今回のデータは米国の(半世紀くらい前の)金融機関らしい組織の事務職員のアンケート調査みたいなものの集計らしいです。R言語の処理としては線形回帰の練習データです。淡々と処理はできるんじゃないかと思いますが、人事情報的な「意見」の集約なので「その意味」がとても気になります。データとしてはすべて%で表される数値なのですが。
※「データのお砂場」投稿順Indexはこちら
R言語所蔵のサンプルデータセットをABC順(大文字先)で端から眺めております。今回のデータセットにはattitude、直訳すると「態度」でいいんですかね。データセットの解説ページが以下に。
The Chatterjee-Price Attitude Data
7変数、30行のデータセットです。
-
- 行の方は、ランダムに選んだ部署を表している
- 列(変数)は、各部署約35名の従業員に対する質問の集計結果(%)
であると。30部署x35名=1050名なので、それなりの規模のある組織のようです。列(変数)の方の説明を読んで行くと「分かる」項目もあり、私には「よく分からない」項目もあります。分かり易いのは以下ですかね。
-
- raises これは昇給ってことでいいですかね。
- advance こちらは昇進でしょうか。
- learning これは学習機会みたいな感じですか。
昔(このデータよりはちょっと下る1980年代っすけど)僅かな期間米国企業の中にいたときに、ちょっと驚いたのは以下です。
-
- 給料は週給
- 昇進、昇給は自分で上司のところへ行って交渉
当時だって日本は月給でしたし、定期昇給とかベアとかがあった世界(最近は会社によって大分違うケド。)米国人がこの数字を見ればフムフムと理解できるのかもしれません。しかし私には、ここに書かれている「そこの部署の人の平均のパーセンテージ」がどういう理解をしたらよいかはイマイチ想像がつかず。またよく分からない項目もあり。
-
- complaints 従業員の人が垂れた「文句」に対する処置?
- privileges 権限移譲が足りないの?
- critical 責任が重すぎるの?
なんだかな~
そして上記の「説明変数」の数々を総合した rating という「目的変数」はそこの部署の「満足度」みたいな理解でよろしいの?よく分かりません。
なお、例によってRの処理方法については同志社大の先生が書かれている以下のページも参照させていただきました。
まずは生データから
なんだか分からないデータですが、処理はできます。まずは生データをロードして内容を覗いてみました。データ構造はフツーのデータ・フレームです。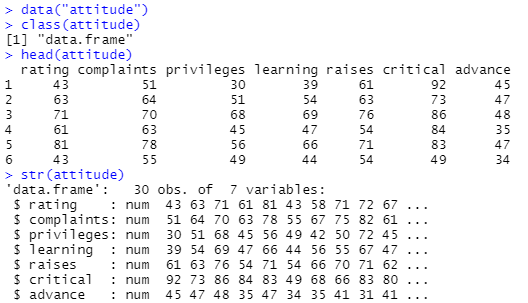
一応、summary()も。すべてパーセンテージの数値であります。
