前回、行列積のマルチスレッド計算の実行時間を測っていて、測定対象の計算負荷がスレッドのあれやこれやのオーバヘッドに比較して「軽め」なんでないの?という疑問を持ちました。それというのもスタック上に配列をとったがためのサイズ制限です。現代的なプロセッサにとっては100x100サイズなどは軽すぎる?
※『RustにいればRustに従え』関係記事 index はこちら
※動作確認は、Windows11のWSL2上にインストールしたUbuntu20.04LTS上のrustc 1.64.0 (a55dd71d5 2022-09-19) で行っています。
Rustの配列型とVec型
静的に決まったサイズのメモリを割り当てる配列型と、動的にメモリ確保することができるVec型、どっちを使うか考えたときにやっぱ配列だぜ、と考えたのが大間違いでした。メモリ確保のためのオーバヘッドがないからいいんじゃない、などと短絡思考。しかし配列型には制限がありました。
-
- 配列はスタック上にとられる
- スタックサイズはあらかじめ固定(変更する手段もあるがメンドイ)
単純な行列積の計算(全要素32ビット符合付整数型)なので、制限あっても結構なサイズまでいけるんでないの?第10回でその辺をちょっと調べてますが、実際にコードを書いてみると、複数個の配列を確保せねばならず、実際に使える配列のサイズは数百x数百くらいがいいところでした。現代のプロセッサにとって、そんなサイズは吹けば飛ぶような計算負荷?のようです。まあ、回数を回して時間を長くするのも手ですが、実際の問題考えたら「大きな配列」を確保する方が自然デス。
そこで今回行列の置き場所をVec型に変更することにいたしました。
-
- Vecはヒープ上にとられる
- ヒープであれば巨大なメモリを確保できるんでないの?
問題は、何も考えないでコードすると時折メモリのアロケーションが走りそうなことですが、最初に必要量を切り出してから始めれば大丈夫だろ~と考えました。知らんけど。
Vec型で書き直したシングルスレッドの行列積
動作確認のため、第11回相当の単純(かつ小サイズ)な掛け算コードを書き直してみました。行列 a と 行列 b に乱数を詰めて、その行列積を行列 c に格納します。正方行列のみ。サイズを制御する定数はARRAYSIZEです。今回はサイズを10としてありますが、1000としても動作するみたいっす。さすがに1000×1000とかくらいになると負荷は重くなるっしょ。前回の1000倍くらい?
use rand::Rng;
const ARRAYSIZE: usize = 10;
fn make_randam_vec(siz: usize) -> Vec<i32> {
let mut vec: Vec<i32> = Vec::with_capacity(siz*siz);
for _i in 0..(siz*siz) {
vec.push(rand::thread_rng().gen_range(0..256));
}
return vec;
}
fn print_array(nam: &str, siz: usize, vec: Vec<i32>) {
println!("{}", nam);
for i in 0..siz {
for j in 0..siz {
print!("{},",vec[i*siz + j]);
}
println!();
}
println!();
}
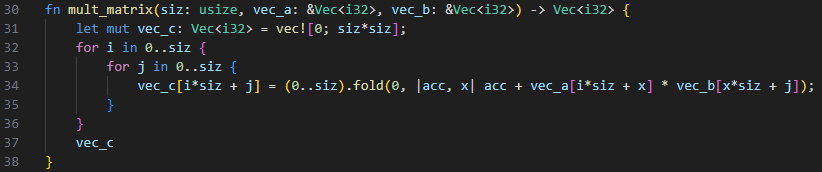
fn mult_matrix(siz: usize, vec_a: &Vec<i32>, vec_b: &Vec<i32>) -> Vec<i32> {
let mut vec_c: Vec<i32> = vec![0; siz*siz];
for i in 0..siz {
for j in 0..siz {
vec_c[i*siz + j] = (0..siz).fold(0, |acc, x| acc + vec_a[i*siz + x] * vec_b[x*siz + j]);
}
}
vec_c
}
fn main() {
println!("Mult_2d_matrix on vector\n");
let vec_a: Vec<i32> = make_randam_vec(ARRAYSIZE);
let vec_b: Vec<i32> = make_randam_vec(ARRAYSIZE);
let vec_c: Vec<i32> = mult_matrix(ARRAYSIZE, &vec_a, &vec_b);
print_array("vec_a:", ARRAYSIZE, vec_a);
print_array("vec_b:", ARRAYSIZE, vec_b);
print_array("vec_c:", ARRAYSIZE, vec_c);
}
とりあえず cargo run で動作確認
まずは、ちんまい10×10サイズ、最適化なしで動作させて、ただしく結果が得られることを確認しました。こんな感じ。
なお、乱数使っているので、Cargo.tomlファイルに、忘れずに “rand” 使うよと依存関係を書き込んでおく必要があります。
第11回レベルに戻ったので、サイズをデカくして(1スレッドあたりの負荷を重くして)また時間測定をやってみるつもりです。しつこいな。