Bootパッケージ中をABC順に巡回中。今回は地球の重力加速度の測定です。「とうとう出たね」というのもBootパッケージの場合、データセット毎には処理例の記載なく、処理関数毎に処理例が記載されているのですが、パッケージ内約40関数のうち10関数までがgravityを処理対象にした処理例を記載しているためです。人気者?
※「データのお砂場」投稿順Indexはこちら
gravity サンプルデータセット
今回のサンプルデータセットは、地球の重力加速度を測定したデータです。1930年代の測定データですが、百年近く前とはいえ、この手の物理実験は相当に精度よくできていたハズ。また測定したのは当時の米国立標準局、現在のNIST(National Institute of Standards and Technology)だそうです。
サンプルデータセットの解説ページが以下に
該当するサンプルデータセットは以下の2つ存在します。
-
- grav
- gravity
測定は振り子を使って行ったようですが、測定の設定が微妙に異なる8通りで行われたみたいです。それらをシリーズと称しているのですが、gravityには全8通りのデータが含まれ、gravには最後の2通りのデータのみが含まれてます。今回行ってみた処理例をみるとgravityからseries 7, 8 のみ取り出してました。ということはgravでもgravityでも結果は同じってことかい。
このgravityを処理対象にした処理例を記載しているbootパッケージ内の関数を列挙すると以下のとおりです。
-
- abc.ci、 Nonparametric ABC Confidence Intervals
- boot、 Bootstrap Resampling
- boot.ci、 Nonparametric Bootstrap Confidence Intervals
- empinf、 Empirical Influence Values
- envelope、 Confidence Envelopes for Curves
- exp.tilt、 Exponential Tilting
- Imp.Estimates、 Importance Sampling Estimates
- plot.boot、 Plots of the Output of a Bootstrap Simulation
- smooth.f、 Smooth Distributions on Data Points
- tilt.boot、 Non-parametric Tilted Bootstrap
年寄には上記10個を一度に練習する気力も体力もないので、今回は、まずは「本流」2のbootと3のboot.ciをやってみたいと思います。
