前回はPthreadを使って、スレッド数が多くなると処理時間が短くなるようなコードを書いてみました。今回はそれに最適化オプションを加えてみます。ヤバいな、ズルズルと深みにハマって行く感じがします。まずはCMakeの使い方もよく分かってないので、まずCMakeLists.txt内での最適化オプションの置き場所から調べないと。
※ソフトな忘却力 投稿順 index はこちら
(今回実験に使用のコードは前回のチョイ直しですが、あちこち変更しているのでソース全文を掲げました。Raspberry Pi OS<32bit>で動作しているRaspberry Pi 3機上のgcc8.3.0でテストしています。)
CMakeLists.txtの中のコンパイラフラグの置き場所
CMakeを良く知っている人は、こんなことに迷ったりしないんでしょうが、素人の私は、どこに置くべきか迷いました。調べると、あちこちに「置ける」場所があるのだもの。勝手な理解で以下のように整理してみました。上から順に適用されるので、後に書けば書くほどコマンドライン上の「後ろの場所」になるのではないかと思われます。
-
- 環境変数 CFLAGS を反映する変数 CMAKE_C_FLAGS
- ビルド時のコンフィギュレーションを反映する変数 CMAKE_C_FLAGS_DEBUGなど
- add_compile_options()
- target_compile_options()
第1は環境変数にセットしてある値を読み取って設定するCMakeの変数群です。そのうちC言語用(ソースファイルが .c のときに適用される)については以下に説明があります。
上記のページから1か所引用させていただくと、
Its initial value is taken from the calling process environment.
ということです。今回のコードはCですが、本シリーズで使う予定の言語の対応CMAKE変数と環境変数の関係を以下の表にまとめておきます。
| CMAKE変数 | 環境変数 |
|---|---|
| CMAKE_C_FLAGS | CFLAGS |
| CMAKE_CXX_FLAGS | CXXFLAGS |
| CMAKE_CUDA_FLAGS | CUDAFLAGS |
基本、環境変数の値を反映するための仕組みなので、積極的に上書きする理由は無いような気がしますが、CMAKE変数になってしまえば上書き、追加、思うがままです。
次に登場するのが、言語を示す<LANG>と、DEBUG、RELEASEなどのコンフィギュレーションを示す<CONFIG>を持つ一群のCMAKE変数です。ドキュメントは以下に。
ここからも1行引用させていただきましょう。
The flags in this variable will be passed to the compiler after those in the CMAKE_<LANG>_FLAGS variable, but before flags added by the add_compile_options() or target_compile_options() commands.
上記の説明をみると、さきほどのCMAKE_C_FLAGSの適用後、次のadd_compile_options()の適用前にこの変数が適用されるようです。今回は、LANGの部分は C、CONFIGの部分は DEBUG と RELEASE の切り替え利用です。CONFIGは、DEBUGとRELEASE以外にも多数あるので、この素人はいまだ把握しきれてないです。少なくともVSCodeの下のステータスバーのコンフィグ指定で選択できるDEBUGとRELEASEには対応していることは確認しています。
その次に適用されるのが以下です。
これについても引用させていただきます。
These options are used when compiling targets from the current directory and below.
上記の説明からは、この定義を行ったディレクトリとその傘下に適用されるようなので、サブディレクトリを含めたりするときに細かく制御するためのものと想像されます。
もう一つ target_compile_options()というものもありますが、今回はテストしていません。その名前からは、実行ファイルを作るときとライブラリを作るときでオプション変えたい的な場面で使うものじゃないかと想像されます。ホントか?
