前回からA64のベクトル(SIMD)演算命令に入ってます。今回は、はやくも「核心」的なSIMDの積和算を練習してみます。なんでSIMD使うのかと問われれば半分くらいは積和したいから、ということになるんじゃないかと思うからです。SIMD積和算にも浮動小数、整数の両方あるのですが今回は単精度浮動小数のみ。手抜き。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
FMLA(vector)、浮動小数の積和算
第1オペランドをアキュムレータ、第2,第3オペランドを乗算ソースとして第2と第3を掛けた結果を第1と加算し、第1に書き戻すという操作です。1命令の中に2演算含まれる形で、演算は fused です。fusedについてはこちら。
マニュアル的には以下の3種のオペランド幅を取り得るのですが、Armv8p0では例によって半精度がありません。残りのうち単精度のみ練習してお茶を濁してます。手抜き。
-
- 半精度浮動小数
- 単精度浮動小数
- 倍精度浮動小数
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの、関数プロローグ、エピローグ無の被テスト関数です。その動作を図にしたものが以下に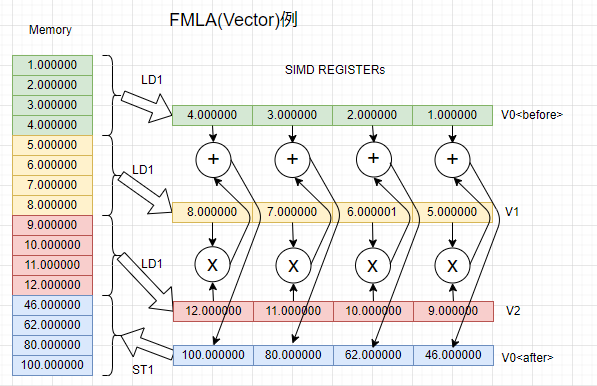
ほとんど前回ソースのパクリでないの。。。
.globl fmlav
.text
.balign 4
fmlav:
ld1 {v0.4S}, [x0], #16
ld1 {v1.4S}, [x0], #16
ld1 {v2.4S}, [x0], #16
fmla v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。FMLAをやる前のメモリ初期値をダンプ、アキュムレータ初期値とソース2つをベクトルロード後、FMUL呼び出し、アキュムレータに残った結果をメモリにストアして再びダンプというお手軽コードです。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (16)
float TargetMEM[MAXMEM];
extern void fmlav(float *);
void initTGT(float c) {
for (int i=0; i < MAXMEM; i++) {
TargetMEM[i] = c * (i+1);
}
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < MAXMEM; i++) {
printf("%d: %f\n", i, TargetMEM[i]);
}
}
int main(void) {
initTGT(1.000f);
dumpTGT("Before FMLAv");
fmlav(TargetMEM);
dumpTGT("After FMLAv");
return 0;
}
実験結果
以下のようにしてビルドして実行しています。
$ gcc -g -O0 fmlav.c fmlav.s $ ./a.out
標準出力に現れたBefore、Afterを横並びにして見やすくしたものが以下に。
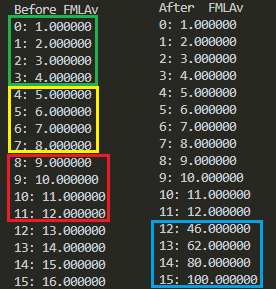
単精度浮動小数といいつつ、整数部分しか使ってないじゃないの。目で検算するのがメンドかったのよ。