前回A64のベクトルロード命令をあらかた終えたつもり。今回からA64のベクトル(SIMD)演算命令に入ってまいりたいと思います。その初回はFSUBです。3オペランドの「典型的」演算かつ、ソースの順序に依存する命令ということでの「起用」であります。でも以前にもFSUBというニーモニック自体は使ってるんでないかい?
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
FSUB (vector)
FSUBは浮動小数点数の減算命令です。以前にやったFSUBは、スカラー相手のFSUBでした。一方今回はベクトル相手です。ただし、浮動小数レジスタの実体はSIMDレジスタの一部でもあるのでレジスタの実体は重なってます。スカラー扱いするかベクトル扱いするかは、「どちらのお名前」をオペランドにしてFSUBするかという1点によります。
A64の場合、浮動小数には
-
- 半精度
- 単精度
- 倍精度
の3種あるのです。残念ながらARMv8p0機には半精度なく、それに例によっていろいろやるのがメンドイので、今回も単精度浮動小数のみ実習の手抜きであります。
なお、SIMDレジスタの幅については64ビット幅でのオペレーションも可能なのですが、フル幅128ビット幅での操作のみとしています。
今回実験例の図が以下に。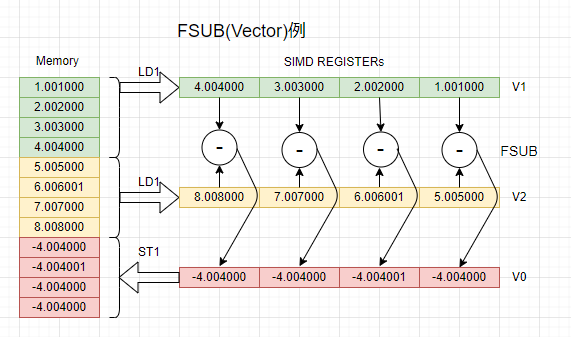
単精度浮動小数(32ビット幅)を格納してあるv1レジスタからv2レジスタの内容を4個同時に引き算して結果をv0レジスタに格納する操作です。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの、関数プロローグ、エピローグ無の被テスト関数です。ソースレジスタv1とv2にはLD1命令を使ってそれぞれ値をメモリからロード、ベクトル引き算をFSUBで行って結果のv0レジスタをST1命令でメモリにストアしています。
.globl fsubv
.text
.balign 4
fsubv:
ld1 {v1.4S}, [x0], #16
ld1 {v2.4S}, [x0], #16
fsub v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。FSUBをやる前のメモリ初期値をダンプ、ソースベクトル2つをロードしてFSUBやって、結果ベクトルをメモリにストア後再びダンプというお手軽コードです。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (12)
float TargetMEM[MAXMEM];
extern void fsubv(float *);
void initTGT(float c) {
for (int i=0; i < MAXMEM; i++) {
TargetMEM[i] = c * (i+1);
}
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < MAXMEM; i++) {
printf("%d: %f\n", i, TargetMEM[i]);
}
}
int main(void) {
initTGT(1.001f);
dumpTGT("Before FSUBv");
fsubv(TargetMEM);
dumpTGT("After FSUBv");
return 0;
}
実験結果
以下のようにしてビルドして実行しています。
$ gcc -g -O0 fsubv.c fsubv.s $ ./a.out
標準出力に現れたBefore、Afterを横並びにして見やすくしたものが以下に。なお、黄色の枠内がSIMDレジスタv1(ソース1)にロードされる値、赤枠内がv2(ソース2)、そしてAfterの緑枠がFSUB命令のデスティネーションであるv0をストアした値です。
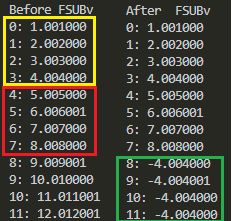
予定通りの結果ね。