今回練習するのはSIMDの比較命令です。スカラー同士の比較であれば分岐のためですが、SIMDの場合は各要素の計算を「通すか否か」のマスク的なものの生成。今回対象は浮動小数比較でなく整数のみですが、いつものとおりA64の命令多すぎ。便利そうな命令は網羅するのがArmの行き方か。ミニマリストではないわいな。多分。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
SIMDの比較命令
A64の命令を「さらっと一通りなでる」だけのつもりなのですが、命令多すぎてすすみませぬ。今回はニーモニック数で9命令を練習するのですがそれで整数比較のみです。浮動小数はまたこんどね。ざっくりした表にまとめると以下の如し。
| 比較 | 符号付 | 符号無 |
|---|---|---|
| = | CMEQ | CMEQ |
| =0 | CMEQ | CMEQ |
| ≧ | CMGE | CMHS |
| ≧0 | CMGE | CMHS |
| > | CMGT | CMHI |
| >0 | CMGT | CMHI |
| ≦0 | CMLE | —- |
| <0 | CMLT | —- |
| bit test< | CMTST | CMTST |
整数型なので符合付と符号無あり。両方に適用できる命令もあれば、片方だけのものもあり。「グレーター」とか「レス」とか言ったら符合付、「ハイ」とか「セイム」とかいったら符合無っす。
比較条件を見てみると、対ゼロ比較、優遇されてます。ゼロ相手の比較であれば貴重なレジスタ1本使わずに比較できるっと。また、符合付の方が優遇されている感じ。対ゼロのみですが「レス・イコール」とか「レス・ザン」とかが存在します。符合無の方は「大なり」系しかないので、「小なり」系は条件ヒックリ返さないとならないのに。やるのはコンパイラ様の仕事だけど(アセンブラ書かなければ。)命令多すぎA64、使えるものは網羅するのだ。
実験に使ったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下です。例によってSIMD要素はバイト、ハーフワード、ワード、ダブルワードととれるのに、バイトのみです。いろいろなケースを網羅するためにSIMDレジスタは128ビット幅(バイト16要素並列)としてます。
今回はニーモニック数で9ですが、ゼロ相手とそうでない場合でソースオペラントの取り方が違うので関数的には多くなりました。メンドイのでゼロ相手の時も「不要な」第2ソースまでロードしています。手抜き。
.globl cmeq16V, cmhs16V, cmge16V, cmhi16V, cmgt16V, cmleZ16V, cmltZ16V, cmtst16V, cmeqZ16V, cmgeZ16V, cmgtZ16V
.text
.balign 4
cmeq16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmeq v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
cmhs16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmhs v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
cmge16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmge v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
cmhi16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmhi v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
cmgt16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmgt v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
cmleZ16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmle v0.16B, v1.16B, #0
st1 {v0.16B}, [x0]
ret
cmltZ16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmlt v0.16B, v1.16B, #0
st1 {v0.16B}, [x0]
ret
cmtst16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmtst v0.16B, v1.16B, v2.16B
st1 {v0.16B}, [x0]
ret
cmeqZ16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmeq v0.16B, v1.16B, #0
st1 {v0.16B}, [x0]
ret
cmgeZ16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmge v0.16B, v1.16B, #0
st1 {v0.16B}, [x0]
ret
cmgtZ16V:
ld1 {v1.16B, v2.16B}, [x0], #32
cmgt v0.16B, v1.16B, #0
