前回は素朴な2次元ループ、勿論シングルスレッドで行列積を求めました。今回はこれに手をいれてマルチスレッド化してみたいと思います。調べたところ「データ並列を活用」するrayonクレートというものが魅力的だったのですが、今回はRustのフツー?のthreadを使ってRust風の並列化を学んでいきたいと思います。
※『RustにいればRustに従え』関係記事 index はこちら
※動作確認は、Windows11のWSL2上にインストールしたUbuntu20.04LTS上のrustc 1.64.0 (a55dd71d5 2022-09-19) で行っています。
今回の並列化
参照させていただいたのはいつもお世話になっております。「The Rust Programming Language 日本語版」様の以下のページです。
具体的に言えば
thread::spawn()
でスポポンとスレッドを生成し、各スレッドの生成物は
mpsc::channel()
というチャネルを経由して受け取ります。アカラサマなメモリ共有などに比べたら遥かに安心?
Rustのドキュメントを読んでいたのにGo言語のスローガンだという以下が登場してきてちょいとドギマギしました。以下引用させていただきます。
メモリを共有することでやり取りするな; 代わりにやり取りすることでメモリを共有しろ
Go言語も学んでおるのですが、そのようなスローガンのところまで行きついておりませぬ。不勉強ぞなもし。
並列化する場所
行列積の計算を考えると積の各要素毎の計算は全て並列化可能、さらに各要素を求める部分も全ての掛け算は並列化可能。足し込んでいくところも折りたたまねばならないものの、並列化可能であります。さすれば高度な並列化可能であろうと。まあそういう操作のためには rayon クレートが良い感じだなと思ったのですが(勝手にCPUコアの個数くらいのスレッドにしてくれるみたいだし)、今回はチマチマとspawnで1個1個スレッドをこさえてみます。行列を半分づつに分けてそれぞれの処理をスレッドにお任せするという控えめさです。
前回のコードでスレッド化する部分は以下の部分です。
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE {
array_c[i][j] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
上記の何のこともない行列計算を代入対象を2つに分割することで以下のようにしました(以下は「半分」を処理するAスレッド)
let handle_a = thread::spawn(move || {
let mut array_ca: [[i32; ARRAYSIZE/2]; ARRAYSIZE] = [[0; ARRAYSIZE/2]; ARRAYSIZE];
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE/2 {
array_ca[i][j] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
txa.send(array_ca).unwrap();
});
計算した値を保持するための一時記憶はスレッド内で確保しているので、他のスレッドは無関係、さらに結果はチャネルを使ってメインスレッドにsendするので共有メモリの待ち合わせがどうとかとか心配する必要もないハズ。
実験につかった全ソース
実験に使った全ソースが以下に。行列積を半分こして計算するスレッドA、B以外にメインスレッドで従前のやり方でも計算してもらってます。
use rand::Rng;
use std::thread;
use std::sync::mpsc;
const ARRAYSIZE: usize = 10;
fn make_random_array() -> [[i32; ARRAYSIZE]; ARRAYSIZE] {
let mut temp_array: [[i32; ARRAYSIZE]; ARRAYSIZE] = [[0; ARRAYSIZE]; ARRAYSIZE];
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE {
temp_array[i][j] = rand::thread_rng().gen_range(0..256);
}
}
return temp_array;
}
fn print_array(nam: &str, ary: [[i32; ARRAYSIZE]; ARRAYSIZE]) {
println!("{}", nam);
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE {
print!("{},",ary[i][j]);
}
println!();
}
println!();
}
fn print_array2(nam: &str, arya: [[i32; ARRAYSIZE/2]; ARRAYSIZE], aryb: [[i32; ARRAYSIZE/2]; ARRAYSIZE]) {
println!("{}", nam);
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE {
if j < ARRAYSIZE/2 {
print!("{},",arya[i][j]);
} else {
print!("{},",aryb[i][j-ARRAYSIZE/2]);
}
}
println!();
}
println!();
}
fn main() {
println!("mult_array spawn & channel");
let array_a: [[i32; ARRAYSIZE]; ARRAYSIZE] = make_random_array();
let array_b: [[i32; ARRAYSIZE]; ARRAYSIZE] = make_random_array();
let mut array_c: [[i32; ARRAYSIZE]; ARRAYSIZE] = [[0; ARRAYSIZE]; ARRAYSIZE];
let (txa, rxa) = mpsc::channel();
let (txb, rxb) = mpsc::channel();
let handle_a = thread::spawn(move || {
let mut array_ca: [[i32; ARRAYSIZE/2]; ARRAYSIZE] = [[0; ARRAYSIZE/2]; ARRAYSIZE];
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE/2 {
array_ca[i][j] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
txa.send(array_ca).unwrap();
});
let handle_b = thread::spawn(move || {
let mut array_cb: [[i32; ARRAYSIZE/2]; ARRAYSIZE] = [[0; ARRAYSIZE/2]; ARRAYSIZE];
for i in 0..ARRAYSIZE {
for j in (ARRAYSIZE/2)..ARRAYSIZE {
array_cb[i][j-ARRAYSIZE/2] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
txb.send(array_cb).unwrap();
});
for i in 0..ARRAYSIZE {
for j in 0..ARRAYSIZE {
array_c[i][j] = (0..ARRAYSIZE).fold(0, |acc, x| acc + array_a[i][x] * array_b[x][j]);
}
}
let received_a = rxa.recv().unwrap();
let received_b = rxb.recv().unwrap();
handle_a.join().unwrap();
handle_b.join().unwrap();
print_array("A", array_a);
print_array("B", array_b);
print_array("C", array_c);
print_array2("C_AB", received_a, received_b);
}
実験結果
実行結果の先頭部分が以下に。
途中抜かして末尾の結果が以下に。行列Cが従前の方法のメインスレッドの結果で、行列C_ABは2スレッド並列で処理した結果です。OKそうね。
ただ、今回のような10x10サイズであると、スレッド生成のオーバヘッド時間の方が、計算時間より長いみたいでスレッドが並列に走ってるんだよね、というオシルシが示せませんでした。そこでこっそり100x100サイズに変更してみたものの「実行履歴」が以下に(各スレッドのループ処理の前後にprintln!を入れてある)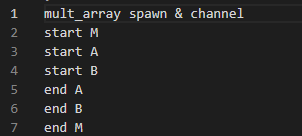
メインスレッドがまず走りはじめ、つづいてA、それからBと処理を開始。最初に終わるのはAで、その後B、そして最後Mです。こうしてみればA,B,Mの3者は並行に処理されてるみたいデス。