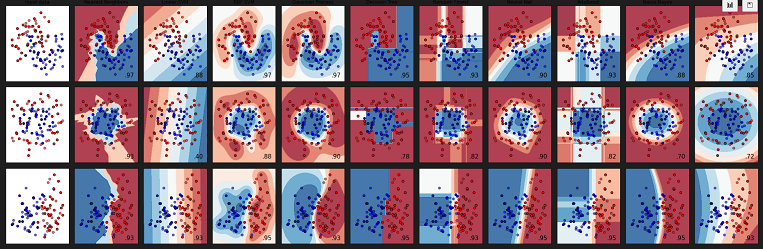
冒頭に掲げましたClassifier comparison例題の図、多くの分類器の結果が比較できるようにならんでいて壮観。印象深いものがあります。しかし「分類してるんでしょ」ということは分かるんですが、細かいことはサッパリ。まあ実際に動かして、ソースコードを読んで、説明ページも読むと。読んだら分かるようになりますかね?
※「MLのお砂場」投稿順 index はこちら
まず Scikit-Learnの例題ページへのリンクが以下です。
上記から、PythonのソースまたはJupyter-notebook形式(.ipynb)のファイルをダウンロードすることができます。こちらでは .ipynb 形式ファイルをダウンロードして、VScodeで開きました。勿論、Pythonの実行環境、Jupyter-notebook用のプラグインなどはインストール済です。VScodeの環境では、Python環境が複数あれば勝手に探し出し、venv等も処理してくれるので楽です。
ダウンロードしたファイルをVScode内で実行したところが以下に
だいたい、グラフの見方が分からない
実行すれば、ほとんど時間を置かず3行11列の小グラフから構成される出力プロットが得られます。以下のような疑問があります。
-
- 小プロットの行は何を意味しているの?
- 小プロットの列は何なの?
- プロットの中に色違いの丸があるけれど何なの?
- プロットの中の等高線みたいのは何?
- 小プロットの右下にある数字は何?
こんなとこですかね。これらを順次調べていきたいと思います。なお、VScode内にデフォルトで表示されているプロット群、老眼の目には苦しい大きさなので、別途拡大プロットで拝見することにいたしました。そのため大きなプロットを3分割。
一番左の3行4列部分
以下に大きなプロットの左端部分を切り取りました。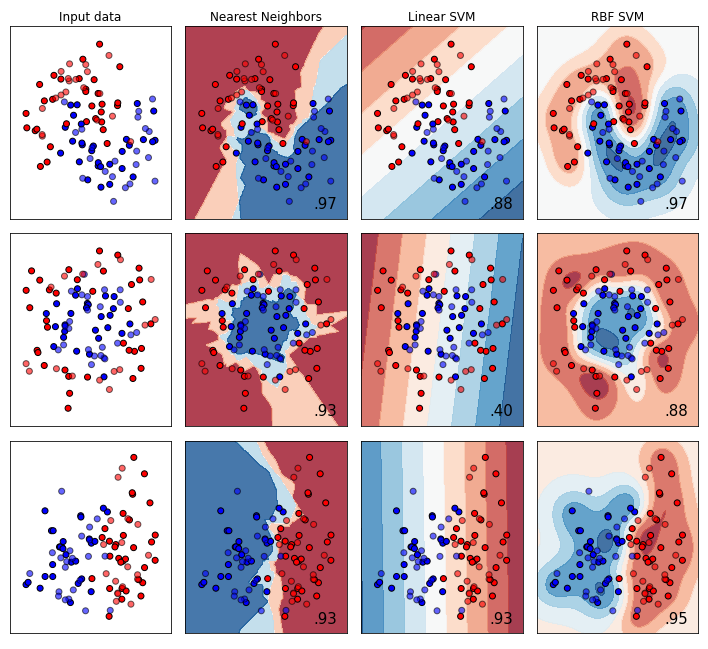
最左端の1列は入力データでした。しかし、入力に使っているデータセットは何なんでしょうか。そこに置かれていたデータは「生成された」データセットでした。データセットの生成については以下に説明があります。
ことなる3種類の方法で生成したサンプル用のデータセットであったわけです。3種類のデータセットをプログラムの中で生成しています。その3種類が各行に対応していて、この列に生データが表示されておるというわけです。3種類の内訳というか生成関数を上から列挙すると以下のようでした。
-
- make_moons
- make_circles
- make_classification
いずれも2次元の点(X)に対して、2値の分類(y)が当てはまるようなテストデータを生成してます。1からは渦巻き状?のもの。2からは同心円上のもの、3からは1直線で分類できそうなものが生成されているようです。なお、揺らぎというか、ノイズというかも重ね合わされており、特に3などは上記の関数で生成したものを2次加工しているような感じでした。
