前回は、RISC-Vのサイクルカウンタを使って、GD32VF103の基本的な実行性能を測ってみました。そこで印象的だったのは、コードはFlashに置かれているのに、分岐しても特に大きな性能低下もなく、毎回きっちり同じ実行時間で処理されていることでした。シングルコア(シングルハードスレッド)のマイコンとしては、良い性質じゃないかと思います。今回は、データに対するメモリアクセスを調べてみます。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
- 以下投稿には誤りありです。お手数ですが以下もご参照ください。ぐだぐだ低レベルプログラミング(24) 訂正! GD32VF103、遅かったのは私のバグ
まずは、例によって、マニュアルやデータシートをちゃんと読んでいないので、泥縄式ですが、先週気になったユーザーマニュアルのプログラム・コードのフェッチに関する記述を読んでみます。GigaDevice社発行のGD32VF103 User Manualの「2.Flash memory controller(FMC)」から引用させていただきます。
There is no waiting time while CPU executes instructions stored in the flash.
ほほう、Flashから実行だけれども、ノーウエイト。カタログにはこのボードは108MHzと書かれていた(後で実行クロックを一応実測しておきます)です。その割にノーウエイトというのは立派なんでないかい。
でもね、ノーウエイトと胸を張っているプログラム実行に対して、内蔵メモリのリード/ライト性能については言及がありません。まあね、高々32KB RAMのマイコンなので、メモリアクセス命のプログラムを走らせることは多分ないでしょう。でも、一応、測っておきたい。一般的なマイコンでも、メモリの種類(SRAMとかFlashとか)やアドレス(どのバスに接続しているのか)により速度が大きく違うことが多いです。クロック速度に応じたウエイト値を設定しろとかいう面倒くさいマイコンもあるし(特に誰のとは言わないです。)
測るといって、対象は「リード」です。「ライト」の方は、書き込みを「ハードウエアにお願い」したらプログラムは先に進めることができるので、障害になることはまずありません。それに対して「リード」は、読んだデータを直後に使うのが普通なので、読み込みの速さがそのまま見えるからです。
読み込み対象は、Cのプログラムの方で定義しました。4バイトx256個=1Kバイトの配列です。1Kとすこし大きめにとったのは、多くのCPU COREがリード用のバッファ(例えていえばキャッシュと言わない小規模な一時記憶)などを内部に持っていて、アドレスによってはメモリに行かなかったりする「技」を使って高速化するからです。このマイコンの場合、1Kもある配列の中を飛び飛びにアクセスすれば、バッファなどあっても効きますまい。
ここで当てにしたのは、
- 普通に読み書きできる大域配列ならばSRAM上に確保されるよね。
- constで修飾してやった大域配列ならばFlash上に確保されるよね。
という事。念のため配列へのポインタを調べると期待どおり、GD32VF103のメモリマップのそれぞれSRAMとFlash内のアドレスを指していたのでOKです。
int sramArray[256] = {
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,15,
//~途中略~
15, 1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,15
};
const int romArray[256] = {
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,15,
//~途中略~
15, 1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,15
};
さて、結果は、例によってデバッグIFのUART経由でprintf出力です。ここもCです。呼び出すのは4種のコードなのですが、中身はほとんど同じ。
- cycRdMem メモリリードにかかるサイクルを数えるもの
- instRdMem メモリリードにかかる命令数を数えるもの
- cycRdNone cycRdMemのメモリリード命令だけコメントアウトしたもの
- instRdNone instRdMemのメモリリード命令だけコメントアウトしたもの
どれも引数は同じで
- 第1引数 アクセスするメモリ領域(配列)の先頭ポインタ
- 第2引数 先頭ポインタに最初に加算するオフセットアドレス
- 第3引数 繰り返しアクセスする場合に加算する繰り返しのアドレス間隔
- 第4引数 繰り返しの回数
であります。返ってくると、サイクルなり命令数なりを返してきます。
printf("SRAM : 0x%08x\n", sramArray);
work0 = cycRdMem(sramArray, 1, 16, 16);
work1 = instRdMem(sramArray, 1, 16, 16);
printf("SRAM CYCLE: %d\n", work0);
printf("SRAM INST : %d\n", work1);
printf("FLASH : 0x%08x\n", romArray);
work0 = cycRdMem(romArray, 1, 16, 16);
work1 = instRdMem(romArray, 1, 16, 16);
printf("FLASH CYCLE: %d\n", work0);
printf("FLASH INST : %d\n", work1);
work0 = cycRdNone(sramArray, 1, 16, 16);
work1 = instRdNone(sramArray, 1, 16, 16);
printf("NONE CYCLE: %d\n", work0);
printf("NONE INST : %d\n", work1);
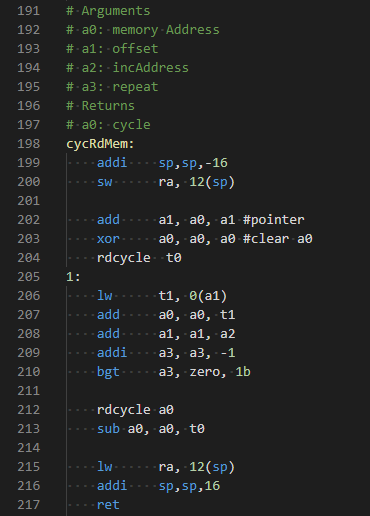
さて、上記のコードから呼び出されている関数の実体はアセンブラです。ごくごく簡単なコード。こんな感じ。
# Arguments
# a0: memory Address
# a1: offset
# a2: incAddress
# a3: repeat
# Returns
# a0: cycle
cycRdMem:
addi sp,sp,-16
sw ra, 12(sp)
add a1, a0, a1 #pointer
xor a0, a0, a0 #clear a0
rdcycle t0
1:
lw t1, 0(a1)
add a0, a0, t1
add a1, a1, a2
addi a3, a3, -1
bgt a3, zero, 1b
rdcycle a0
sub a0, a0, t0
lw ra, 12(sp)
addi sp,sp,16
ret
さて、実行結果はこちら。なんと予想に反して、SRAMでもFLASHでも実行サイクル数は変わらず。何度もループで走らせているのですが、結果にまったく変動なくこの値。命令数は予定どおり、その割に前回結果からするとサイクル数は長め。MEMとNONEの差をとればメモリリード命令16個分のサイクル数がもとまります。
- 以下には誤りありです。お手数ですが以下もご参照ください。ぐだぐだ低レベルプログラミング(24) 訂正! GD32VF103、遅かったのは私のバグ
144サイクル 割る 16 で 1命令あたり9サイクル
SRAM : 0x20000000 SRAM CYCLE: 245 SRAM INST : 81 FLASH : 0x080004a8 FLASH CYCLE: 245 FLASH INST : 81 NONE CYCLE: 101 NONE INST : 65
FLASH相手のアクセスとしたら「いいんじゃね」的な値かもしれません。が、SRAM相手としては物足りない感じもいたします。
しかし考えていみると、前回結果とは違うところもありますな。Call-Returnなど、今回の単純リードを上回る回数メモリ読んでいるのだけれどその割に早かったです。多分、何かあるのですね、細工が。考えると夜も眠れない(古すぎる!若者には。分かるかな、分かんねえだろうな。。。)