前回は自前ノード data-check に「流れの中で」平均や分散、標準偏差を求めるためのWelford算法を導入。今回は「流れをぶった切って」再初期化するときに、そこまで到来したデータの層別(ランク付け)結果を送出する機能を追加してみたいと思います。「ブロックを」といいつつズルズルJavaScriptが長くなってる。
※「ブロックを積みながら」投稿順 index はこちら
※動作確認にはRaspberry Pi 3 model B+のRaspberry Pi OS(32bit)上にインストールした以下を使用しています。
-
- Node-RED v2.0.5
- node-red-dashboard 3.2.0
自前ノードのJavaScript機能拡張
いつもお世話になっております Node-RED User Group Japan様 の以下の日本語ページを参照させていただき、ソースへの機能追加をしております。
JavaScript素人です。上記を読み進めるうちに、いろいろ「手を入れたい」記述に気づいてきているのですが、「発展途上のコード」に途中で手を入れるとわけわからなくなるだろ~ということで、「心に秘めた機能」をとりあえず一通り実装するまではそのままで行きたいと思います。
今回追加するのはデータを層別して、各層(rank)毎にデータ点数を集計する機能です。簡易的なヒストグラムを作れるようなデータを出力できるようにしたいというこってす。
-
- 既にある上限、下限の監視値を流用する
- 上限、下限の間を4等分して層別集計する
- 上の4層に加えて、下限より下、上限以上の2層を追加して合計6層とする
- 平均、分散を初期化するためのRESET時に、層別データも初期化(ゼロ)する
- RESET時に、RESET直前までの層別集計結果をmsgパケットに載せて報告する。
- なお、層別に使う基準値(上限、下限含む5点)はRESET時に計算してセットする。途中で上限、下限の設定を変更してもRESETしなければ集計には反映されない。
以上の機能追加です。ソースコード的には、自前ノードの本体であるDataCheckNode()関数がズルズルと長くなっているので、上記の追加機能は外側の補助関数に追い出す方針であります。
追加したソースが以下に。
module.exports = function(RED) {
function makeRank(ul, dl, rank) {
rank[0] = dl;
rank[1] = dl + (ul - dl) * 1.0 / 4.0;
rank[2] = dl + (ul - dl) * 2.0 / 4.0;
rank[3] = dl + (ul - dl) * 3.0 / 4.0;
rank[4] = ul;
}
function clearArray(nElem, ary) {
for (let i=0; i < nElem; i++) {
ary[i] = 0;
}
}
function voteArray(dat, rank, dataArray) {
let flag = true;
for (let i=0; i < rank.length; i++) {
if (rank[i] > dat) {
dataArray[i] += 1;
flag = false;
break;
}
}
if (flag) {
dataArray[rank.length] += 1;
}
}
function DataCheckNode(config) {
RED.nodes.createNode(this, config);
var node = this;
this.name = config.name;
this.ulimit = config.ulimit;
this.dlimit = config.dlimit;
node.on('input', function(msg) {
var nodeContext = this.context();
var nData = nodeContext.get('nData')||0;
var minData = nodeContext.get('minData')||Number.MAX_VALUE;
var maxData = nodeContext.get('maxData')||-Number.MAX_VALUE;
var meanOld = nodeContext.get('meanOld')||0;
var rankA = nodeContext.get('rankA', rankA)|| [0.0, 0.0, 0.0, 0.0, 0.0];
var rankD = nodeContext.get('rankD', rankD)|| [0, 0, 0, 0, 0, 0];
var m2Old = nodeContext.get('m2Old')||0;
var inputData = parseFloat(msg.payload);
var ulim = Number(this.ulimit);
var dlim = Number(this.dlimit);
if (!isNaN(inputData)) {
nData++;
var meanNew = meanOld + (inputData - meanOld)/nData
var m2New = m2Old + (inputData - meanOld)*(inputData - meanNew)
if (inputData > maxData) {
maxData = inputData;
nodeContext.set('maxData', maxData);
}
if (inputData < minData) {
minData = inputData;
nodeContext.set('minData', minData);
}
msg.NDATA = nData;
msg.DATAMAX = maxData;
msg.DATAMIN = minData;
msg.MEAN = meanNew;
msg.M2 = m2New;
msg.NAME = this.name;
nodeContext.set('nData', nData);
nodeContext.set('meanOld', meanNew);
nodeContext.set('m2Old', m2New);
if (!isNaN(ulim) && (inputData > ulim)) {
msg.topic = "Higher than the ulimit";
}
if (!isNaN(dlim) && (inputData < dlim)) {
msg.topic = "Lower then the dlimit";
}
voteArray(inputData, rankA, rankD);
} else {
nodeContext.set('maxData',-Number.MAX_VALUE);
nodeContext.set('minData', Number.MAX_VALUE);
nodeContext.set('nData', 0);
nodeContext.set('meanOld', 0);
nodeContext.set('m2Old', 0);
msg.rankarray = rankA.join(",");
msg.rankdata = rankD.join(",");
makeRank(ulim, dlim, rankA);
clearArray(rankA.length+1, rankD);
nodeContext.set('rankA', rankA);
nodeContext.set('rankD', rankD);
}
node.send(msg);
});
}
RED.nodes.registerType("data-check", DataCheckNode);
}
上記の data-check.jsのみの修正にて、data-check.html、package.jsonへの変更はありません。
実機実行確認
npm updateして、node-red-restart は必要ですが、既存ノードの「見た目」にはまったく影響しない変更なので、フローや設定は前回そのまま、まったく変更ありません。
まずは、RESETとかかれたInjectノードで”RESET”した後のデバッグウインドウが以下に。rankarrayとrankdataというプロパティが載っているのが分かりますか?rankarrayの方が層毎の閾値の設定値で、rankdataの方が集計値です。初回は設定も集計もないので、0が並んでいます。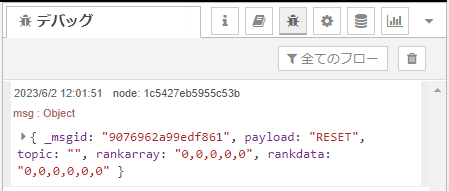
つづいて、前回使用した Trigger to read とかかれたInjectノードでサンプルデータファイルのデータを読み出し処理させていみます。既知の25点のデータが送り込まれます。
25点目のデータと、その後のRESET時のデバッグウインドウの様子が以下に。上が25点目のデータ時で最大、最小以外に平均および分散、標準偏差を計算するもとになるM2値が乗ってます。M2値をNDATAなり、NDATA-1なりで割れば分散なり不偏分散なり求まります。RESETパケットの方には層別集計に使ったrank値と集計結果が載ってます。
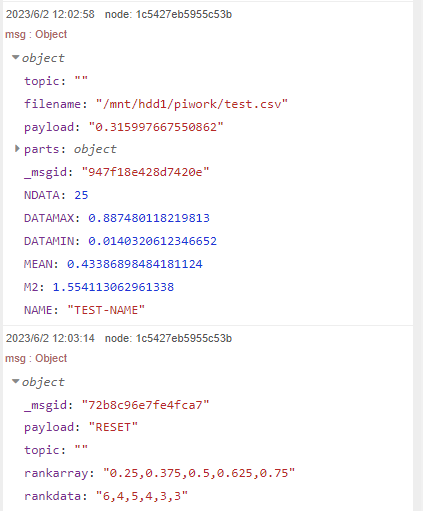
集計結果は表計算で数えた期待値と一致。まあ、動いているようです。しかし、全然、「ブロック」してないな。JavaScriptのお勉強?