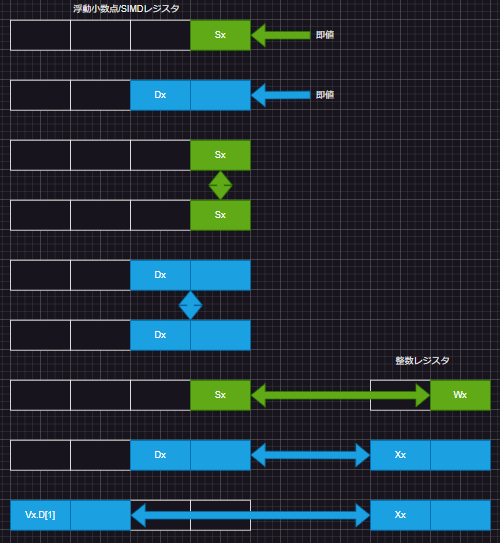
上記の図の末尾の128ビット幅の浮動小数点数/SIMDレジスタの上位64ビットと整数レジスタ間の命令は、SIMD命令の一部がスカラーの浮動小数点命令に紛れ込んだ?ようなものでちょいと異質で非対称です。知らんけど。
また、即値のロード命令ですが、32ビット幅のARM64の命令に浮動小数点数即値を埋め込むので制限厳しいです。符号1ビット、指数部3ビット、仮数部4ビットの合計8ビットです。そんなビット幅でも使えるだけでうれしいかも。
今回実験に使用したアセンブリ言語ソース
いつものように、関数プロローグもエピローグもない、手抜きな1命令1関数スタイルの被テスト関数群が以下に。ただし、最後の「SIMDの紛れ込み」的スカラーFMOV命令は、ちょいと手順が必要に思われたので2命令でいってこいしてます。
.globl fmovdd, fmovss, fmovdi, fmovsi, fmovsw, fmovws, fmovdx, fmovxd, fmovtxt
.text
.balign 4
fmovdd:
fmov d0, d1
ret
fmovss:
fmov s0, s1
ret
fmovdi:
fmov d0, #1.75
ret
fmovsi:
fmov s0, #1.75
ret
fmovws:
fmov w0, s0
ret
fmovsw:
fmov s0, w0
ret
fmovxd:
fmov x0, d0
ret
fmovdx:
fmov d0, x0
ret
fmovxt:
ret
fmovtxt:
fmov d2, #2.75
fmov x1, d2
fmov v0.D[1], x1
fmov x0, v0.D[1]
ret
即値フィールドにビット幅小さい浮動小数点数かけるところが何気に良いです。
C言語記述のmain関数
上記のアセンブラ関数を呼び出してテストするもの。FMOV自体は単なるビットパターンのコピーでしかありませんが、浮動小数として解釈したり、同じものを符号無整数としてビットパターンを読んだりしたいので union してます(こういうときにはC++で使えた筈の無名unionの方がカッコいいデス。)
なお、浮動小数のビットパターンを読むときは、指数部は下駄ばき、仮数部には暗黙の1が頭にある、という2点を忘れずに(といって手でビットパターンを変換したりしたくないケド。)
#include <stdio.h>
#include <stdint.h>
extern double fmovdd(double, double);
extern float fmovss(float, float);
extern double fmovdi(double);
extern float fmovsi(float);
extern float fmovsw(float, uint32_t);
extern uint32_t fmovws(uint32_t, float);
extern double fmovdx(double, uint64_t);
extern uint64_t fmovxd(uint64_t, double);
extern uint64_t fmovtxt(uint64_t);
int main(void)
{
union {
double resultD;
uint64_t result64;
} u64;
union {
float resultS;
uint32_t result32;
} u32;
u64.resultD = fmovdd(0.0, 5.55);
printf ("fmovdd(0.0 5.55): %16e 0x%016lx\n", u64.resultD, u64.result64);
u32.resultS = fmovss(0.0f, 5.55f);
printf ("fmovss(0.0f 5.55f): %8e 0x%08x\n", u32.resultS, u32.result32);
u64.resultD = fmovdi(0.0);
printf ("fmovdi(0.0 [1.75]): %16e 0x%016lx\n", u64.resultD, u64.result64);
u32.resultS = fmovsi(0.0f);
printf ("fmovsi(0.0f [1.75]): %8e 0x%08x\n", u32.resultS, u32.result32);
u64.result64 = fmovxd(0.0, 2.75);
printf ("fmovxd(0.0, 2.75): 0x%016lx\n", u64.result64);
u32.result32 = fmovws(0.0, 2.75f);
printf ("fmovws(0.0, 2.75f): 0x%08x\n", u32.result32);
u64.resultD = fmovdx(0.0, 0x4016333333333333);
printf ("fmovdx(0.0 0x4016333333333333): %16e\n", u64.resultD);
u32.resultS = fmovsw(0.0f, 0x40b1999a);
printf ("fmovsw(0.0f 0x40b1999a): %8e\n", u32.resultS);
u64.result64 = fmovtxt(0);
printf ("fmovtxt(0): %16e 0x%016lx\n", u64.resultD, u64.result64);
return 0;
}
ビルドして実行
ビルドして実行したところが以下に。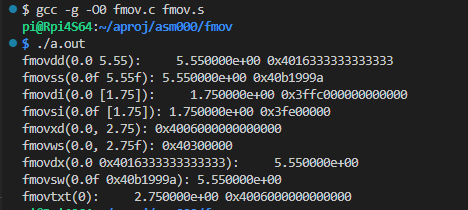
問題なく動いてはいるけれども、メンドイよなあ。