毎度ですがA64の命令多すぎ。今回練習するのはSIMDのシフト命令です。符合付/符号無、サチュレーションの有無、丸めの有無で2の3乗、合計8種のニーモニックが存在します。そしてニーモニック上はLEFTと読めるので左シフトだけかと思えば「負の左シフトは右シフト」ということで右シフトも出来。でもこれだけじゃなかったんだ。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
SIMDのシフト演算
前回はサチュレーション演算の練習とて、加減算についてサチュレーションの有無を含めて合計6個のニーモニックを演習してみました。これだって少なくはないですが、今回のシフト演算はニーモニック8個です。内訳はこんな感じ。
| 操作 | 符号付 | 符号無 |
|---|---|---|
| サチュレーション左シフト | SQSHL | UQSHL |
| サチュレーション左シフト丸め | SQRSHL | UQRSHL |
| 左シフト | SSHL | USHL |
| 左シフト丸め | SRSHL | URSHL |
ニーモニック的には左シフトばかりに見えますが、上記命令のシフト回数はソース第2オペランドのレジスタで指定です。先ほど書いたとおり「負の左シフトは右シフト」というロジックなんであります。引数によっては右シフトにもなります。ややこしい?
なお、ソース第1オペランドの内容を、ソース第2オペランドで指定するビット数シフトしてデスティネーションに書き込む形です。
SIMDレジスタ的にはバイト、ハーフワード、ワード、ダブルワードのSIMD要素幅と、レジスタ幅64ビット/128ビットの選択が可能なので計8種類の「幅」に対応してます。
命令セットは上記の部分は「対称で綺麗」です。符合付か符号無か、サチューレーションするかしないか、丸めるか丸めないか。しかし「騙されて」はいけませぬぞ。この部分が綺麗な対称であるだけで、まだシフト系の命令は沢山隠れているのであります。引数がレジスタ指定でないものが。まあ今回は練習しないので流しますが。。。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。例によってメンドクセーので、バイト幅エレメントの半幅レジスタのみで実習をしてみます。
.globl sqshl8V, uqshl8V, sqrshl8V, uqrshl8V, sshl8V, ushl8V, srshl8V, urshl8V
.text
.balign 4
sqshl8V:
ld1 {v1.8B, v2.8B}, [x0], #16
sqshl v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
uqshl8V:
ld1 {v1.8B, v2.8B}, [x0], #16
uqshl v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
sqrshl8V:
ld1 {v1.8B, v2.8B}, [x0], #16
sqrshl v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
uqrshl8V:
ld1 {v1.8B, v2.8B}, [x0], #16
uqrshl v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
sshl8V:
ld1 {v1.8B, v2.8B}, [x0], #16
sshl v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
ushl8V:
ld1 {v1.8B, v2.8B}, [x0], #16
ushl v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
srshl8V:
ld1 {v1.8B, v2.8B}, [x0], #16
srshl v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
urshl8V:
ld1 {v1.8B, v2.8B}, [x0], #16
urshl v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。これまたいつもの通りの手抜きで前回ソースのチョイ変デス。再度お断りすると sが頭についているニーモニックは符合付なのですが、C言語レベルでは全てuint8_t引数に対して操作させてます(どうせアセンブラにはCのレベルなど関係ねー。)
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (24)
uint8_t TargetMEM[MAXMEM];
extern void sqshl8V(uint8_t *);
extern void uqshl8V(uint8_t *);
extern void sqrshl8V(uint8_t *);
extern void uqrshl8V(uint8_t *);
extern void sshl8V(uint8_t *);
extern void ushl8V(uint8_t *);
extern void srshl8V(uint8_t *);
extern void urshl8V(uint8_t *);
void initTGT() {
TargetMEM[0] =0x7F;
TargetMEM[1] =0xFF;
TargetMEM[2] =0x02;
TargetMEM[3] =0x01;
TargetMEM[4] =0x7F;
TargetMEM[5] =0xFF;
TargetMEM[6] =0x02;
TargetMEM[7] =0x01;
TargetMEM[8] =0x01;
TargetMEM[9] =0x01;
TargetMEM[10]=0x01;
TargetMEM[11]=0x01;
TargetMEM[12]=0xFF;
TargetMEM[13]=0xFF;
TargetMEM[14]=0xFF;
TargetMEM[15]=0xFF;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%02x opr 0x%02x -> 0x%02x \n", i, TargetMEM[i], TargetMEM[i+8], TargetMEM[i+16]);
}
}
int main(void) {
initTGT();
sqshl8V(TargetMEM);
dumpTGT("sqshl");
uqshl8V(TargetMEM);
dumpTGT("uqshl");
sqrshl8V(TargetMEM);
dumpTGT("sqrshl");
uqrshl8V(TargetMEM);
dumpTGT("uqrshl");
sshl8V(TargetMEM);
dumpTGT("sshl");
ushl8V(TargetMEM);
dumpTGT("ushl");
srshl8V(TargetMEM);
dumpTGT("srshl");
urshl8V(TargetMEM);
dumpTGT("urshl");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 sqshl.c sqshl.s $ ./a.out
標準出力に「ダラダラ」現れた結果を、上下左右比べ易いように折りたたんだものが以下に。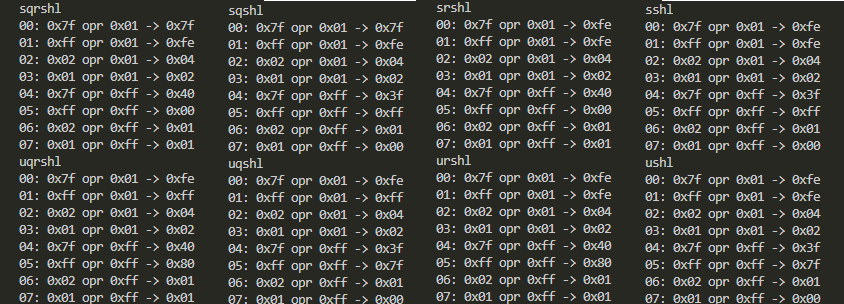
上下を見比べると符号付き、符号無の挙動の差が、左右4列を見比べると、サチュレーションの有無、丸めの有無の挙動の差が見えるかと。こうして見比べればその差は明らかだけれど、そうじゃなければ見逃してる?