前回は勝手命名SIMD抽出系、SIMDの整数要素のビット幅が狭くなる命令群でした。今回はFCVTL一族です。SIMDの浮動小数要素に作用し、浮動小数フォーマットを広く、あるいは狭くするものどもです。ARMv8p0の場合、単精度と倍精度の間の変換だけなのでお気楽。でもコマケーこだわりの命令もあるよ。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
SIMD浮動小数のフォーマット変換
A64の場合、倍精度、単精度、半精度の浮動小数が使える、といっても半精度はARMv8p2以降なので実験に使用しているCortex-A72では半精度はできませぬ。そこで変換は倍精度と単精度の間でだけ、ということになります。命令を列挙すれば以下の通り。
-
- FCVTL, FCVTL2 Floating-point convert to higher precision long
- FCVTN, FCVTN2 Floating-point convert to lower precision narrow
- FCVTXN, FCVTXN2 Floating-point convert to lower precision narrow, rounding to odd
今回は単精度から倍精度のビット幅が広くなる方向に使えるFCVTL、FCVTL2と、倍精度から単精度にビット幅が狭くなる方向に使えるFCVTN、FCVTN2が中心となります。最後のFCVTXN, FCVTXN2は何よというとその動作をパッと見してもFCVTNとFCVTN2となかなか見分けがつかない?結果が得られる命令です。違いは丸めモードのみなのでケースによってはLSBのみ違うこともあります。微妙なやつ。FCVTL、FCVTL2、FCVTN、FCVTN2はFPCRレジスタで決められる丸めモード(遥か昔の回でやったな~)に従って動作するのですが、ひとり(ふたり)FCVTXNとFCVTXN2は the Round to Odd rounding mode というオッドな丸めモードで我が道を行きます。浮動小数業界の絶対的権威 IEEE754規格にないモードだそうです。なぜArmの中の人がそれが必要だと思ったかはマニュアルを良く読んでくだされ。浮動小数素人の老人はコメントを「差し控えさせて」いただきます。こういうところも命令多過ぎA64。こだわりか?
なお例によってニーモニック末尾の「2」は、FCVTL2の場合はソース要素をSIMDレジスタのMSB側から拾ってくる意味、FCVTN2、FCVTXN2の場合はデスティネーションをSIMDレジスタのMSB側に置く意味になります。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。例によってソース要素とデスティネーション要素のビット幅が変わるために、SIMDレジスタの64/128ビットの選択とあいまって要素指定がねじれ気味?な記述になります。
.globl fcvtl2V, fcvtl2_2V, fcvtn2V, fcvtn2_2V, fcvtxn2V, fcvtxn2_2V
.text
.balign 4
fcvtl2V:
ld1 {v0.4S, v1.4S}, [x0]
fcvtl v0.2D, v1.2S
st1 {v0.2D}, [x0]
ret
fcvtl2_2V:
ld1 {v0.4S, v1.4S}, [x0]
fcvtl2 v0.2D, v1.4S
st1 {v0.2D}, [x0]
ret
fcvtn2V:
ld1 {v0.4S, v1.4S}, [x0]
fcvtn v0.2S, v1.2D
st1 {v0.2D}, [x0]
ret
fcvtn2_2V:
ld1 {v0.4S, v1.4S}, [x0]
fcvtn2 v0.4S, v1.2D
st1 {v0.2D}, [x0]
ret
fcvtxn2V:
ld1 {v0.4S, v1.4S}, [x0]
fcvtxn v0.2S, v1.2D
st1 {v0.2D}, [x0]
ret
fcvtxn2_2V:
ld1 {v0.4S, v1.4S}, [x0]
fcvtxn2 v0.4S, v1.2D
st1 {v0.2D}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。今回は浮動小数の間の変換なのですが、FCVTXNの場合結果の要素のLSBを見ないと差が分からないので符号無整数型でも読めるように union で出し入れしてます。メンドクセーです。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (4)
typedef union {
double d;
uint64_t u64;
float s[2];
uint32_t u32[2];
} un64;
un64 TargetMEM[MAXMEM];
extern void fcvtl2V(un64 *);
extern void fcvtl2_2V(un64 *);
extern void fcvtn2V(un64 *);
extern void fcvtn2_2V(un64 *);
extern void fcvtxn2V(un64 *);
extern void fcvtxn2_2V(un64 *);
void initTGT() {
TargetMEM[0].d = 0.0;
TargetMEM[1].d = 0.0;
TargetMEM[2].s[0] = 1.23f;
TargetMEM[2].s[1] = 2.45f;
TargetMEM[3].s[0] = 3.33f;
TargetMEM[3].s[1] = 4.99f;
}
void initTGT2() {
TargetMEM[0].s[0] = 0.00f;
TargetMEM[0].s[1] = 0.00f;
TargetMEM[1].s[0] = 0.00f;
TargetMEM[1].s[1] = 0.00f;
TargetMEM[2].d = 1.23456789012;
TargetMEM[3].d = 3.14159265359;
}
void dumpTGT(const char *arg, int pos) {
printf("%s\n", arg);
printf("%02d: %f -(%s)-> %e \n", 0, TargetMEM[pos].s[0], arg, TargetMEM[0].d);
printf("%02d: %f -(%s)-> %e \n", 1, TargetMEM[pos].s[1], arg, TargetMEM[1].d);
}
void dumpTGT2(const char *arg, int pos) {
printf("%s\n", arg);
printf("%02d: %e -(%s)-> %f(0x%08x) \n", 0, TargetMEM[2].d, arg, TargetMEM[pos].s[0], TargetMEM[pos].u32[0]);
printf("%02d: %e -(%s)-> %f(0x%08x) \n", 1, TargetMEM[3].d, arg, TargetMEM[pos].s[1], TargetMEM[pos].u32[1]);
}
int main(void) {
initTGT();
fcvtl2V(TargetMEM);
dumpTGT("fcvtl", 2);
initTGT();
fcvtl2_2V(TargetMEM);
dumpTGT("fcvtl2", 3);
initTGT2();
fcvtn2V(TargetMEM);
dumpTGT2("fcvtn", 0);
initTGT2();
fcvtn2_2V(TargetMEM);
dumpTGT2("fcvtn2", 1);
initTGT2();
fcvtxn2V(TargetMEM);
dumpTGT2("fcvtxn", 0);
initTGT2();
fcvtxn2_2V(TargetMEM);
dumpTGT2("fcvtxn2", 1);
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdFCVTL.c simdFCVTL.s $ ./a.out
以下は標準出力に「ダラダラ」現れた結果です。まあ、思ったとおりに変換できてら、という感じです。fcvtnとfcvtxnの「微妙な差」の部分に赤と青のお印をつけておきましたので、御吟味くださいまし。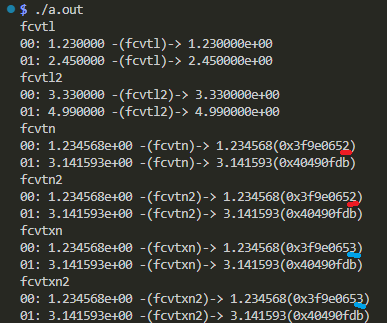
印をつけたところのLSBの1ビットが算術演算の成否を左右すると。知らんけど。