SIMDの「整数変換系」まだあると思ったらFRINT32X一族はARMv8.0には存在せず。ラッキー?前回で整数変換系の練習は終わりであります。そこで次の単元?に入ったですが、今度はSIMDのMUL系、まだ練習してないことに気づきました。もっとムツカシー奴らは練習していたのにシンプルなMULやってなかったのね。。。
※「ぐだぐだ低レベルプログラミング」投稿順indexはこちら
※実機動作確認には以下を使用しております。
-
- Raspberry Pi 4 model B、Cortex-A72コア(ARMv8-A)
- Raspberry Pi OS (64bit) bullseye
- gcc (Debian 10.2.1-6) 10.2.1 20210110
ARMv8もいろいろレベルがあり、Arm Cortex-A72はARMv8の中でもベーシックな(命令数の少ない)ARMv8p0です。
※A64の最新のマニュアルは以下でダウンロード可能です。
Arm Architecture Reference Manual for A-profile architecture
前回まで練習していたSIMDの「整数変換系」最後に以下の奴らをやっつけたいとおもったら、ARMv8p0(ARMv8.0)には不在。以下が使えるのはARMv8.5以降じゃということであります。
-
- FRINT32X
- FRINT32Z
- FRINT64X
- FRINT64Z
そこで今回からSIMDのelement arithmeticに進むことになりました。
element arithmetic
今回 SIMDのMUL命令を練習いたします。今まではこんな感じでした。
MUL v0.4S, v1.4S, v2.4S
上記は、v1レジスタに入っている4つの32ビット整数とv2レジスタに入っている4つの32ビット整数をそれぞれ「レーン毎」に掛け合わせ、その結果をv0レジスタへ格納する場合の命令です。4つの要素が同時に求まりますが、それぞれの要素(レーン)は独立してました。しかし、今回から練習するelement arithmetic系の命令どもは一味違います。
MUL v0.4S, v1.4S, v2.4S[1]
上記ではv1レジスタに入っている4つの32ビット整数にv2レジスタの「第1要素」の32ビット整数を掛け合わせ、その結果をv0レジスタへ格納します。4個の要素があるけれど、第2ソースは一つの値です。[ ]の中にインデックス番号を書いておけばその要素が使われます。上記の場合4Sなので0から3のどれかね。
実際、SIMDで演算を行っていると同じ値をSIMD要素全てに作用させたい、ということはよくあると思います。element arithmetic頻出ね。
MUL、MLA、MLS
その1番手として練習するのは以下の3つです。
-
- MUL、第1ソースと第2ソースを乗じた結果をデスティネーションへ
- MLA、第1ソースと第2ソースを乗じた結果をデスティネーションと足し合わせたものをデスティネーションへ
- MLS、第1ソースと第2ソースを乗じた結果をデスティネーションから引いたものをデスティネーションへ
3種類とも、フツーのSIMD処理(レーン独立)と、element arithmeticの両方を練習していきたいと思います。
実験につかったアセンブリ言語記述の被テスト関数
例によって手抜きの関数プロローグ、エピローグ無の被テスト関数のソースが以下に。オペランドはハーフワード(16ビット)とワード(32ビット)がとれるのですが、手抜きなのでワードだけ練習してます。バイトやダブルワードが無いのは「大人の事情」(多分積和演算器の事情?)じゃないかと。知らんけど。
.globl mul4V, mul4V1, mla4V, mla4V1, mls4V, mls4V1
.text
.balign 4
mul4V:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
mul v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
mul4V1:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
mul v0.4S, v1.4S, v2.4S[1]
st1 {v0.4S}, [x0]
ret
mla4V:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
mla v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
mla4V1:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
mla v0.4S, v1.4S, v2.4S[1]
st1 {v0.4S}, [x0]
ret
mls4V:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
mls v0.4S, v1.4S, v2.4S
st1 {v0.4S}, [x0]
ret
mls4V1:
ld1 {V0.4S, v1.4S, v2.4S}, [x0]
mls v0.4S, v1.4S, v2.4S[1]
st1 {v0.4S}, [x0]
ret
C言語記述のmain関数
上記のアセンブリ言語関数を呼び出すmain関数が以下に。
#include <stdio.h>
#include <stdint.h>
#define MAXMEM (12)
uint32_t TargetMEM[MAXMEM];
extern void mul4V(uint32_t *);
extern void mul4V1(uint32_t *);
extern void mla4V(uint32_t *);
extern void mla4V1(uint32_t *);
extern void mls4V(uint32_t *);
extern void mls4V1(uint32_t *);
void initTGT() {
TargetMEM[0] = 0x00060000;
TargetMEM[1] = 0x00060000;
TargetMEM[2] = 0x00060000;
TargetMEM[3] = 0x00060000;
TargetMEM[4] = 0x00010001;
TargetMEM[5] = 0x00010002;
TargetMEM[6] = 0x00010003;
TargetMEM[7] = 0x00010004;
TargetMEM[8] = 0x00000002;
TargetMEM[9] = 0x00000003;
TargetMEM[10] = 0x00000004;
TargetMEM[11] = 0x00000005;
}
void dumpTGT(const char *arg) {
printf("%s\n", arg);
for (int i=0; i < 4; i++) {
printf("%02d: 0x%08x opr 0x%08x -> 0x%08x\n", i, TargetMEM[i+4], TargetMEM[i+8], TargetMEM[i]);
}
}
void dumpTGT1(const char *arg, const int idx) {
printf("%s\n", arg);
for (int i=0; i < 4; i++) {
printf("%02d: 0x%08x opr 0x%08x -> 0x%08x\n", i, TargetMEM[i+4], TargetMEM[idx+8], TargetMEM[i]);
}
}
int main(void) {
initTGT();
mul4V(TargetMEM);
dumpTGT("mul");
initTGT();
mul4V1(TargetMEM);
dumpTGT1("mul [1]", 1);
initTGT();
mla4V(TargetMEM);
dumpTGT("mla");
initTGT();
mla4V1(TargetMEM);
dumpTGT1("mla [1]", 1);
initTGT();
mls4V(TargetMEM);
dumpTGT("mls");
initTGT();
mls4V1(TargetMEM);
dumpTGT1("mls [1]", 1);
return 0;
}
実機実行結果の確認
以下のようにしてビルドして実行しています。
$ gcc -g -O0 simdMUL.c simdMUL.s $ ./a.out
結果が以下に。
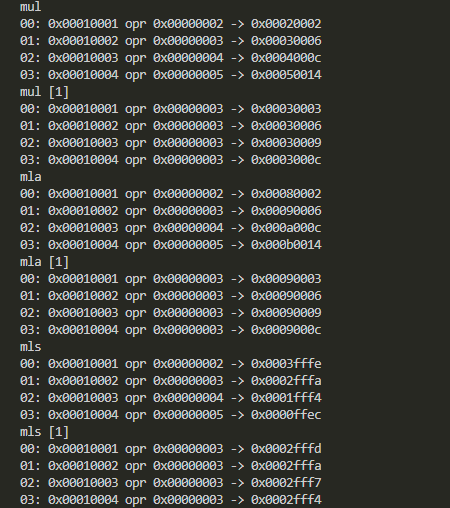
予定通りの結果のようだね。あたりまえか。