なお、重力加速度の測定値として記載されている数値は上記の解説ページの記述では980.000 cm/s2 からの偏差だみたいなことが書かれているのですが、cm毎秒毎秒としてもかなりデカイデータが記載されてます。100年前でもそんなに精度が悪かったとは思えません。980ではなく、900を基準として下2桁cm以下を記載と考えると腑に落ちるのですが。。。知らんけど。
boot.ci
bootやboot.ciについては、『ねこすたっと』様の以下のページが大変分かり易かったです(忘却力の年寄はもう忘れとるけど。。。)あざ~す。
ブートストラップ(bootstrap)法で信頼区間を求める(bootパッケージ)[R]
まずは生データ
生データは、grav、gravityとも単純なデータ・フレームです。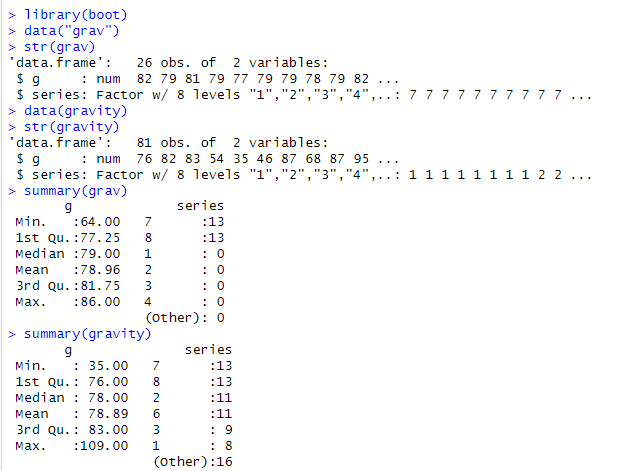
先ほど述べたように、gravはgravityのseries 7と8を取り出したデータのようです。ただし上記のsummaryではseriesを無視して平均求めているので今イチです。そこでシリーズ毎のデータの平均を求めておきました。こんな感じ。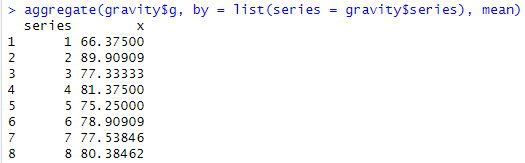
処理例2つ
boot関数およびboot.ci関数の両方に処理例が記載されておりますが、中身はクリソツ。差はこんな感じ。
-
- diff.means関数は全くおなじ
- boot関数を呼び出すときの引数は同じ、しかし微妙に文字表記(スペースなど)異なる。なお後で使うのでboot.ciの例では処理後変数へ代入
- boot.ciの処理例では、boot関数処理の後にboot.ci関数の適用がつづく
boot.ciの方にそってやっていけば、両方やったことになるかと。やりたいことは、シリーズ7と8で得られる平均値の差をbootでシミュレーションして、その信頼区間をboot.ciで求めたいということみたい。知らんけど。
まずはboot関数の適用。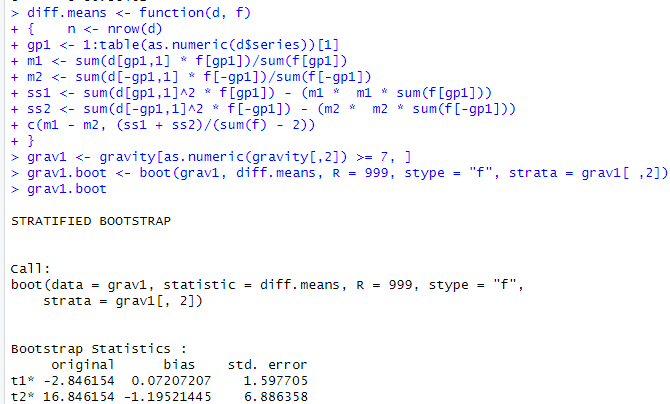
strata = のところでシリーズ7とシリーズ8を層別して計算しているらしいことは分かるのだけれども、stype=”f”って何。frequenciesだと。なんじゃその指定は。元より統計もRも素人、とまどうこと頻りであります。
数字で眺めてもサッパリなのでグラフにしてもらいました。こんな感じ。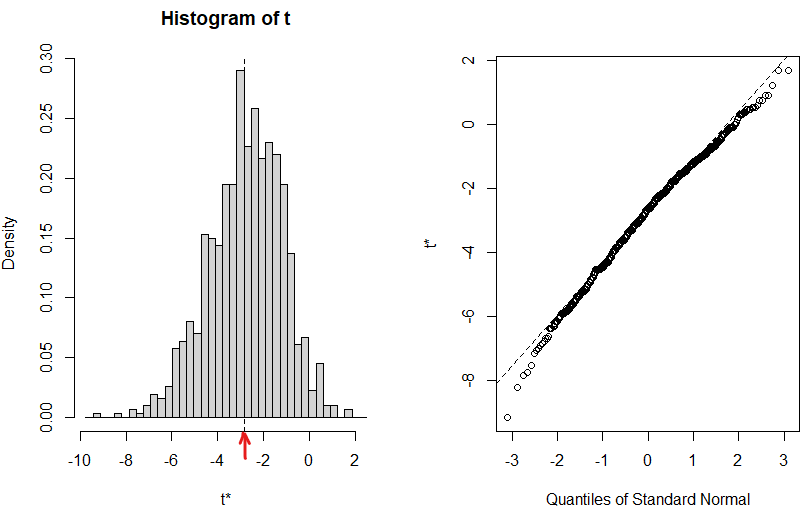
上記を見ると、シリーズ7は約3[cm/s2、多分]弱くらい下目なデータに見えるってことかい?いいのかそういう理解で?
さてその95%信頼区間の計算が以下に。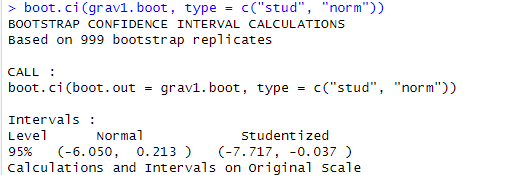
ここでも student先生のお名前を冠したらしい「studentized」登場。もう一方のnormalは正規分布想定の場合らしいデス。
処理例は計算できるけれども、統計素人の老人にはなんやら難しくてよう分かりません。このデータに後8つも処理例があるのか。。。何をするのだ?