前回につづき「SIMDレジスタの一方の全要素に他方の一要素を共通に掛け算」する浮動小数点演算命令を練習しようとして発覚。FMLAL, FMLAL2, FMLSL, FMLSL2の4命令、ARMv8.2以降の実装です。ARMv8.0では練習できません。ラッキー?残りはと見ればFMULXのみ。しかしメンドクセー奴なんだ。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
FMULX
FMULXのXは eXtend のXらしいです、マニュアルから何がXなんだか、FMULとの違いを引けば以下の如し(以下引用)
If one value is zero and the other value is infinite, the result is 2.0. In this case, the result is negative if only one of the values is negative, otherwise the result is positive.
数値演算素人の老人など、infinite(無限大)が出現したら計算はそこで打ち止め、ショウガナイ、ノージンジャー。しかし、世には無限が出現した後も計算を続けたい方々がおられると思われます。しかしなんで結果が2.0なのかな~。そこには数学の深淵が横たわっておる?知らんけど。
ともあれ、FMULとFMULXに同じオペランドを与えて結果を眺めることは出来るのでやってみることにいたしました。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。念のため、FPCRとFPSRにアクセスするための関数も用意いたしましたが、使いませなんだ。メンドイし。
.globl fmul4V, fmulx4V, readfpcr, readfpsr, writefpcr
.text
.balign 4
fmul4V:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
fmul v0.4S, v1.4S, v2.4S[1]
st1 {v0.4S}, [x0]
ret
fmulx4V:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
fmulx v0.4S, v1.4S, v2.4S[1]
st1 {v0.4S}, [x0]
ret
readfpcr:
mrs x0, fpcr
ret
readfpsr:
mrs x0, fpsr
ret
writefpcr:
msr fpcr, x0
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。今回の命令をテストするのに「無限大」をあらわす値を与えねばなりませぬ。一応、手動でもチマチマ与えられるようにターゲットメモリはいつもの union としましたが、当然 gcc にはそういう手立てが用意されとります。御本家 gnu様のマクロの解説ページが以下に。
上記を使えば、float型のプラス無限大 INFINITYと、マイナス無限大 -INFINITYが使えます。ヘッダファイルは math.h ね。
#include <stdio.h>
#include <stdint.h>
#include <math.h>
typedef union {
float s;
uint32_t u;
} dut;
extern void fmul4V(dut *);
extern void fmulx4V(dut *);
extern uint32_t readfpcr(void);
extern uint32_t readfpsr(void);
extern void writefpcr(uint32_t);
#define MAXMEM (12)
dut TargetMEM[MAXMEM];
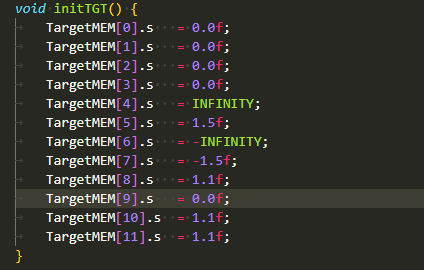
void initTGT() {
TargetMEM[0].s = 0.0f;
TargetMEM[1].s = 0.0f;
TargetMEM[2].s = 0.0f;
TargetMEM[3].s = 0.0f;
TargetMEM[4].s = INFINITY;
TargetMEM[5].s = 1.5f;
TargetMEM[6].s = -INFINITY;
TargetMEM[7].s = -1.5f;
TargetMEM[8].s = 1.1f;
TargetMEM[9].s = 0.0f;
TargetMEM[10].s = 1.1f;
TargetMEM[11].s = 1.1f;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 4; i++) {
printf("%02d: %2.8f opr %2.8f -> %2.8f(%08x)\n", i, TargetMEM[i+4].s, TargetMEM[9].s, TargetMEM[i].s, TargetMEM[i].u);
}
}
int main(void) {
initTGT();
fmul4V(TargetMEM);
dumpTGT("fmul v0.4S, v1.4S, v2.4S[1]");
initTGT();
fmulx4V(TargetMEM);
dumpTGT("fmulx v0.4S, v1.4S, v2.4S[1]");
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdFMULX.c simdFMULX.s $ ./a.out
実機上での実行結果が以下に。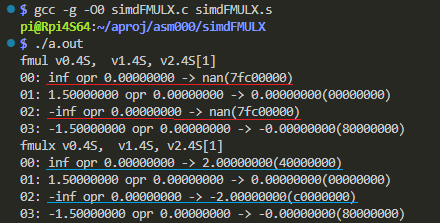
上の赤線引いた方がFMUL命令の結果です。プラス無限大だろうが、マイナス無限大だろうが、ゼロをかけたら NaNが飛び出してきます。そうだろうよ。
一方下の青線引いた方がFMULX命令の結果です。プラス無限大にゼロかけたら2.0、マイナス無限大にゼロかけたら-2.0 が返ってきます。ムズカしい数学のことは分からんよ。。。