st1 {v0.16B}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。毎度のお断りですが、符合付操作も、C言語レベルでは全てuint8_t引数に見えます。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (48)
uint8_t TargetMEM[MAXMEM];
extern void cmeq16V(uint8_t *);
extern void cmeqZ16V(uint8_t *);
extern void cmhs16V(uint8_t *);
extern void cmge16V(uint8_t *);
extern void cmhi16V(uint8_t *);
extern void cmgt16V(uint8_t *);
extern void cmleZ16V(uint8_t *);
extern void cmltZ16V(uint8_t *);
extern void cmtst16V(uint8_t *);
extern void cmgeZ16V(uint8_t *);
extern void cmgtZ16V(uint8_t *);
void initTGT() {
TargetMEM[0] =0x00;
TargetMEM[1] =0x01;
TargetMEM[2] =0x7E;
TargetMEM[3] =0x7F;
TargetMEM[4] =0x80;
TargetMEM[5] =0x81;
TargetMEM[6] =0xFE;
TargetMEM[7] =0xFF;
TargetMEM[8] =0x00;
TargetMEM[9] =0x01;
TargetMEM[10]=0x7E;
TargetMEM[11]=0x7F;
TargetMEM[12]=0x80;
TargetMEM[13]=0x81;
TargetMEM[14]=0xFE;
TargetMEM[15]=0xFF;
TargetMEM[16]=0x01;
TargetMEM[17]=0x01;
TargetMEM[18]=0x01;
TargetMEM[19]=0x01;
TargetMEM[20]=0x01;
TargetMEM[21]=0x01;
TargetMEM[22]=0x01;
TargetMEM[23]=0x01;
TargetMEM[24]=0x81;
TargetMEM[25]=0x81;
TargetMEM[26]=0x81;
TargetMEM[27]=0x81;
TargetMEM[28]=0x81;
TargetMEM[29]=0x81;
TargetMEM[30]=0x81;
TargetMEM[31]=0x81;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 16; i++) {
printf("%02d: 0x%02x opr 0x%02x -> 0x%02x \n", i, TargetMEM[i], TargetMEM[i+16], TargetMEM[i+32]);
}
}
void dumpTGTZ(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 16; i++) {
printf("%02d: 0x%02x opr 0 -> 0x%02x \n", i, TargetMEM[i], TargetMEM[i+32]);
}
}
int main(void) {
initTGT();
cmeq16V(TargetMEM);
dumpTGT("cmeq");
cmeqZ16V(TargetMEM);
dumpTGTZ("cmeq zero");
cmhs16V(TargetMEM);
dumpTGT("cmhs");
cmge16V(TargetMEM);
dumpTGT("cmge");
cmhi16V(TargetMEM);
dumpTGT("cmhi");
cmgt16V(TargetMEM);
dumpTGT("cmgt");
cmtst16V(TargetMEM);
dumpTGT("cmtst");
cmleZ16V(TargetMEM);
dumpTGTZ("cmle zero");
cmltZ16V(TargetMEM);
dumpTGTZ("cmlt zero");
cmgeZ16V(TargetMEM);
dumpTGTZ("cmge zero");
cmgtZ16V(TargetMEM);
dumpTGTZ("cmgt zero");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdcmpi.c simdcmpi.s $ ./a.out
結果は比較しやすいように「近縁なもの」同士を並べてみました。
-
- CMEQ、CMEQ(即値ゼロ)、CMTST
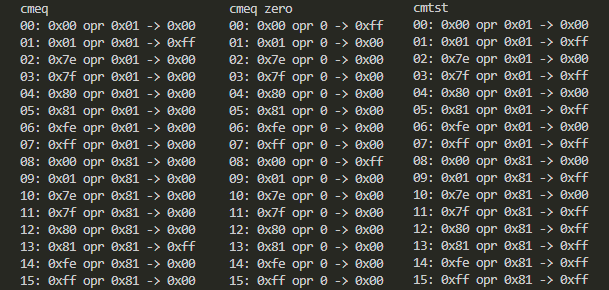
CMTSTは、ソース1とソース2のANDをとって0だったらオール0、非0ならオール1です。
-
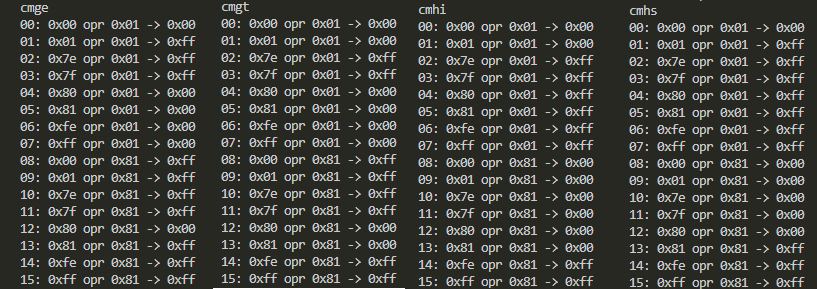
- CMGE、CMGT、CMHI、CMHS
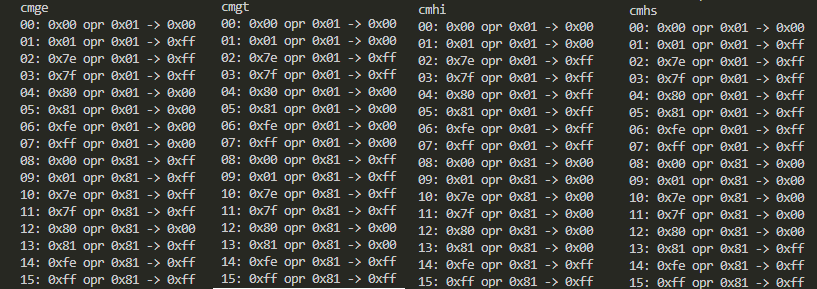
「大なり」系4種のそろい踏みですが、符号の有り無、イコールを含む含まないで挙動が変化するのが分かるかと思います。
-
- 全て即値ゼロに対するCMGE、CMGT、CMLE、CMLT
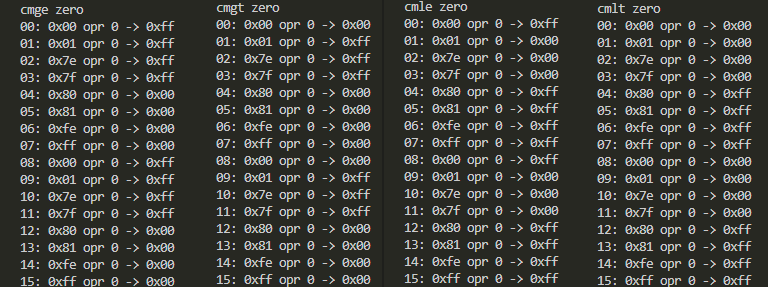
対ゼロ系比較は充実。