前回、行列積の計算をささやかな2スレッドですがマルチスレッド化してみました。ということはその効果を「計測」してみたくなるのが人情です(ホントか?)尤もらしい結果を得るために複数回の計測を繰り返して平均とってなどと思ったのです。しかしそれ以前の問題にやられました。Rustの最適化強力ぞなもし。
※『RustにいればRustに従え』関係記事 index はこちら
※動作確認は、Windows11のWSL2上にインストールしたUbuntu20.04LTS上のrustc 1.64.0 (a55dd71d5 2022-09-19) で行っています。
時間計測
前回動作確認のとれたコードの一部区間の実行時間を測定したいです。それには以下の標準モジュールにあるInstantというDurationを計算するための構造体のメソッドが使えるみたいでした。
time::Instant::now()というメソッドで構造体に現在時刻を代入し、.elapsed()というメソッドで経過時間を取得すると。さっそく前回のコードの所望部分に時間計測のコードを「ばらまき」ました。こんな感じ。
use rand::Rng;
use std::thread;
use std::sync::mpsc;
use std::time;
const ARRAYSIZE: usize = 100;
fn make_random_array() -> [[i32; ARRAYSIZE]; ARRAYSIZE] {
let mut temp_array: [[i32; ARRAYSIZE]; ARRAYSIZE] = [[0; ARRAYSIZE]; ARRAYSIZE];
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE {
temp_array[i][j] = rand::thread_rng().gen_range(0..256);
}
}
return temp_array;
}
fn main() {
println!("mult_array spawn & channel");
let array_a: [[i32; ARRAYSIZE]; ARRAYSIZE] = make_random_array();
let array_b: [[i32; ARRAYSIZE]; ARRAYSIZE] = make_random_array();
let mut array_c: [[i32; ARRAYSIZE]; ARRAYSIZE] = [[0; ARRAYSIZE]; ARRAYSIZE];
let (txa, rxa) = mpsc::channel();
let (txb, rxb) = mpsc::channel();
let mult_stopwatch = time::Instant::now();
let handle_a = thread::spawn(move || {
let mut array_ca: [[i32; ARRAYSIZE/2]; ARRAYSIZE] = [[0; ARRAYSIZE/2]; ARRAYSIZE];
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE/2 {
array_ca[i][j] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
txa.send(array_ca).unwrap();
});
let handle_b = thread::spawn(move || {
let mut array_cb: [[i32; ARRAYSIZE/2]; ARRAYSIZE] = [[0; ARRAYSIZE/2]; ARRAYSIZE];
for i in 0..ARRAYSIZE {
for j in (ARRAYSIZE/2)..ARRAYSIZE {
array_cb[i][j-ARRAYSIZE/2] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
txb.send(array_cb).unwrap();
});
let received_a = rxa.recv().unwrap();
let received_b = rxb.recv().unwrap();
handle_a.join().unwrap();
handle_b.join().unwrap();
let mult_elapsed = mult_stopwatch.elapsed();
let single_stopwatch = time::Instant::now();
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE {
array_c[i][j] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
let single_elapsed = single_stopwatch.elapsed();
println!("TWO THREAD: {:?}", mult_elapsed);
println!("MAIN : {:?}", single_elapsed);
}
2スレッドを作って行列を半分こにして計算している部分と、メインスレッドのみで計算している部分の前後に「ストップウォッチ」をしかけてみました。
オプティマイズなし、cargo runの結果
いつもお世話になっているcargo runの場合は、以下のように、非最適化かつデバッグ情報付です。当然遅いけれど「書いたとおり」のコードが実行されるハズ。結果が以下に。
2スレッド並列だと11.1ms、MAINスレッドのみだと15.7msか。一応予定どおりね。いろいろ「大人の事情がある」立派なOS上でのこの手の計測はマシンの状況次第で毎回数値が変化するので多数回やって平均、最大、最小くらいは押さえたいものです。
リリースビルドしてみた
しかしそれ以前に、小さいものとは言え、ある種のベンチマークみたいなものなので「最適化はオン」にしておきたいです。そうしないと意味が無いっす。そこで滅多にやらない release ビルドしてみました。リリースビルドの様子(先頭部分だけだけど)が以下に。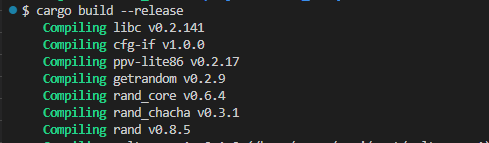
実行してみたらばこんな感じ。
最適化しないと15.7msかかっていたものが、118nsとな。いくら何でも効果抜群すぎるだろ。多分、結果が見えている処理はしない最適化「処理をやったふり」か?普通にgccなども最適化すると「その部分のコードが無かった」ことはよくある「あるある」。なんとか「なくなる」のだけは阻止したいデス。計算はしてよね。
black_box
そこでちょっと調べてみたら、「最適化を阻害する」black_boxたらいうものがヒットしてまいりました。該当のマニュアルページが以下に。
なにやら恐ろし気な名称ですが、これを使うとコンパイラにココは実行時でないと決まらん(から勝手に消すな)とお伝えしてくれるらしいです。black_box化?してビルドしてみたらば、こんな感じ。
コンパイラ様は unstableなライブラリは使うな、とお怒りです。きっと無理やり使う方法がありそうですが、早々と諦めました。
コマンドラインから引数与えたらどうよ
