時間計測のとき、プロセッサ固有の性能カウンタばかり使用しておったのです。今回はCレベルの関数で「汎用」にやろうとして失敗しました。なれないことはするもんじゃないです。とりあえず pthread の効用を測定する雛形は作成。ラズパイ3上では、それらしいグラフを描けました。他のマシンや pthread以外への展開はまた次回かな。
※ソフトな忘却力 投稿順 index はこちら
(今回実験に使ったソース全文は末尾に)
プロセッサ固有の性能カウンタは、CPUクロック数や命令数といった生の値をほぼほぼ正確に取得できるので重宝しているのであります。しかし、それぞれにクセが強いうえに、中には特権を要求するデバイスもあり、あれこれ載せ替え考えるときにはメンドイです。
その点、言語レベルもしくはOSレベルのライブラリ関数であると、「可搬性」というやつ、高くなると思います。今回、「仕事を細かく分けると速くなるかもしれない」グラフをラズパイ各機種、そして先週復活のJetson Nanoなど複数のマシンでいろいろ走らせて測定しようと思い立ちました。勿論、ここまでの流れを継続し、VS Code + CMake Tool での開発であります。
-
- とりあえず、C++ではなく、Cレベルとする
- 大した時間精度は不要
というゆるゆるな設定です。そこで時間測定は、確か標準Cのライブラリ?のclock()関数を使用すれば良いよね、とか浅はかにコーディングしてハマリました。状況はこんな感じです。
スレッド1個、2個、3個、4個と増やしても測定結果として出力される時間がほとんど変わらない。それどころかスレッド数が多い方が微妙に長い。
そのくせ、ストップウオッチで測ってみるとスレッドを増やせば処理時間が明らかに短くなっています。なぜ?
以下のJMプロジェクト様のclock()関数のMan pageをちゃんと読んでいれば、ハマることは無かったです。
上記Man page(日本語)の「注意」から1文引用させていただきましょう。
glibc 2.18 以降では、 精度を向上させるため、 clock_gettime(2) (のCLOCK_PROCESS_CPUTIME_ID クロック) を使って実装されている。
そして CLOCK_PROCESS_CPUTIME_ID の説明を読んでみれば、以下のようでした。もう一文を Man page of CLOCK_GETRES から引用させていただきます。
プロセス単位の CPU タイムクロック (そのプロセスの全スレッドで消費される CPU 時間を計測する)。
ほえほえ~ clock()関数が返してくるのは「全スレッド」が消費するCPU時間なのね、全体の処理時間が短くなっても多くのスレッドが並列に動作しているので、結局積算CPU時間は変化なし(それどころかスレッドの生成、消滅にかかる時間分微妙に伸びる。)これに気づくまでに大分時間を費やしました。トホホ。
結局、Man page of CLOCK_GETRESにある clock_gettime()関数使うことにいたしました。
作成した雛形
今回作成の雛形は、以下のような意図です。
-
- 同じ計算量を異なる数のスレッドで処理し、その処理の経過時間を測る
- ターゲットの計算は単精度浮動小数の掛け算を仮置きするが、後で演算、データ型ともいろいろやってみたい。
- 同じ雛形を別なマシンに展開し、測定したい
- 今回は pthead だが、他の並列化方法 (Jetson Nanoならば CUDA 、ラズパイ4ならSIMDとか)とも比べてみたいので、簡単に変更できるようにしたい。
最大のスレッド数、計算負荷のパラメータ等をコマンドライン引数として与える形式のプログラムとしました。走らせるとスレッド数を1から最大まで変化させながら、それぞれで複数回の試行を行い、時間を計測した結果を画面に表示します。実行例が以下です。
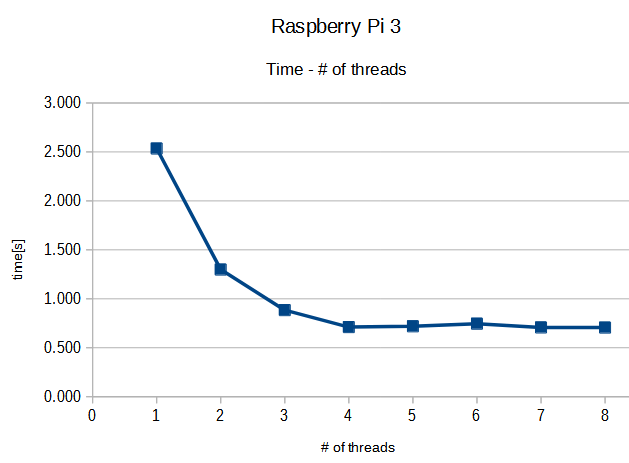
$ cpthread -T 8 Cpthread test runner: nThread=8 nData=1, nTrial=3, nLoop=100 Start TEST 1,2.525391e+00,2.546875e+00,2.531250e+00 2,1.304688e+00,1.277344e+00,1.312500e+00 3,8.730469e-01,8.886719e-01,8.906250e-01 4,6.953125e-01,7.460938e-01,6.914062e-01 5,7.128906e-01,7.402344e-01,7.031250e-01 6,7.421875e-01,7.207031e-01,7.734375e-01 7,7.011719e-01,7.050781e-01,7.148438e-01 8,7.031250e-01,7.109375e-01,7.031250e-01 End of TEST. Eno of Execution.