ここで大事なのが、赤の点と青の点があるけれど、濃い色と薄い色の2種類あるってことです。拡大してみてようやく気付きました。
-
- 識別器のトレーニングに使った点が濃い色(単色)
- テストに使った点が薄い色(半透明、alpha=0.6)
ということです。この生成されたデータをトレーニング用とテスト用のセットに分割する作業は、以下の関数が担っています。
今後ともお世話になるんですかね?知らんけど。
この3行のデータセットに対して、列方向に異なるClassifierを適用し、その結果を並べていくわけです。上記プロットに含まれる最初の3識別器は
-
- Nearest Neighbors
- Linear SVM
- RBF SVM
です。1は、k-nearest neighbors vote、日本語で言えばk最近傍法ということで良いのかな、です。前回はクラスタリングですが「似た方法」でした。2と3は同じSupport Vector machinesの関数使っているのですが、kenelが違うんだそうです。2はlinear kernel、3はRBF kernelです。
各小プロットの右下隅には、各識別器.score() で呼び出されている「テストデータのアキュラシーを求める関数」の値が記されています。たとえば2のLinear SVMは、線形に識別してくれるみたいなので、真ん中の行の同心円状のデータにはダメダメな結果になっているみたい。
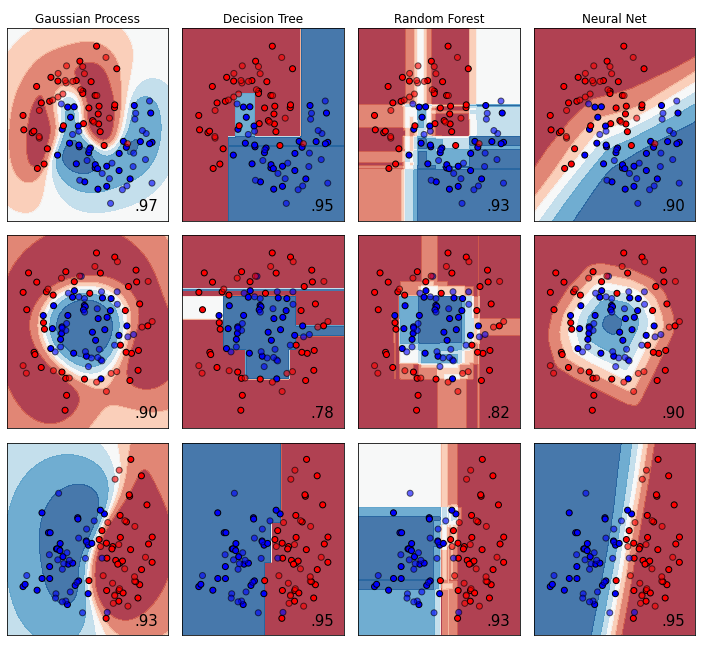
真ん中の3行4列部分
真ん中の部分に登場する4種の識別器は以下です。
-
- Gaussian Process
- Decision Tree
- Random Forest
- Neural Net
1は、略称でGPC(Gaussian process classification)などと呼ばれたりもするみたいです。知らんけど。2,3は聞いたことありますが、4は「Neural Netといってもいろいろあるやんけ!」と心の中で突っ込んだら、 Multi-layer Perceptron classifier(MLPC)と呼ばれるものみたいです。素人には知らないお言葉ばかり登場で圧倒(煙にまかれる)されます。
右側の3行3列部分
最後の3列の識別器は以下の皆さんです。
-
- AdaBoost
- Naive Bayes
- QDA
1のAdaBoostは聞いたことがありますな。2はGaussian Naive Bayes (GaussianNB)と呼ぶべきもののようです。3はQuadratic Discriminant Analysisの略。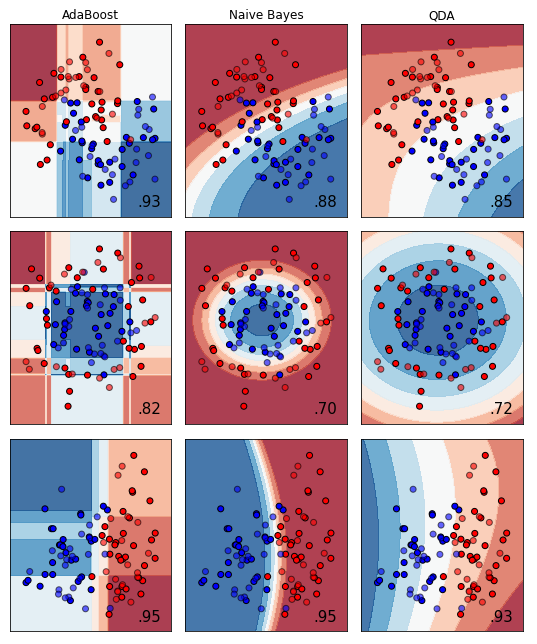
何も分かっちゃいないのですが、ソースを読み、やっている操作が何となく分かると親しみも持てる、と。ホントか?先は長そうだが。。。