前回はVivadoに「バンドル」されているIPからRAM-Based Shift Registerを練習。LUTを使ってFIFOみたいな構造を作れるIPでした。今回はAccmulatorです。入ってくる値をどんどん積算して結果を出力してくれるもの。なんか計算用のブロックを使って作ってくれるのか?どうなんだ?
※かえらざるMOS回路 投稿順 INDEX
※実習にはWindows11上の AMD社 (Xilinx) Vivado 2023.2 を使用させていただいております。
※ターゲットボードは、Digilent製 Cmod S7ボードです。お求めやすい?Spartan-7搭載の超小型開発ボードです。
Accmulator
「どうなんだ?」ということでIPの設定画面を見たらば、一番上に「スイッチ」がありました。こんな感じ。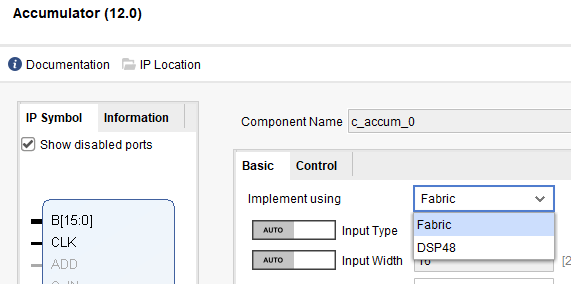
Implement usingのところで「DSP48」を選択すると、演算に特化したDSPスライスを使って演算器を作ってくれるみたいです。しかし今回は8ビット幅のチンマリしたアキュムレータ一つ、特にスピードがとかいうこともないのでFabricを選択いたしました。ま、DSP48は後のお楽しみ。
さて、IP配置のメニューでCTRL+Qで見られる、「アキュムレータ」IPの簡単な説明が以下です。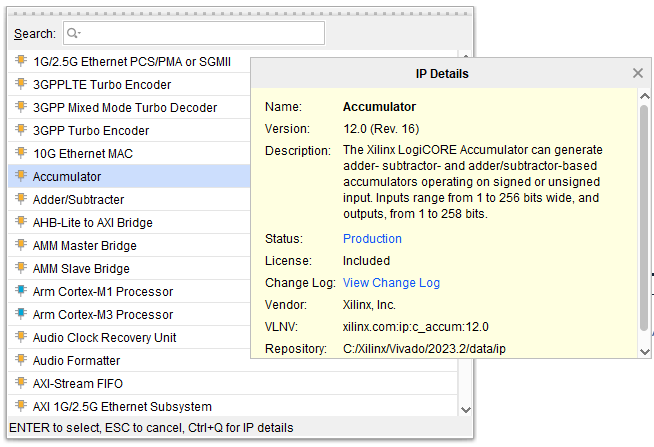
さて今回の構成は以下のとおり。符号無8ビット、加算のみというチンマリした設定であります。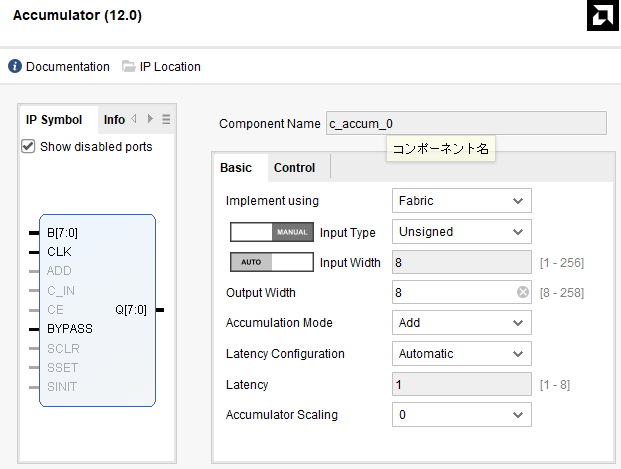
ブロックダイアグラム
前回、8ビット幅のシフトレジスタを練習したときのブロック図の先に上記のアキュムレータを「とってつけ」ました。こんな感じ。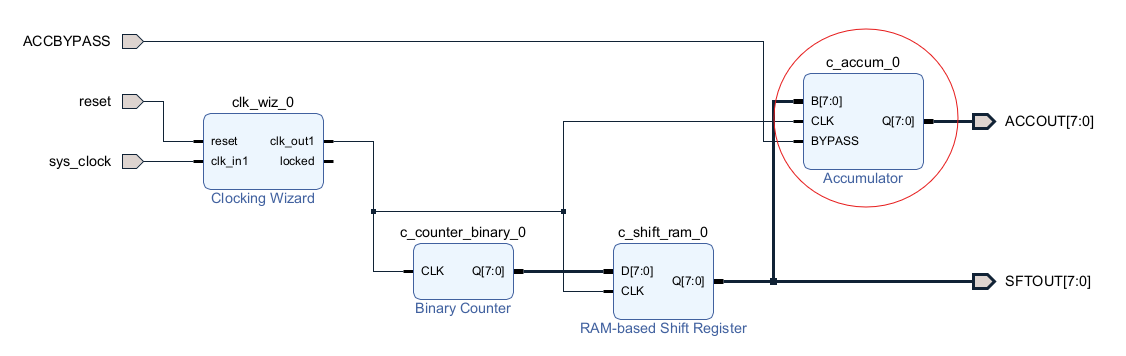
お願いすればCLKは自動配線してくれますが、それ以外の端子は自動配線してくれるわけでないので、
-
- シフトレジスタ(8ビット幅)の出力をアキュムレータの入力(B)へ接続
- 新たなポートACCOUT[7:0]を作りアキュムレータ出力に接続
- 新たなポートACCBYPASSを作りアキュムレータのBYPASS入力に接続