さて「朧気」ではありますが、コンパイラオプションを置き方が分かってきたので、前回の CMakeLists.txt を以下のように改造してみました。
今回の CMakeLists.txt
cmake_minimum_required(VERSION 3.0.0)
project(cpthread
VERSION 0.1.0
LANGUAGES C)
set(CMAKE_C_FLAGS "-DdummyF0")
set(CMAKE_C_FLAGS_DEBUG "-DdummyDebug -Wall -O0 -g")
set(CMAKE_C_FLAGS_RELEASE "-DdummyRelease -Wall -O3")
add_compile_options(-DdummyA0)
include(CTest)
enable_testing()
add_executable(cpthread main.c)
target_link_libraries(cpthread
pthread
)
set(CPACK_PROJECT_NAME ${PROJECT_NAME})
set(CPACK_PROJECT_VERSION ${PROJECT_VERSION})
include(CPack)
実際に適用される様子を観察したかったので、ことさらに不要なマクロなどをオプションとしてちりばめてみました。ビルド時のコンパイラのコマンドラインはこんな感じとなりました。
Debugのとき /usr/bin/gcc-8 -DdummyF0 -DdummyDebug -Wall -O0 -g -DdummyA0 -o CMakeFiles/cpthread.dir/main.c.o -c /mnt/hdd1/piwork/cproj/cpthread000/main.c Releaseのとき /usr/bin/gcc-8 -DdummyF0 -DdummyRelease -Wall -O3 -DdummyA0 -o CMakeFiles/cpthread.dir/main.c.o -c /mnt/hdd1/piwork/cproj/cpthread000/main.c
ぶっちゃけ -O0と-O3を切り替えたかった(実際には何も書かないでもツールの方で切り替えてくれていた)だけですが、CMakeの勉強にはなった、と。
ビルドして実行の結果
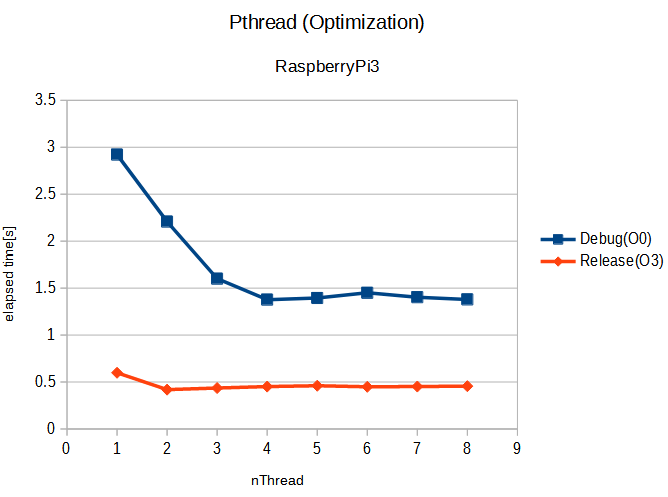
さて、ビルドして実行した結果のまとめを、アイキャッチ画像にグラフにしておきました。先週はスレッド数に反比例する感じ(ただしラズパイ3のコアは4個なので4スレッドまでは効果あり、それ以上は効果なし)で、プログラム全体の経過時間は短縮しました。今回、ちょっとプログラムを変更しました。紺色の「デバッグ」では前回と同じ傾向です。しかし、最適化オプションを加えたオレンジはまったく傾向が違います。全体として非最適化版より速いのは良いのですが、1スレッドより2スレッドが若干速くなっている以外、それ以降はスレッド数増やしても速度の向上はありません。こういうときによくあるのが、
テストプログラムがヘボくて、最適化したら「時間を使う筈の部分」が消えてなくなっていた
というケース。最近のコンパイラは頭が良いので、無駄な計算をしているループなどを見つけるとバッサリやってくれるからです。現在、まだこれを疑ってコードを確認中ですが、肝心のスレッド化されて実行されている部分については「消えて」はいなかったです。Armのアセンブラになってしまって、ちょっとローレベルですが、生成コードを引用するとこんな感じ。
最適化版の最内ループ
10f94: ecf37a01 vldmia r3!, {s15}
10f98: ecb27a01 vldmia r2!, {s14}
10f9c: e153000c cmp r3, ip
10fa0: ee677a87 vmul.f32 s15, s15, s14
10fa4: ece17a01 vstmia r1!, {s15}
10fa8: 1afffff9 bne 10f94 <testThreadFunc+0x84>
非最適化版の最内ループ
10d24: e59f30b0 ldr r3, [pc, #176] ; 10ddc <testThreadFunc+0x14c> 10d28: e5932000 ldr r2, [r3] 10d2c: e51b300c ldr r3, [fp, #-12] 10d30: e1a03103 lsl r3, r3, #2 10d34: e0823003 add r3, r2, r3 10d38: ed937a00 vldr s14, [r3] 10d3c: e59f309c ldr r3, [pc, #156] ; 10de0 <testThreadFunc+0x150> 10d40: e5932000 ldr r2, [r3] 10d44: e51b300c ldr r3, [fp, #-12] 10d48: e1a03103 lsl r3, r3, #2 10d4c: e0823003 add r3, r2, r3 10d50: edd37a00 vldr s15, [r3] 10d54: e59f3088 ldr r3, [pc, #136] ; 10de4 <testThreadFunc+0x154> 10d58: e5932000 ldr