前回は整数の掛け算命令について表にまとめたところで終わってました。今回は3つある演算パターンのうち、すべてのレジスタのビット幅が等しい第1のパターンを練習してみます。「普通のMUL命令」もこの分類です。でも基本は積和演算MADDです。MULはMADDのエイリアスという扱い、実際にはMADDだと。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
MADD命令とMSUB命令
今回実機上で動かしてみる命令を赤枠で囲いました。MADD、MSUBそしてMADDのエイリアスであるMULと、MSUBのエイリアスであるMNEGです。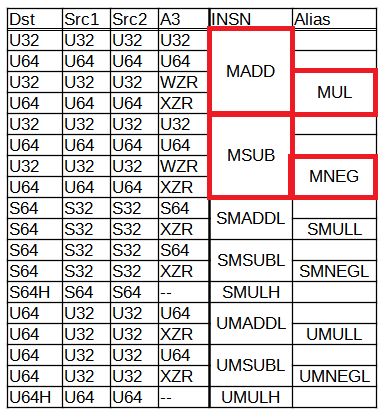
MADDを一行で書けば、以下のようです。
Dst = A3 + Src1 * Src2
MSUBは以下。
Dst = A3 – Src1 * Src2
結局、Src1とSrc2を掛け算するのは一緒ですが、A3に足すのか引くのかの違い。上記にてA3をゼロレジスタと指定すればMULとMNEGとなります。
MUL: Dst=(ZERO)+ Src1 * Src2
MNEG: Dst=(ZERO)- Src1 * Src2
ここで重要なのは、Dst, A3, Src1, Src2がすべて同じビット幅のレジスタであることです。W(32ビット)か、X(64ビット)のどちらか。このパターンの命令群ではWとXが混ざるケースはありません(別パターンではあります。)
実験用のアセンブリ言語ソース
以下は実験用のアセンブリ言語関数のソースです。手抜き(関数プロローグもエピローグもない)な、ほぼ1命令1関数スタイルです。今回は、
-
- madd命令は、第1オペランドのデスティネーションと第4オペランド(加算対象)を同じレジスタとした(いわゆる積和算のスタイル)
- msub命令もmadd命令と同じスタイル。
- mul命令とmneg命令は、最初にmadd、msubとしてコーディングした後、直後にmul、mnegで同じコードになるようにコーディングした。これはディスアセンブルして同じコードであることを確認するため。
としています。
.globl maddW, maddX, mulW, mulX, msubW, msubX, mnegW, mnegX
.text
.balign 4
maddW:
madd w0, w1, w2, w0
ret
maddX:
madd x0, x1, x2, x0
ret
mulW:
madd w0, w1, w2, wzr
mul w0, w1, w2
ret
mulX:
madd x0, x1, x2, xzr
mul x0, x1, x2
ret
msubW:
msub w0, w1, w2, w0
ret
msubX:
msub x0, x1, x2, x0
ret
mnegW:
msub w0, w1, w2, wzr
mneg w0, w1, w2
ret
mnegX:
msub x0, x1, x2, xzr
mneg x0, x1, x2
ret
上記のmul命令のコーディングでは、以下のように書かれている部分が
mulW: madd w0, w1, w2, wzr mul w0, w1, w2 ret mulX: madd x0, x1, x2, xzr mul x0, x1, x2 ret
ディズアセンブルすると以下のように同一命令の繰り返し(エイリアス優先)になっていることがわかります。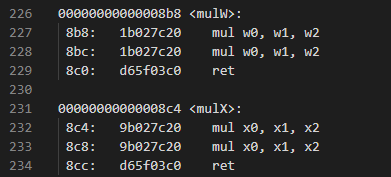
またmneg命令のコーディングでは、以下のように書かれている部分が
mnegW: msub w0, w1, w2, wzr mneg w0, w1, w2 ret mnegX: msub x0, x1, x2, xzr mneg x0, x1, x2 ret
やはりエイリアス命令の繰り返しになっています。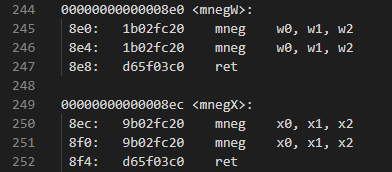
実験に使用したC言語ソース
上記のアセンブリ言語関数を呼び出すテスト用のCソースが以下に。
#include <stdio.h>
#include <stdint.h>
extern uint32_t maddW(uint32_t, uint32_t, uint32_t);
extern uint64_t maddX(uint64_t, uint64_t, uint64_t);
extern uint32_t mulW(uint32_t, uint32_t, uint32_t);
extern uint64_t mulX(uint64_t, uint64_t, uint64_t);
extern uint32_t msubW(uint32_t, uint32_t, uint32_t);
extern uint64_t msubX(uint64_t, uint64_t, uint64_t);
extern int32_t mnegW(uint32_t, uint32_t, uint32_t);
extern int64_t mnegX(uint64_t, uint64_t, uint64_t);
int main(void)
{
uint32_t uresult;
uint64_t uresultX;
int32_t result;
int64_t resultX;
uresult = maddW(0x10000000, 0x7000000, 16);
printf ("maddW(0x10000000, 0x7000000, 16): %08x\n", uresult);
uresultX = maddX(0x100000000, 0x70000000, 16);
printf ("maddX(0x100000000, 0x70000000, 16): %16lx\n", uresultX);
uresult = mulW(0x10000000, 0x7000000, 16);
printf ("mulW(0x10000000, 0x7000000, 16): %08x\n", uresult);
uresultX = mulX(0x100000000, 0x70000000, 16);
printf ("mulX(0x100000000, 0x70000000, 16): %16lx\n", uresultX);
uresult = msubW(0xF0000000, 0x7000000, 16);
printf ("msubW(0xF0000000, 0x7000000, 16): %08x\n", uresult);
uresultX = msubX(0xF00000000, 0x70000000, 16);
printf ("msubX(0xF00000000, 0x70000000, 16): %16lx\n", uresultX);
result = mnegW(0xF0000000, 1, 1);
printf ("mnegW(0xF0000000, 1, 1): %d\n", result);
resultX = mnegX(0xF00000000, 1, 1);
printf ("mnegX(0xF00000000, 1, 1): %ld\n", resultX);
return 0;
}
基本はuintで値を与えましたが、mnegだけは符合反転していることを見やすくしたかったので戻り値を int としています。
ビルドと実行
ビルドのコマンドラインが以下に。なお、実験は Raspberry Pi 4 model B(Arm Cortex-A72)、OSはRaspberry Pi OS 64bit (bullseye)、gcc 10.2.1で行ってます。
gcc -g -O0 mul.c mul.s
実行したところが以下に。
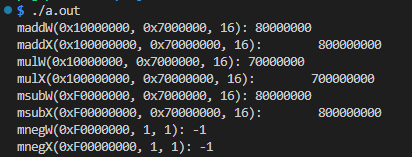
予定通りの動きをしているみたいです。