SIMD要素のビット幅が変化する命令群の練習の最後は乗算系です。今まで練習してきた加算系、減算系と異なり、ビット幅が狭くなる方向の命令はありません。そして広くなる方向にWideとLongの2種類の区別があるとかもありません。だから命令数少ないかと言ったらそうはいかないA64です。18個とな。命令多過ぎA64。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
要素ビット幅変、乗算系にはlongしかない
ビット幅が広くなる方向の「long」しかない乗算系ですが、今までやってきた通りで、
-
- 符合付、符号無の区別あり
- 乗算のみ、積和算、積差算の3種別あり
- さらに「飽和ダブリング」計算が、符合付のみあり
- そのうえ「2」が付くか、付かないかソースレジスタ指定の上下あり
ということで合計18命令が存在します。数は多いけれどもちょっと非対称。A64らしいといえばA64らしいデス。表にするとこんな感じ。
| sign/unsign | from the lower half | from the upper half |
|---|---|---|
| signed multiply-add long | SMLAL | SMLAL2 |
| signed multiply-subtract long | SMLSL | SMLSL2 |
| signed multiply long | SMULL | SMULL2 |
| signed saturating doubling multiply-add long | SQDMLAL | SQDMLAL2 |
| signed saturating doubling multiply-subtract long | SQDMLSL | SQDMLSL2 |
| signed saturating doubling multiply long | SQDMULL | SQDMULL2 |
| unsigned multiply-add long | UMLAL | UMLAL2 |
| unsigned multiply-subtract long | UMLSL | UMLSL2 |
| unsigned multiply long | UMULL | UMULL2 |
実験に使ったアセンブリ言語記述の被テスト関数
今回は18個全部を練習する気力がとてもないので、まず「2」付はバッサリとさせていただきました。その上で積和演算のみ練習。よって18÷2÷3で3個とな。手抜き。毎度のことですが。アセンブリ言語ソースが以下に。
おっといけない、UMLALとかSMLALにはバイト幅ソースを掛け合わせてハーフワード幅デスティネーションに積算する命令があるのですが、「サチュレーション付きダブリング」演算にはバイト幅ソース無いようなのです、マニュアルによれば。よって、ハーフワード幅ソースを掛けてワード幅デスティネーションに書き込む命令を練習してます。いろいろあるのねA64。
.globl umlal8V, smlal8V, sqdmlal4V
.text
.balign 4
umlal8V:
ld1 {V0.8H, v1.8H, v2.8H}, [x0]
umlal v0.8H, v1.8B, v2.8B
st1 {v0.8H}, [x0]
ret
smlal8V:
ld1 {V0.8H, v1.8H, v2.8H}, [x0]
smlal v0.8H, v1.8B, v2.8B
st1 {v0.8H}, [x0]
ret
sqdmlal4V:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
sqdmlal v0.4S, v1.4H, v2.4H
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。実際のアセンブリ言語命令では符号付き命令でも、例によってCのレベルでは全て符号無型で割り切って書いているもの。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (24)
#define MAXMEM2 (12)
uint16_t TargetMEM[MAXMEM];
uint32_t TargetMEM2[MAXMEM2];
extern void umlal8V(uint16_t *);
extern void smlal8V(uint16_t *);
extern void sqdmlal4V(uint32_t *);
void initTGT() {
TargetMEM[0] = 0x0100;
TargetMEM[1] = 0x0100;
TargetMEM[2] = 0x0100;
TargetMEM[3] = 0x0100;
TargetMEM[4] = 0x0100;
TargetMEM[5] = 0x0100;
TargetMEM[6] = 0x0100;
TargetMEM[7] = 0x0100;
TargetMEM[8] = 0x1010;
TargetMEM[9] = 0x2020;
TargetMEM[10] = 0x8080;
TargetMEM[11] = 0x9090;
TargetMEM[12] = 0x0000;
TargetMEM[13] = 0x0000;
TargetMEM[14] = 0x0000;
TargetMEM[15] = 0x0000;
TargetMEM[16] = 0x1701;
TargetMEM[17] = 0x8121;
TargetMEM[18] = 0x8701;
TargetMEM[19] = 0xFF91;
TargetMEM[20] = 0x0000;
TargetMEM[21] = 0x0000;
TargetMEM[22] = 0x0000;
TargetMEM[23] = 0x0000;
}
void initTGT2() {
TargetMEM2[0] = 0x00010000;
TargetMEM2[1] = 0x00010000;
TargetMEM2[2] = 0x00010000;
TargetMEM2[3] = 0x7FFF0000;
TargetMEM2[4] = 0x00010001;
TargetMEM2[5] = 0x00020001;
TargetMEM2[6] = 0x00000000;
TargetMEM2[7] = 0x00000000;
TargetMEM2[8] = 0x7FFF0001;
TargetMEM2[9] = 0x7FFFFFFF;
TargetMEM2[10] = 0x00000000;
TargetMEM2[11] = 0x00000000;
}
uint16_t getLow(int idx, int pos) {
if (idx & 0x01) {
return (TargetMEM[(idx>>1)+pos] >> 8) & 0xFF;
} else {
return TargetMEM[(idx>>1)+pos] & 0xFF;
}
}
uint32_t getLow2(int idx, int pos) {
if (idx & 0x01) {
return (TargetMEM2[(idx>>1)+pos] >> 16) & 0xFFFF;
} else {
return TargetMEM2[(idx>>1)+pos] & 0xFFFF;
}
}
void dumpTGTL(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%02x opr 0x%02x -> 0x%04x\n", i, getLow(i, 8), getLow(i, 16), TargetMEM[i]);
}
}
void dumpTGTL2(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 4; i++) {
printf("%02d: 0x%04x opr 0x%04x -> 0x%08x\n", i, getLow2(i, 4), getLow2(i, 8), TargetMEM2[i]);
}
}
int main(void) {
initTGT();
umlal8V(TargetMEM);
dumpTGTL("umlal");
initTGT();
smlal8V(TargetMEM);
dumpTGTL("smlal");
initTGT2();
sqdmlal4V(TargetMEM2);
dumpTGTL2("sqdmlal");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。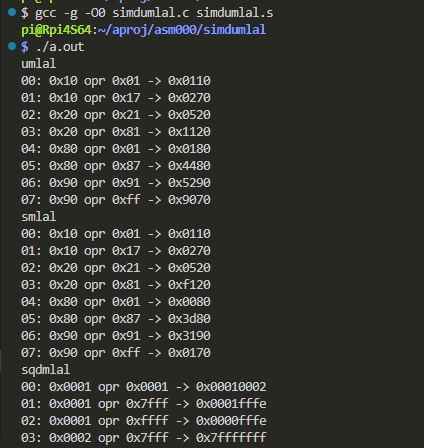
sqdmlalの3番目、サチュレーションがかかっているのが分かりますか?コマケー話だが。