こういう最適化を阻止するのによくやる手として、人間の入力を介在させるという手があります。コマンドラインから引数などとして与える値によって処理が変わるようにするもの。流石にコンパイラ様はコンパイル後に与えられるコマンドライン引数の値はオミトオシでないので、多分、そこは受け入れるコードを生成するしかない、と。
コマンドライン引数は並列用とメイン用にそれぞれ別の2個にしました。修正したコードが以下に。
use rand::Rng;
use std::thread;
use std::sync::mpsc;
use std::time::{self, Duration};
use std::env;
const ARRAYSIZE: usize = 100;
fn make_random_array() -> [[i32; ARRAYSIZE]; ARRAYSIZE] {
let mut temp_array: [[i32; ARRAYSIZE]; ARRAYSIZE] = [[0; ARRAYSIZE]; ARRAYSIZE];
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE {
temp_array[i][j] = rand::thread_rng().gen_range(0..256);
}
}
return temp_array;
}
fn mult_exec(x: usize, array_a: [[i32; ARRAYSIZE]; ARRAYSIZE], array_b: [[i32; ARRAYSIZE]; ARRAYSIZE]) -> Duration {
println!("start AB");
let (txa, rxa) = mpsc::channel();
let (txb, rxb) = mpsc::channel();
let mult_stopwatch = time::Instant::now();
let handle_a = thread::spawn(move || {
let mut array_ca: [[i32; ARRAYSIZE/2]; ARRAYSIZE] = [[0; ARRAYSIZE/2]; ARRAYSIZE];
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE/2 {
array_ca[i][j] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
txa.send(array_ca).unwrap();
});
let handle_b = thread::spawn(move || {
let mut array_cb: [[i32; ARRAYSIZE/2]; ARRAYSIZE] = [[0; ARRAYSIZE/2]; ARRAYSIZE];
for i in 0..ARRAYSIZE {
for j in (ARRAYSIZE/2)..ARRAYSIZE {
array_cb[i][j-ARRAYSIZE/2] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
txb.send(array_cb).unwrap();
});
let received_a = rxa.recv().unwrap();
let received_b = rxb.recv().unwrap();
handle_a.join().unwrap();
handle_b.join().unwrap();
let retval = mult_stopwatch.elapsed();
println!("end AB");
println!("{}", received_a[x][x]);
println!("{}", received_b[x][x]);
retval
}
fn single_exec(x: usize, array_a: [[i32; ARRAYSIZE]; ARRAYSIZE], array_b: [[i32; ARRAYSIZE]; ARRAYSIZE]) -> Duration {
println!("start M");
let mut array_c: [[i32; ARRAYSIZE]; ARRAYSIZE] = [[0; ARRAYSIZE]; ARRAYSIZE];
let single_stopwatch = time::Instant::now();
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE {
array_c[i][j] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
let retval = single_stopwatch.elapsed();
println!("end M");
println!("{}", array_c[x][x]);
retval
}
fn main() {
println!("mult_array spawn & channel, time it!");
let args: Vec<String> = env::args().collect();
let xab: usize = args[1].parse().unwrap();
let xc: usize = args[2].parse().unwrap();
let array_a: [[i32; ARRAYSIZE]; ARRAYSIZE] = make_random_array();
let array_b: [[i32; ARRAYSIZE]; ARRAYSIZE] = make_random_array();
let mult_elapsed = mult_exec(xab, array_a, array_b);
let single_elapsed = single_exec(xc, array_a, array_b);
println!("TWO THREAD: {:?}", mult_elapsed);
println!("MAIN : {:?}", single_elapsed);
}
念のため、cargo run で最適化なしでの動作が以下に。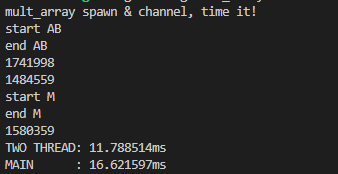
この値は、最初のプログラムの最適化なしとほぼ同じね。
さて、いよいよ releaseビルド後の実行であります。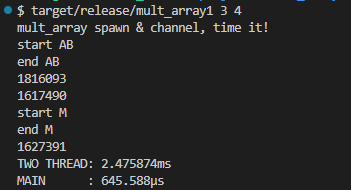
ns 単位という「コードが完全に消えた」だろ~という結果からは桁が変わりました。しかしMAINの1スレッドの圧勝であります。考えられるのは以下2つか。
-
- MAINスレッド内で「ズルしている」部分がまだある
- 2スレッドの方が、スレッド生成、スレッド間のデータ転送、スレッド終了待ちなどのオーバヘッドで実際に遅い
試みに2スレッドの関数をコメントアウトして、シングルのみで走らせたところが以下に。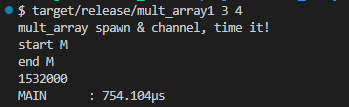
ううむシングルスレッド速いな。もしかすると2番目の方か。そうするともっと計算負荷を大(今はスタックに収まる100x100サイズ、結構小さい)にしないとマルチスレッドの方が速いぜという期待の結果にならないかも。グズグズだな。