前回はチラリと代数学が出てきてビビリました。今回はビビらないで済む普通の算術っす。整数の足し算ね。でもSIMDあるあるデス。整数の足し算といっても一筋縄ではいかんのですな(勿論フツーの足し算もあるけれども。)今回は加算後に1ビット右シフトを伴う(値をだいたい半分にするということだね)一族を練習してみます。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
有限ビット幅のくびき
通常、計算機の中の数値表現は有限なビット幅によって制限されとります。皆「見て見ぬふり」で受け入れている?そんなことはありませんな。「桁があふれる」ときなど、どうしたらよいのか考えぬくのがプロってもんです。知らんけど。
さて、いつもフツーにやっている足し算ですが、8ビット幅の整数と8ビット幅の整数を加えた場合、結果に9ビット幅とれれば桁があふれることはありませぬ。しかし、9ビット幅など半端。なんとか折り合いをつけたいデス。そこで考え方が2つ。
-
- Saturating、ある範囲を超えた結果は上限もしくは下限に張り付ける
- Halving、結果の上位ビットだけ保存して最下位ビットをなんとかする
「1」は信号処理などでよくやる手ですな。上限超えたらどんな数でも上限にしてしまう。どうせ振り切れているのだし。
「2」は下の方のコマケー話はおいておいて、だいたいの値(当然桁シフトしていることは織り込まないとマズイけど)は追尾できるっと。
計算する相手の算法次第でお好みデス。今回は「2」の方のために用意されておる命令をちょいと練習してみます。
SHADD、SRADD、UHADD、URHADD
まず申し上げたいのは加算があれば減算もある、です。でもメンドイので今回は(今回も)加算だけです。加算だけでも4種あるんであります。すべてに共通する「H」の文字は加算後右1ビットシフト(2で割ることと等価、Halving)を行うことを意味してます。
-
- SHADD、符合付整数加算、シフトされる最下位切り捨て
- SRHADD、符合付整数加算、シフトされる最下位丸め
- UHADD、符合無整数加算、シフトされる最下位切り捨て
- URHADD、符合無整数加算、シフトされる最下位丸め
これらのSIMD(ベクタ)命令がとることのできる要素のビット幅は当然各種あるのですが、例によってメンドイのでバイト(8ビット)幅のみとしてます。また、SIMDレジスタの幅も128ビットか64ビットか選択可能ですが、狭い64ビット幅の場合のみ練習してみます。
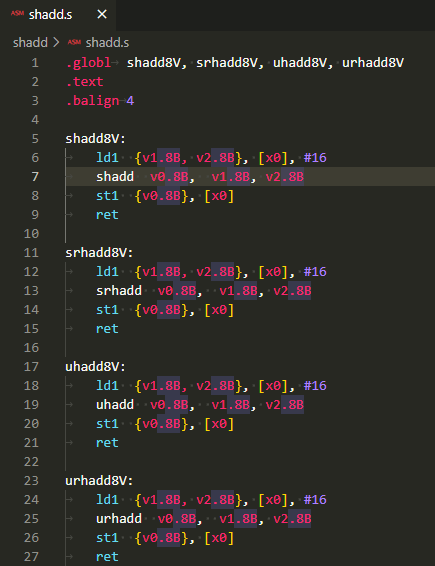
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。
.globl shadd8V, srhadd8V, uhadd8V, urhadd8V
.text
.balign 4
shadd8V:
ld1 {v1.8B, v2.8B}, [x0], #16
shadd v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
srhadd8V:
ld1 {v1.8B, v2.8B}, [x0], #16
srhadd v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
uhadd8V:
ld1 {v1.8B, v2.8B}, [x0], #16
uhadd v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
urhadd8V:
ld1 {v1.8B, v2.8B}, [x0], #16
urhadd v0.8B, v1.8B, v2.8B
st1 {v0.8B}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。これまたいつもの通りの手抜きですが、各エレメントの計算が分かり易いように要素毎に出力を1行にまとめてみました。また本来 shadd, srhaddは符合付なのですが、C言語レベルでは全てuint8_t引数に対して操作させてます(どうせアセンブラには関係ねえっす。)
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (24)
uint8_t TargetMEM[MAXMEM];
extern void shadd8V(uint8_t *);
extern void srhadd8V(uint8_t *);
extern void uhadd8V(uint8_t *);
extern void urhadd8V(uint8_t *);
void initTGT() {
TargetMEM[0] =0x01;
TargetMEM[1] =0x01;
TargetMEM[2] =0x01;
TargetMEM[3] =0x01;
TargetMEM[4] =0x81;
TargetMEM[5] =0x81;
TargetMEM[6] =0x81;
TargetMEM[7] =0x81;
TargetMEM[8] =0x02;
TargetMEM[9] =0x03;
TargetMEM[10]=0x82;
TargetMEM[11]=0x83;
TargetMEM[12]=0x02;
TargetMEM[13]=0x03;
TargetMEM[14]=0x82;
TargetMEM[15]=0x83;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 8; i++) {
printf("%02d: 0x%02x + 0x%02x -> 0x%02x \n", i, TargetMEM[i], TargetMEM[i+8], TargetMEM[i+16]);
}
}
int main(void) {
initTGT();
shadd8V(TargetMEM);
dumpTGT("shadd");
srhadd8V(TargetMEM);
dumpTGT("srhadd");
uhadd8V(TargetMEM);
dumpTGT("uhadd");
urhadd8V(TargetMEM);
dumpTGT("urhadd");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 shadd.c shadd.s $ ./a.out
標準出力に「ダラダラ」現れた結果が以下に。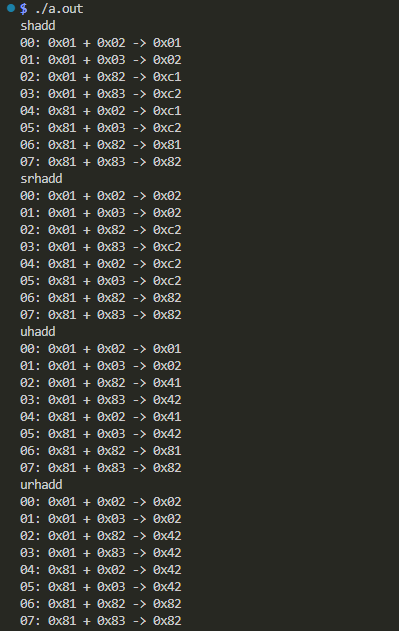
4命令すべてに同じ値を食わせているのに、頭がsかuかで最上位ビット(符合ビット)の様子が異なり、rが付くか付かないかで最下位ビット(その下を切り捨てるか、丸めるかで変化する)の様子が異なるのが見て取れるかと思います。
順番から言ったら次回はサチュレーション演算だな。これまたメンドイ。