テキトーに書いても走る(走ったように見える)言語もあれば、走る前に阻止される言語もあります。どうもRustは後者であるようです。Rustでの文字列のとり扱いを始めましたが、Cの文字列に慣れた頭でいると、いろいろ転換せねばなりませぬ。文字列を配列とみて添え字でアクセスするような方法は禁止じゃと。
※「やっつけな日常」投稿順 indexはこちら
文字列に関する解説として、いつもお世話になっております「The Rust Programming Language 日本語版」の以下のページを拝読させていただいとります。
ここでかいつまめば
-
- 文字 char型 というのはUTF-8エンコードされた文字である
- 文字列 Stringは、「入れ物」としてはバイトのベクタ Vec<u8> である
- 上記の入れ物のスライス &[u8] が、&str 型である
さらに言えばUnicodeスカラー値( char型)と最終的な文字とは異なる場合があるのだと。その例として上記ではヒンディー語のダイアクリティカルマークが挙げられております。メンドクセーです。ASCIIコードの7ビットエンコード、単なるバイト列でバイトポインタでも配列添え字でも取り扱えたのとは段違い。
Rustに入ればRustに従えとて、Rustのやり方を学びたいと思います。さすれば、日本語対応どころか、Unicodeにのったあらゆる言語を処理できる(筈)と。
今回は易しいところから
String型変数の初期化
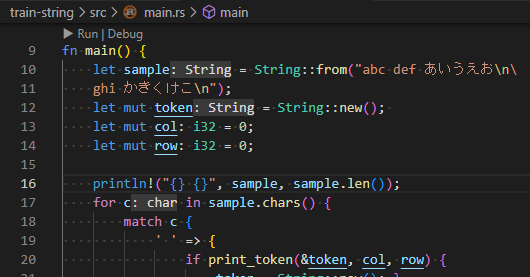
実体配列?を生成するString型の変数の宣言方法にもいくつかある中で、ちょいと気になったのが、複数行にまたがるような文字列のソース上での表記法です。実体がVec<u8>ということは改行コードが含まれていようともString型変数内に保持できるのは明らかです。問題はその手のリテラルのソース上での表記法です。調べてみると
-
- 文字列リテラルを複数行に分けて書く場合、行末にバックスラッシュを置けば「継続行」的に扱ってくれる
- その記述をソースを段付けしている中に置いた場合、「段付け」は無かったことにしてくれているみたい。
以下の例でいくと、文字列変数 sample の2行目、ghiで始まる行はその頭に段付けのため4文字のスペースおいているのですが、後の処理をみるとその4文字は見えませぬ。
String型の中の「文字」を舐める
String型を単なるバイト配列に変換すれば、昔の(失礼、今も現役)C同様にバイト単位で舐めることも可能ではありますが、折角のUTF-8対応でなくなってしまいます。文字単位で舐めるためには、chars()関数でchar型として舐める方法が一番ストレートに思われました。以下例では for 文で string型からとりだした char型を舐めてます。
文字の識別
とりだした文字は、Rust特有の match文で文字毎に異なる処理に分岐させてみました。matchは、Cのcase文に比べると遥かに強力なようですが、今回は、Cのcase文と変わりませぬ。イチイチ break しなくて良いだけでもお楽。
実験用のソース
今回実験したRustのソースが以下に。
fn print_token(token: &String, col: i32, row: i32) -> bool {
if ! token.is_empty() {
println!("({},{}) = {}", row+1, col, token);
return true;
}
return false;
}
fn main() {
let sample = String::from("abc def あいうえお\n\
ghi かきくけこ\n");
let mut token = String::new();
let mut col: i32 = 0;
let mut row: i32 = 0;
for c in sample.chars() {
match c {
' ' => {
if print_token(&token, col, row) {
token = String::new(); }
col += 1;
},
'\n' => {
if print_token(&token, col, row) {
token = String::new(); }
col = 0;
row += 1;
},
_ => {
token.push(c);
col += 1;
},
}
}
}
実行結果の確認
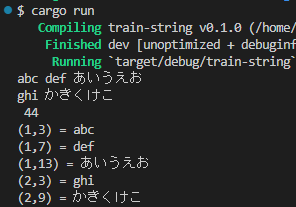
上記を実行すると以下のようでした。
-
- ソース上、複数行にまたがる文字列リテラルは意図通りに処理されている
- 文字列リテラルに潜ませた改行文字も効いているみたい
- アルファベットは勿論、日本語ひらがなの処理も問題なし
まだ全然慣れないデス。数こなさないと。