してます。
シミュレーション準備
ブロックダイアグラムを修正してしまったので、HDL Wrapperを作り直し(ボタンを押すだけですが)、シミュレーション用のVerilogソースをチョイ変します。チョイ変後のソースはこんな感じ。
module sft_1_tb(
);
reg clk;
reg rst;
reg acc_bypass;
wire [7:0] sft_out;
wire [7:0] acc_out;
sft_1_wrapper dut (
.ACCBYPASS(acc_bypass),
.ACCOUT(acc_out),
.SFTOUT(sft_out),
.reset(rst),
.sys_clock(clk)
);
always #50 clk = ~clk;
initial begin
clk = 0; rst = 1; acc_bypass = 1;
#200; rst = 0;
#54000; acc_bypass = 0;
#200000; $finish;
end
endmodule
「ビヘイビア」レベルのシミュレーション
結果が以下に。なお以下のclkを「2分周」したクロックでシフトレジスタもアキュムレータも動いてます。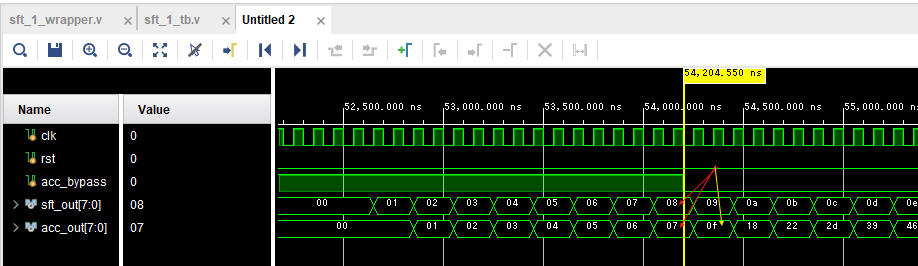
黄色の縦カーソルのところで、アキュムレータへのBYPASS信号がインアクティブになってます。BYPASS信号がアクティブの間はsft_outに乗ってくる値をそのまま(1クロック遅れで)出力しているacc_outです。しかし黄色の線のところからはsft_outとacc_outの値を加算して、次のacc_outとしています。赤矢印が足し合わされる値、黄色矢印がその結果です。アキュムレートしてますな。
今回は符号無8ビット幅です。「溢れる」ところが以下に。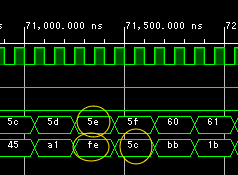
0x5eと0xfeを加えると結果は0x15cの筈ですが、8ビット幅なので0x5cにラップしてます。勿論アキュムレータのセッティングでキャリーアウトなどを設けることもできるようになってますが、今回は使ってません。
これで積和算の「和」のところは作れるようになった。ホントか?