r2, [r3] 10d5c: e51b300c ldr r3, [fp, #-12] 10d60: e1a03103 lsl r3, r3, #2 10d64: e0823003 add r3, r2, r3 10d68: ee677a27 vmul.f32 s15, s14, s15 10d6c: edc37a00 vstr s15, [r3] 10d70: e51b3010 ldr r3, [fp, #-16] 10d74: e5933000 ldr r3, [r3] 10d78: e2832001 add r2, r3, #1 10d7c: e51b3010 ldr r3, [fp, #-16] 10d80: e5832000 str r2, [r3] 10d84: e51b300c ldr r3, [fp, #-12] 10d88: e2833001 add r3, r3, #1 10d8c: e50b300c str r3, [fp, #-12] 10d90: e51b200c ldr r2, [fp, #-12] 10d94: e51b301c ldr r3, [fp, #-28] ; 0xffffffe4 10d98: e1520003 cmp r2, r3 10d9c: baffffe0 blt 10d24 <testThreadFunc+0x94>
どちらも単精度の浮動小数乗算のために、vmul.f32命令を使っています。しかし、ループの作り方に段違いで差がありますな。最適化版はやっていることが目に見える感じでストレート、速そうです。
もしかすると何等かのハード的リソースの制約から、スレッドを増やしても、ある速度以上に浮動小数点の演算を高速化できないのかもしれません。最適化版のコードみると、メモリへのバスは1コアでもかなり占有しそうな雰囲気がありありとみてとれます(その上キャッシュが効かない1回読んで御仕舞のパターン。)4人でバスを奪い合っているのかも、分からんけど。
ま、測定するための下地はできた(ホントか?)感じがしないでもないので、ボチボチやっていきませう。今度こそ、他機種でやって比べてみるか?
ソフトな忘却力(7) clock()関数はCPUタイムを集計するのだ。経過時間じゃない。へ戻る
ソフトな忘却力(9) 最適化とthread数、RPi3とRPi4ではまた違うのだ へ進む
実験に使用したコード全文(gcc 8.3.0にて動作確認)
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <pthread.h>
#include <time.h>
#define MAX_THREAD (16)
#define NSET (2*3*2*5*7*2*3*11*13*2)
#define NDATAMAX (2048)
int idxStore[MAX_THREAD];
float *dataArray1;
float *dataArray2;
float *resultArray;
int nThread = 1;
int nData = 1;
int currentNT = 1;
int nLoop = 100;
int seed = 123;
void* testThreadFunc(void* p) {
int* ptr = (int*)p;
int blkSIZE = (NSET / currentNT) * nData;
int startIDX = (*ptr) * blkSIZE;
int endIDX = ((*ptr) + 1) * blkSIZE;
*ptr = 0; //counter
for (int j=0; j < nLoop; j++) {
for (int idx=startIDX; idx < endIDX; idx++) {
resultArray[idx] = dataArray1[idx] * dataArray2[idx];
*ptr += 1; //counter
}
}
}
int getParam(char* oa) {
int temp;
errno = 0;
temp = strtol(oa, (char **)NULL, 10);
if (errno == 0) {
return temp;
} else {
perror("ERROR: nThread");
exit(EXIT_FAILURE);
}
}
void setupArrays() {
int numberOfData = nThread * NSET * nData;
dataArray1= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate dataArray1");
exit(EXIT_FAILURE);
}
dataArray2= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate dataArray2");
exit(EXIT_FAILURE);
}
resultArray= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate resultArray");
exit(EXIT_FAILURE);
}
srand(seed); // Same seed will give same sequence.