昇給項目の回答の平均は64.63%に対して、昇進項目の回答は42.93%なので、昇給に満足している人は多いけど、昇進にはちょっと不満ってこと?どう理解したらいいのかな。そんなこと気にせずに統計処理しろ、と。
さて生データを眺めていても傾向は分からないので、plot()関数にデータを丸ごと渡してみます。
plot(attitude)
結果のグラフが以下に。
上記をみると明らかに rating と complaints の間には「線形な関係」がありそうなのだけれど、あとは微妙。
処理例
今回のデータセットの解説ページには処理例があります。例にそって線形回帰してみました。まずは、目的変数 raging とそれ以外の全てを説明変数とした場合(以下例では “.”と書いてありますが、こう書くと rating以外の変数全ての意味となるみたいです。)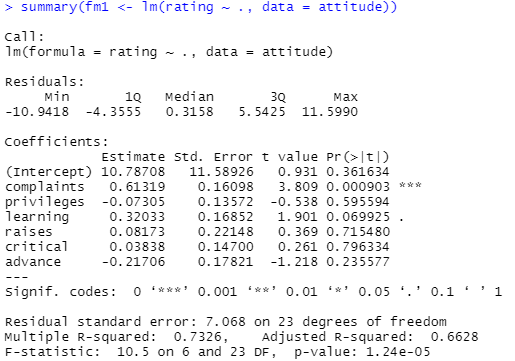
上記の結果の Pr 欄をみると、complaints のみが有意水準1%でも下回ります。complaintsとratingには関係が無いという「帰無仮説」を棄却できる、ってこと?それで良いのか。raises とか critical などはPr値デカイので、とても棄却できるような話ではないでしょ。
また、決定係数 (Multiple R-Squared) と調整済み決定係数 (Adjusted R-squared)
は1に近づくほどフィットがよいらしいです。知らんけど。
検証のため上記の結果をグラフにするには以下で。
結果は以下のグラフ。
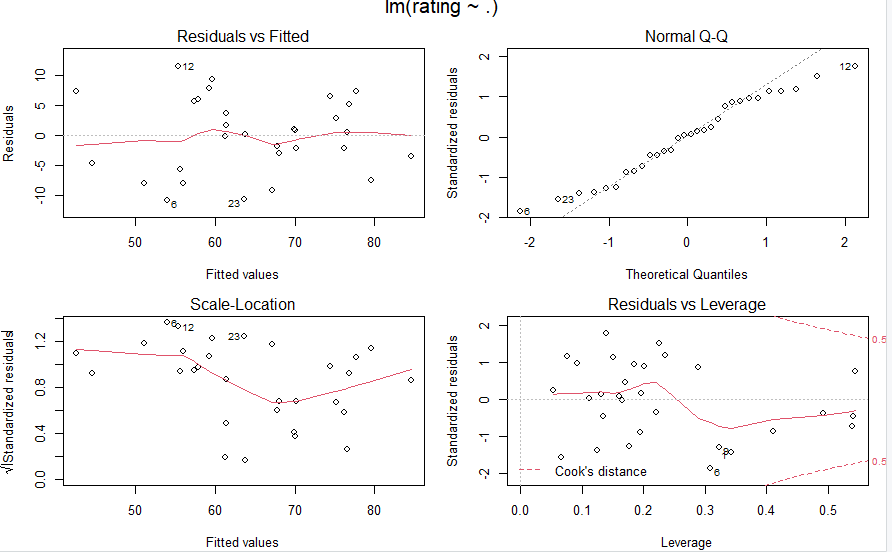
上記は左上から右下に向かって
-
- Residuals(残差) vs Fitted(予測値)のグラフ
- 残差正規Q-Qプロット。正規分布に従うなら直線上に並ぶ(回帰分析は、残差が標準正規分布に従う仮定で行っている)
- 残差平方根プロット 1のグラフは素の残差だけれどこちらは正規化?
- Cookの距離プロット Cook の距離が大きいデータは異常値である可能性がある。0.5という赤点線があるけれども、その外側にあるとヤバイ?
まあ、線形な回帰をするにあたっては、ratingとcomplaintsの間に絞った方が良さそうなので、その処理が以下に。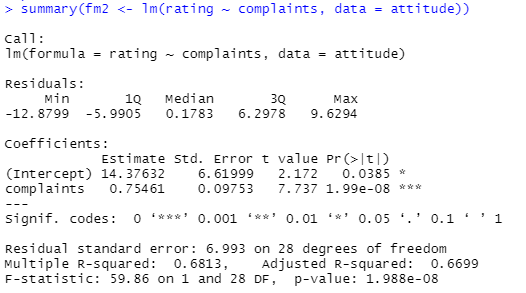
グラフ化の手順が以下に。
結果グラフが以下に。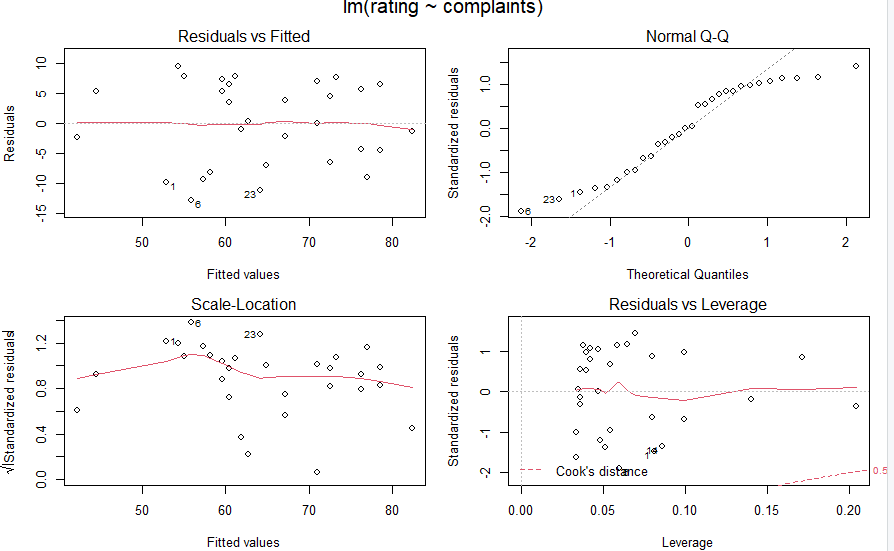
グラフは描けたけれども、私はcomplaintsってやつの中身が知りたい。結局、昇給や昇進よりもこれだと。それは何?