出力された、処理部分の経過時間の平均値をとってグラフにしたものを先頭のアイキャッチ画像に掲げました。スレッド数4までは速度向上がみられますが、それ以降は頭打ちとなりました。実験に使ったラズパイ3は4コアの装置なので予想どおりの結果であります。
一応、実験中に top コマンドで観察していたところ、実験経過とともにスレッドの数が増えているのを確認できました。またCPUタイムでは99%超えていたので他に邪魔されている部分はおおよそ無視できるかと思います。
Linux上のプログラム書くには、やっぱCの関数とかも復習しないとダメですな。clock()とか、malloc()とか「ベアメタル」なマイコンボードじゃ使わないものねえ。忘却。
ソフトな忘却力(6) 今回はハード?Jetson Nano復活のACアダプタ へ戻る
ソフトな忘却力(8) CMake、最適化オプションの置き場所。thread化の蹉跌? へ進む
実験に使用したソース全文
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <pthread.h>
#include <time.h>
#define MAX_THREAD (16)
#define NSET (2*3*2*5*7*2*3*11*13*2)
#define NDATAMAX (2048)
int idxStore[MAX_THREAD];
float *dataArray1;
float *dataArray2;
float *resultArray;
int nThread = 1;
int nData = 1;
int currentNT = 1;
int nLoop = 100;
void* testThreadFunc(void* p) {
int* ptr = (int*)p;
int blkSIZE = (NSET / currentNT) * nData;
int startIDX = (*ptr) * blkSIZE;
int endIDX = ((*ptr) + 1) * blkSIZE;
for (int j=0; j < nLoop; j++) {
for (int idx=startIDX; idx < endIDX; idx++) {
resultArray[idx] = dataArray1[idx] * dataArray2[idx];
}
}
}
int getParam(char* oa) {
int temp;
errno = 0;
temp = strtol(oa, (char **)NULL, 10);
if (errno == 0) {
return temp;
} else {
perror("ERROR: nThread");
exit(EXIT_FAILURE);
}
}
void setupArrays() {
int numberOfData = nThread * NSET * nData;
dataArray1= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate dataArray1");
exit(EXIT_FAILURE);
}
dataArray2= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate dataArray2");
exit(EXIT_FAILURE);
}
resultArray= (float*)malloc(numberOfData * sizeof(float));
if (dataArray1 == NULL) {
perror("ERROR: Allocate resultArray");
exit(EXIT_FAILURE);
}
for (int i=0; i < numberOfData; i++) {
dataArray1[i] = (float)i / 10000 + 0.5f;
dataArray2[i] = (float)i / 10000 + 0.7f;
}
}
void freeArrays() {
free(dataArray1);
free(dataArray2);
free(resultArray);
}
float getTimeFloat() {
struct timespec temp;
clock_gettime(CLOCK_MONOTONIC, &temp);
return ( (float)temp.tv_sec + (float)(temp.tv_nsec)/1e9 );
}
float testDriver(int nT) {
pthread_t threadA[MAX_THREAD];
float startT, endT;
int skipNUM = nT;
currentNT = nT;
startT = getTimeFloat();
for (int numT=0; numT < nT; numT++) {
idxStore[numT] = numT;
if (pthread_create(&threadA[numT], NULL, testThreadFunc, (void*)&idxStore[numT])) {
perror("ERROR: pthread_create\n");
skipNUM = numT;
}
}
for (int numT=0; numT < skipNUM; numT++) {
if (pthread_join(threadA[numT], NULL)) {
perror("ERROR: pthread_join\n");
}
}
endT = getTimeFloat();
return endT - startT;
}
int main(int argc, char *argv[]) {
int opt;
int nSleep = 2;
int flagA = 0;
int nTrial = 3;
float result;
while((opt = getopt(argc, argv, "aT:N:R:L:")) != -1) {
switch (opt) {
case 'a':
flagA = 1;
break;
case 'T':
nThread = getParam(optarg);
if (nThread > MAX_THREAD) {
perror("ERROR: Too much thread.");
exit(EXIT_FAILURE);
}
break;
case 'N':
nData = getParam(optarg);
if (nData > NDATAMAX) {
perror("ERROR: Data, over the limit.");
exit(EXIT_FAILURE);
}
break;
case 'R':
nTrial = getParam(optarg);
break;
case 'L':
nLoop = getParam(optarg);
break;
default:
fprintf(stderr, "Usage: %s [-a][-T nThread][-N nData][-R nTrial][-L nLoop]\n", argv[0]);
exit(EXIT_FAILURE);
}
}
printf("Cpthread test runner: nThread=%d nData=%d, nTrial=%d, nLoop=%d\n", nThread, nData, nTrial, nLoop);
setupArrays();
printf("Start TEST\n");
for (int nT=1; nT <= nThread; nT++) {
printf("%d", nT);
for (int idx=0; idx < nTrial; idx++) {
result = testDriver(nT);
printf(",%12.6e",result);
}
printf("\n");
}
printf("End of TEST.\n");
sleep(nSleep);
if (flagA) {
for (int i=0; i< nData; i++) {
printf("%d: %f\n",i, resultArray[i]);
}
}
freeArrays();
printf("Eno of Execution.\n");
exit(EXIT_SUCCESS);
}
使用したCMakeLists.txt
cmake_minimum_required(VERSION 3.0.0)
project(cpthread
VERSION 0.1.0
LANGUAGES C)
include(CTest)
enable_testing()
add_executable(cpthread main.c)
target_link_libraries(cpthread
pthread
)
set(CPACK_PROJECT_NAME ${PROJECT_NAME})
set(CPACK_PROJECT_VERSION ${PROJECT_VERSION})
include(CPack)