for (int i=0; i < numberOfData; i++) {
dataArray1[i] = (float)rand() / 10000. + 0.5f;
dataArray2[i] = (float)rand() / 10000. + 0.7f;
}
}
void freeArrays() {
free(dataArray1);
free(dataArray2);
free(resultArray);
}
float getTimeFloat() {
struct timespec temp;
clock_gettime(CLOCK_MONOTONIC, &temp);
return ( (float)temp.tv_sec + (float)(temp.tv_nsec)/1e9 );
}
float testDriver(int nT) {
pthread_t threadA[MAX_THREAD];
float startT, endT;
int skipNUM = nT;
currentNT = nT;
startT = getTimeFloat();
for (int numT=0; numT < nT; numT++) {
idxStore[numT] = numT;
if (pthread_create(&threadA[numT], NULL, testThreadFunc, (void*)&idxStore[numT])) {
perror("ERROR: pthread_create\n");
skipNUM = numT;
}
}
for (int numT=0; numT < skipNUM; numT++) {
if (pthread_join(threadA[numT], NULL)) {
perror("ERROR: pthread_join\n");
}
}
endT = getTimeFloat();
int totNUM = 0;
for (int numT=0; numT < nT; numT++) {
totNUM += idxStore[numT];
}
printf(",%d",totNUM);
return endT - startT;
}
int main(int argc, char *argv[]) {
int opt;
int nSleep = 2;
int flagA = 0;
int nTrial = 3;
float result;
while((opt = getopt(argc, argv, "aT:N:R:L:S:")) != -1) {
switch (opt) {
case 'a':
flagA = 1;
break;
case 'T':
nThread = getParam(optarg);
if (nThread > MAX_THREAD) {
perror("ERROR: Too much thread.");
exit(EXIT_FAILURE);
}
break;
case 'N':
nData = getParam(optarg);
if (nData > NDATAMAX) {
perror("ERROR: Data, over the limit.");
exit(EXIT_FAILURE);
}
break;
case 'R':
nTrial = getParam(optarg);
break;
case 'L':
nLoop = getParam(optarg);
break;
case 'S':
seed = getParam(optarg);
break;
default:
fprintf(stderr, "Usage: %s [-a][-T nThread][-N nData][-R nTrial][-L nLoop][-S seed]\n", argv[0]);
exit(EXIT_FAILURE);
}
}
printf("Cpthread test runner: nThread=%d nData=%d, nTrial=%d, nLoop=%d\n", nThread, nData, nTrial, nLoop);
setupArrays();
printf("Start TEST\n");
for (int nT=1; nT <= nThread; nT++) {
printf("%d", nT);
for (int idx=0; idx < nTrial; idx++) {
result = testDriver(nT);
printf(",%12.6e",result);
}
printf("\n");
}
printf("End of TEST.\n");
sleep(nSleep);
if (flagA) {
for (int i=0; i< nData; i++) {
printf("%d: %f\n",i, resultArray[i]);
}
}
freeArrays();
printf("Eno of Execution.\n");
exit(EXIT_SUCCESS);
}