「SIMDレジスタの一方の全要素に他方の一要素を共通に掛け算」する系統の命令があまりに数が多いです。前回それらを表にまとめました。今回はそれらの中から「シンプル」な浮動小数の乗算、積和算、積差算を練習してみたいと思います。シンプルとは言え積和が出てくると fused計算を避けて通れませぬ。fusedの効果確認メンドい
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
FMUL、FMLA、FMLS
SIMD by element arithmetic命令群のうち、
-
- FMUL、浮動小数乗算
- FMLA、浮動小数積和算
- FMLS、浮動小数積差算
です。いずれも、ソース1のSIMDレジスタの全要素に、ソース2のSIMDレジスタの特定要素を乗じたのち、デスティネーションレジスタに乗算結果を代入するだけならFMUL、デスティネーションの元の値に乗算結果を加えた上でデスティネーションに書き戻せばFMLA、デスティネーションの元の値から乗算結果を減じた後デスティネーションに書き戻せばFMLSです。
FMULであれば単純な乗算なのでfused演算は出てきません。しかし、FMLAとFMLSでは演算はfusedです。通常、乗算と加減算命令を別々に行った場合、乗算後と加減算後の2回丸めが実施されます。しかし、fused演算命令では乗算後の丸めはスキップされて、加減算後の1回の丸めにまとめられます。浮動小数点素人にとってはコマケー話なのですが、浮動小数の積和算などは非常な回数行われることが多いのでチリツモでも死命を制するらしいです。知らんけど。
なお、以下の過去回でfusedの件は扱っております。
ぐだぐだ低レベルプログラミング(112)ARM64(AArach64)積和は”fused”
今回の練習で使った値は上記の値をコピペ。能がないのう。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。例によってArm v8.0では半精度なく、単精度と倍精度のみのサポートです。単精度のみ練習。また、今回はfused演算と通常演算の「差」もみせないとならないので、比較用のFMULとFADDを連続して行う関数も実装してます。FMLAだけね。FMLSとの比較は省略。
.globl fmul4V, fmla4V, fmls4V, fmuladd4V
.text
.balign 4
fmul4V:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
fmul v0.4S, v1.4S, v2.4S[1]
st1 {v0.4S}, [x0]
ret
fmla4V:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
fmla v0.4S, v1.4S, v2.4S[1]
st1 {v0.4S}, [x0]
ret
fmls4V:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
fmls v0.4S, v1.4S, v2.4S[1]
st1 {v0.4S}, [x0]
ret
fmuladd4V:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
fmul v1.4S, v1.4S, v2.4S[1]
fadd v0.4S, v0.4S, v1.4S
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。fused演算の結果をみるためにはFloat型の内部表現の下の方を探らんとならないので、メンドイことになってます。
#include <stdio.h>
#include <stdint.h>
typedef union {
float s;
uint32_t u;
} dut;
extern void fmul4V(dut *);
extern void fmla4V(dut *);
extern void fmls4V(dut *);
extern void fmuladd4V(dut *);
#define MAXMEM (12)
dut TargetMEM[MAXMEM];
void initTGT() {
TargetMEM[0].s = 0.000003f;
TargetMEM[1].s = 0.000003f;
TargetMEM[2].s = 0.000003f;
TargetMEM[3].s = 0.000003f;
TargetMEM[4].s = 0.0009992f;
TargetMEM[5].s = 0.0009993f;
TargetMEM[6].s = 0.0009992f;
TargetMEM[7].s = 0.0009993f;
TargetMEM[8].s = 1.1f;
TargetMEM[9].s = 1.1f;
TargetMEM[10].s = 1.1f;
TargetMEM[11].s = 1.1f;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 4; i++) {
printf("%02d: %2.8f opr %2.8f -> %2.8f(%08x)\n", i, TargetMEM[i+4].s, TargetMEM[i+8].s, TargetMEM[i].s, TargetMEM[i].u);
}
}
int main(void) {
initTGT();
fmul4V(TargetMEM);
dumpTGT("fmul v0.4S, v1.4S, v2.4S[1]");
initTGT();
fmla4V(TargetMEM);
dumpTGT("fmla v0.4S, v1.4S, v2.4S[1]");
initTGT();
fmuladd4V(TargetMEM);
dumpTGT("(fmul+fadd) v0.4S, v1.4S, v2.4S[1]");
initTGT();
fmls4V(TargetMEM);
dumpTGT("fmls v0.4S, v1.4S, v2.4S[1]");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdFMUL.c simdFMUL.s $ ./a.out
実機上での実行結果が以下に。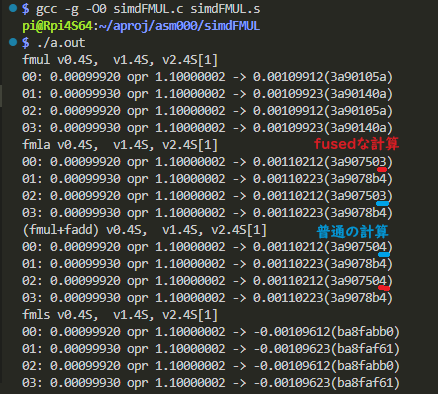
赤と青の色分けがちょっとこんがらがっているけれども、上がfused、下がフツーです。%fで浮動小数点表現しても同じ値に見えるけれども、ビット表現みると最後のビットが違っておる、と。